
NHANES Data is a Treasure Trove for Biomedical Research
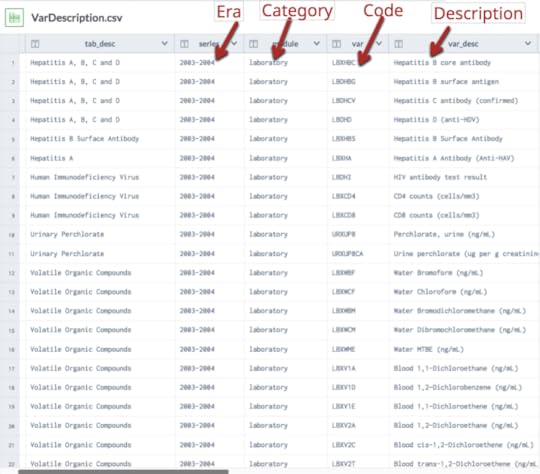
National Health & Nutrition Evaluation Survey (NHANES) is a program of the National Center for Health Statistics (NCHS), which is a a CDC program. The survey has existed since the 1960s and since 1999 has been continuous. About 5000 patients a year are surveyed and examined in detail and that includes extensive lab testing. The data and codebooks (data dictionaries) are free to access. This is important because obtaining real patient data at the patient level tends to be difficult due to HIPAA and is expensive to buy. There is a longitudinal project under way of 800 patients from the 2007-2014 cohorts that is not available yet, to the best of my knowledge.NHANES data is valuable for several reasons. It tends to represent a more “normal” US sample of patients. For example, more are college educated. NHANES data is frequently used for observational and benchmarking studies (compare another population and/or result with NHANES dataset). It is also good for hypothesis testing. NHANES data has been used for research for many years. For example, a Google Scholar search for NHANES in the title yielded more than 5,000 hits and a PubMed search turned up over 9,800 hits. Another advantage of NHANES data is that it is associated with extensive data dictionaries. These dictionaries explain exactly how the data was collected, what units, how many patients were examined and so forth. Importantly, the dictionaries also include the short hand name of the attribute which you must have to locate and analyze the data. For example, glycohemoglobin or A1c is coded LBXGH. A researcher would need to know that for a SQL query. NHANES data does have some limitations however:•Patient data is cross sectional and not longitudinal •Diagnoses is derived from patient questionnaires but in my experience, the results are very accurate. For example, 98% of patients who claimed they were diabetic had abnormal glucoses or glycohemoglobin or were on glucose lowering medications•Some lab tests are not done every year, so accessing multiple years is important• NHANES uses sampling weights that must be understood•Data files are available as SAS transport files; they need to be converted to csv filesThere is a new NHANES dataset that was created by Harvard University that combines 4 NHANES periods (1999-2006) so there is a single spreadsheet with 1191 attributes on 41,474 patients. The project was part of the i2B2 Initiative and is a public dataset. There is an article by CJ Patel et al. in Nature that explains how this was done and the significance of this initiative. This article introduces the concept of the exposome, in addition to phenotype. There is also an associated video. There are 3 ways you can access this large NHANES dataset:•Data Dryad(data repository) Files: Maintable (large spreadsheet), VarDescription (data dictionary)•Harvard Data Explorer•Data World. Project name = NHANES Compilation.Harvard Data Explorer Gallery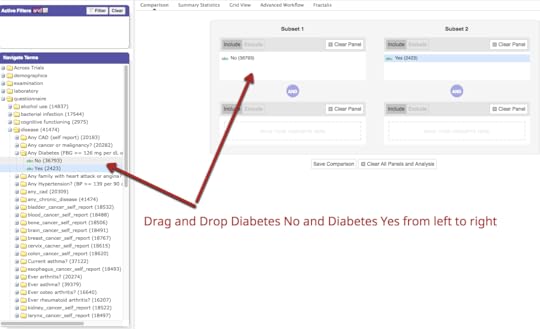
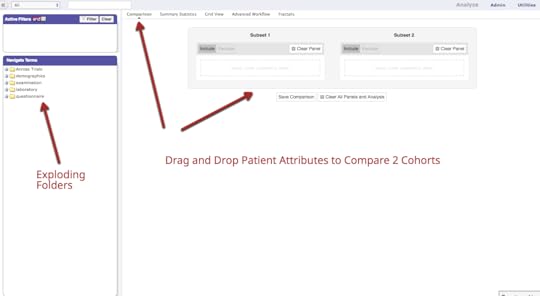
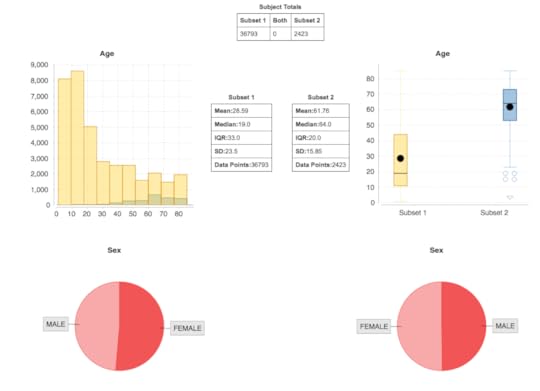

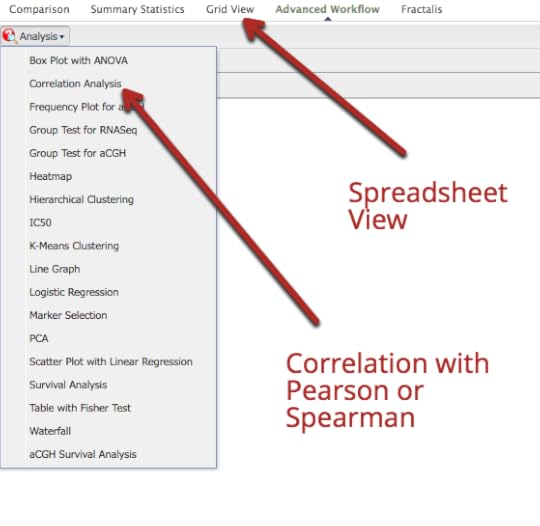
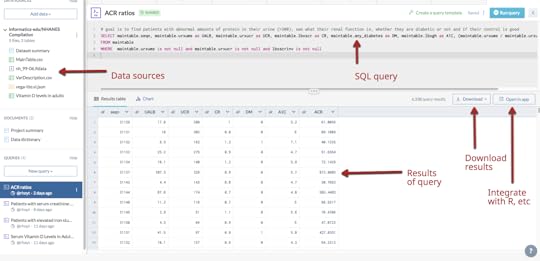
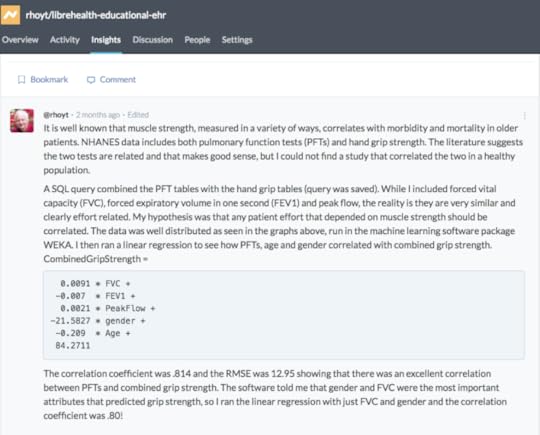
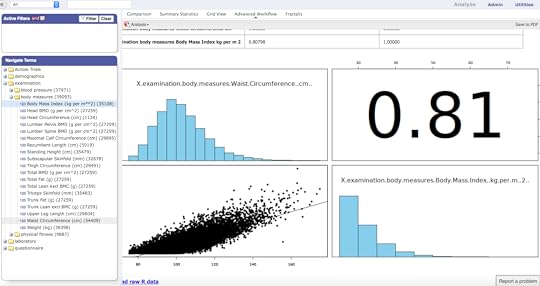 My assessment is that the Harvard Data Explorer works very well for cohort comparison and the generation of descriptive and visual statistics. My experience with the advanced workflow tools was not very good due to the process timing out. In addition, there is not a very good user guideData World (DW) is an open and collaborative data science platform, new since 2016. It is free for academic use and an application can be found at this site. How to set up a classroom is explained here. Data World has more than 16000 datasets; 3500 are health related. There is a robust search engine that is Boolean-based, plus the ability to search spreadsheet attributes. In August 2018, DW announced users can link Data World to Canvas Learning Management System. The overarching goal of DW is to create data science projects, so users can visualize and analyze datasets with internal and external analytical tools and collaborate with others. The projects can be private or public projects. SQL and SPARQL are embedded in DW and have tutorials that are user friendly. Data set exercises are also included. DW is integrated with R and Python languages. It also integrates with Tableau and several other visualization tools. SQL queries can be saved and shared. Spreadsheet tools, like Excel, include simple visualizations and information about the attributes. Outcomes can be posted as “Insights” with explanations as to how the outcomes were achieved, similar to Jupyter Notebooks.Two projects were created: •Project #1(LibreHealth Educational EHR): Analyze data associated with 9600 patients from NHANES 2011-2012 that was also used to populate an open source EHR. Review the Insights•Project #2 (NHANES Compilation): Analyze 41,000+ patients using the same dataset used for the Harvard Data Explorer. Review the Insights. Data World Gallery
My assessment is that the Harvard Data Explorer works very well for cohort comparison and the generation of descriptive and visual statistics. My experience with the advanced workflow tools was not very good due to the process timing out. In addition, there is not a very good user guideData World (DW) is an open and collaborative data science platform, new since 2016. It is free for academic use and an application can be found at this site. How to set up a classroom is explained here. Data World has more than 16000 datasets; 3500 are health related. There is a robust search engine that is Boolean-based, plus the ability to search spreadsheet attributes. In August 2018, DW announced users can link Data World to Canvas Learning Management System. The overarching goal of DW is to create data science projects, so users can visualize and analyze datasets with internal and external analytical tools and collaborate with others. The projects can be private or public projects. SQL and SPARQL are embedded in DW and have tutorials that are user friendly. Data set exercises are also included. DW is integrated with R and Python languages. It also integrates with Tableau and several other visualization tools. SQL queries can be saved and shared. Spreadsheet tools, like Excel, include simple visualizations and information about the attributes. Outcomes can be posted as “Insights” with explanations as to how the outcomes were achieved, similar to Jupyter Notebooks.Two projects were created: •Project #1(LibreHealth Educational EHR): Analyze data associated with 9600 patients from NHANES 2011-2012 that was also used to populate an open source EHR. Review the Insights•Project #2 (NHANES Compilation): Analyze 41,000+ patients using the same dataset used for the Harvard Data Explorer. Review the Insights. Data World Gallery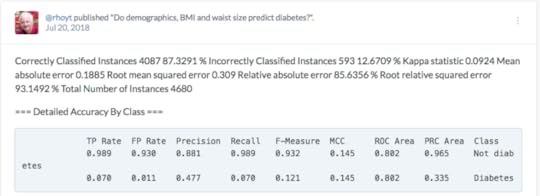
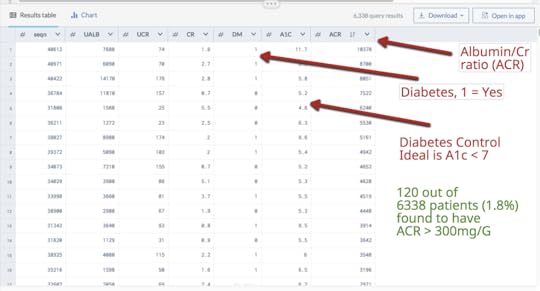 Conclusions:•Biomedical researchers should have access to “real world” datasets•Data should be at the patient level•Students need affordable analytics tools and data platforms to practice and manipulate data•Large robust datasets can be used to generate research and publications
Conclusions:•Biomedical researchers should have access to “real world” datasets•Data should be at the patient level•Students need affordable analytics tools and data platforms to practice and manipulate data•Large robust datasets can be used to generate research and publications
My assessment is that the Harvard Data Explorer works very well for cohort comparison and the generation of descriptive and visual statistics. My experience with the advanced workflow tools was not very good due to the process timing out. In addition, there is not a very good user guideData World (DW) is an open and collaborative data science platform, new since 2016. It is free for academic use and an application can be found at this site. How to set up a classroom is explained here. Data World has more than 16000 datasets; 3500 are health related. There is a robust search engine that is Boolean-based, plus the ability to search spreadsheet attributes. In August 2018, DW announced users can link Data World to Canvas Learning Management System. The overarching goal of DW is to create data science projects, so users can visualize and analyze datasets with internal and external analytical tools and collaborate with others. The projects can be private or public projects. SQL and SPARQL are embedded in DW and have tutorials that are user friendly. Data set exercises are also included. DW is integrated with R and Python languages. It also integrates with Tableau and several other visualization tools. SQL queries can be saved and shared. Spreadsheet tools, like Excel, include simple visualizations and information about the attributes. Outcomes can be posted as “Insights” with explanations as to how the outcomes were achieved, similar to Jupyter Notebooks.Two projects were created: •Project #1(LibreHealth Educational EHR): Analyze data associated with 9600 patients from NHANES 2011-2012 that was also used to populate an open source EHR. Review the Insights•Project #2 (NHANES Compilation): Analyze 41,000+ patients using the same dataset used for the Harvard Data Explorer. Review the Insights. Data World GalleryConclusions:•Biomedical researchers should have access to “real world” datasets•Data should be at the patient level•Students need affordable analytics tools and data platforms to practice and manipulate data•Large robust datasets can be used to generate research and publications


No comments have been added yet.


