
Jeremy Howard's Blog
September 5, 2022
My family's unlikely homeschooling journey
My husband Jeremy and I never intended to homeschool, and yet we have now, unexpectedly, committed to homeschooling long-term. Prior to the pandemic, we both worked full-time in careers that we loved and found meaningful, and we sent our daughter to a full-day Montessori school. Although I struggled with significant health issues, I felt unbelievably lucky and fulfilled in both my family life and my professional life. The pandemic upended my careful balance. Every family is different, with different needs, circumstances, and constraints, and what works for one may not work for others. My intention here is primarily to share the journey of my own (very privileged) family.
 Our unplanned introduction to homeschooling
Our unplanned introduction to homeschoolingFor the first year of the pandemic, most schools in California, where we lived at the time, were closed. Like countless other families, we were unexpectedly thrust into the world of virtual-school and home-school. We ended up participating in an innovative online program that did NOT try to replicate in-person school. A few key differences:
Each child could work at their own pace, largely through playing educational games and apps that adapted to where they were. There was no particular endpoint that the kids needed to get to at the end of the semester. Group video calls were limited in size to no more than 6 kids (and often smaller), so kids got lots of personal interaction with their tutors and each other. Even as an adult, I find video calls larger than 6 people overwhelming. Regular movement breaks, where the kids had jumping jack competitions, did Cosmic Kids yoga videos, held dance parties, and ran around the house for scavenger hunts. Took advantage of existing materials: the program did not reinvent the wheel, but instead made use of excellent, existing online videos and educational apps.From August 2020 - March 2021, our daughter was with a small group online, where daily she would spend 1 hour on socio-emotional development (including games, getting to know each other, and discussing feelings), 1 hour on reading, and 1 hour on math. For reading and math, the children each worked at their own pace through engaging games, and could ask the teacher and each other questions whenever they needed help. At the end of these 8 months, our daughter, along with several other kids in her small group, were several years beyond their age levels in both math and reading. It had never been our goal for her to end up accelerated; Jeremy and I were mostly trying to keep her happy and busy for a few hours so we could get some of our own work done. She also had fun and made close friends, who she continues to have video calls and Minecraft virtual playdates with regularly.
Our unconventional viewsAlthough there are plenty of ways to homeschool that don���t involve any screens or technology, Jeremy and I have made use of online tutors, long-distance friendships, educational apps, videos, and web-based games, as key parts of our approach. One thing that helped us going into the pandemic is that we have never treated online/long-distance relationships as inferior to in-person relationships. We both have meaningful friendships that occur primarily, or even entirely, through phone calls, video chats, texts, and online interactions. I have made several big moves since I graduated from high school (moving from Texas to Pennsylvania to North Carolina back to Pennsylvania again and then to California) and I was used to family and close friends being long distance. We live far from our families, and our daughter was already accustomed to chatting with her grandparents on both sides via video calls. My daughter���s best friend is now a child she has never met in person, but has been skyping with almost daily for the last 2 years.
Another thing that made this transition easier is that Jeremy and I have never been anti-screen time. In fact, we don���t consider ���screen time��� a useful category, since a child passively watching a movie alone is different than skyping with their grandparent is different than playing an educational game interactively with their parent beside them. While we almost never let our daughter do things passively and alone with screens, we enjoy relational and educational screen time. Furthermore, we focus on including other positive life elements (e.g. making sure she is getting enough time outside, being physically active, reading, getting enough sleep, etc) rather than emphasising limits.
 A Venn Diagram showing how I think about screentime. We avoid the outside (white) region and mostly stick to the intersections. A return to in-person school
A Venn Diagram showing how I think about screentime. We avoid the outside (white) region and mostly stick to the intersections. A return to in-person schoolIn 2021, our family immigrated from the USA to my husband���s home country of Australia, and we enrolled our daughter at an in-person school, which she attended from late April - early Dec 2021. Our state had closed borders and almost no cases of covid transmission during this time. By all measures, the school she attended is great: friendly families, kind staff, and a fun performing arts program. While our daughter adjusted quickly to the new environment and made friends, she was quite bored. She lost her previous curiosity and enthusiasm, became more passive, and started to spend a lot of time zoning out. The school tried to accommodate her, letting her join an older grade level for math each day. While the material was initially new, she still found the pace too slow. She started to get very upset at home practising piano or playing chess (activities she previously loved, but where mistakes are inevitable), because she had grown accustomed to getting everything right without trying. At one point, all schools in our region closed during an 8-day snap lockdown. Our daughter was disappointed when the lockdown ended and she had to return to school.
When homeschooling works well (and when it doesn���t)Over the summer holidays (Dec 2021-Jan 2022), our state pivoted from zero covid to promoting mass infection as ���necessary���. We pulled our daughter out of school, initially intending that it would just be a temporary measure until her age group could be fully vaccinated (vaccine rollout was later in Australia than in the USA). However, we immediately saw positive changes, with her regaining her old curiosity, enthusiasm, and proactive nature, all of which she had lost being in school. Her perfectionism disappeared and she began to enjoy challenges again. We supplemented her online classes with in-person playdates, extracurriculars, and sports (due to covid risks, we wear masks and stay outdoors for all of these). We are fortunate to live in a beautiful part of the world, where we can spend most of the year outside. We enjoy visiting the beaches, forests, and parks in our region. Our daughter is happy: playing Minecraft with friends online, learning tennis with other local children, riding bikes as a family, spending hours absorbed in books of her own choosing, enjoying piano and chess again, running around in nature, and learning at her own pace.
Homeschooled kids typically score 15 to 30 percentile points above public-school students on standardised academic achievement tests, and 87% of studies on social development ���showed clearly positive outcomes for the homeschooled compared to those in conventional schools���. However, it is understandable that many children had negative experiences with virtual learning in the past 2 years, given that programs were often hastily thrown together with inadequate resources and inappropriately structured to try to mimic in-person school, against the stressful backdrop of a global pandemic. Many parents faced the impossible task of simultaneously needing to work full-time and help their children full-time (and many other parents did not even have the option to stay home). Every family is different, and virtual learning or homeschooling will not suit everyone. There are children who need in-person services only offered within schools; parents whose work constraints don���t allow for it; and kids who thrive being with tons of other kids.
Despite the difficulty of the pandemic, there are a variety of families who found that virtual or homeschooling was better for their particular kids. Some parents have shared about children with ADHD who found in-person school too distracting; children who were facing bullying or violence at school; kids who couldn���t get enough sleep on a traditional school schedule; Black and Latino families whose cultural heritages were not being reflected in curriculums. I enjoyed these article featuring a few such families:
What if Some Kids Are Better Off at Home? | The New York TimesFor parents like me, the pandemic has come with a revelation: For our children, school was torture. They Rage-Quit the School System���and They���re Not Going Back | WIREDThe pandemic created a new, more diverse, more connected crop of homeschoolers. They could help shape what learning looks like for everyone.Covid RisksI have had brain surgery twice, was hospitalised in the ICU with a life-threatening brain infection, and have a number of chronic health issues. I am both at higher risk for negative outcomes from covid AND acutely aware of how losing your health can destroy your life. It is lonely and difficult being high-risk in a society that has given up on protecting others. While I am nervous about the long-term impact that homeschooling will have on my career (on top of how my existing health issues already hinder it), acquiring additional disabilities would be far, far worse.
I have been disturbed to follow the ever-accumulating research on cardiovascular, neurological, and immune system harms that can be caused by covid, even in previously healthy people, even in the vaccinated, and even in children. While vaccines significantly reduce risk of death, unfortunately they provide only a limited reduction in Long Covid risk. Immunity wanes, and people face cumulative risks with each new covid infection (so even if you���ve had covid once or twice, it is best to try to avoid reinfections). I am alarmed that leaders are encouraging mass, repeated infections of a generation of children.
Given all this, I am relieved that our decision to continue homeschooling was relatively clear. It much better suits our daughter���s needs AND drastically reduces our family���s covid risk. We can nurture her innate curiosity, protect her intrinsic motivation, and provide in-person social options that are entirely outdoors and safer than being indoors all day at school. Most families are not so fortunate and many face difficult choices, with no good options.
The Broader PictureI believe that high-quality, equitable, and safe public education is important for a healthy democracy, and I worry about the various ongoing ways in which education is being undermined and attacked. Furthermore, due to a lack of covid protections in communities, high-risk children and children with high-risk families are being shut out of in-person school options in the USA, Australia, and many other places. While the workplaces of politicians and a handful of schools in ultra-wealthy areas installed expensive ventilation upgrades, the majority of schools in the USA and Australia have not had any ventilation upgrades, nor received air purifiers. All children deserve access to an education that is safe, fits their needs, and will allow them to thrive. Even when homeschooling does work, it is often still just an individual solution to systemic problems.
Related PostsA few other posts that you may be interested in, related to my views on education and teaching:
There���s No Such Thing as Not A Math Person: based on a webinar I gave to parents addressing cultural myths about math and how to support your kids in their math education, even if you don���t see yourself as a ���math person��� The Qualities of a Good Education: common pitfalls in traditional technical education and ideas towards doing better What You Need to Know Before Considering a PhD: includes a reflection on how my own success in traditional academic environments was actually a weakness, because I���d learned how to solve problems I was given, but not how to how to find and scope interesting problems on my own

August 24, 2022
The Jupyter+git problem is now solved
Contents The Jupyter+git problem The solution The nbdev2 git merge driver The nbdev2 Jupyter save hook Background The result Postscript: other Jupyter+git tools ReviewNB An alternative solution: Jupytext nbdime The Jupyter+git problemJupyter notebooks don���t work with git by default. With nbdev2, the Jupyter+git problem has been totally solved. It provides a set of hooks which provide clean git diffs, solve most git conflicts automatically, and ensure that any remaining conflicts can be resolved entirely within the standard Jupyter notebook environment. To get started, follow the directions on Git-friendly Jupyter.
Jupyter notebooks are a powerful tool for scientists, engineers, technical writers, students, teachers, and more. They provide an ideal notebook environment for interactively exploring data and code, writing programs, and documenting the results as dashboards, books, or blogs.
But when collaborating with others, this ideal environment goes up in smoke. That���s because tools such as git, which are the most popular approaches for asynchronous collaboration, makes notebooks unusable. Literally. Here���s what it looks like if you and a colleague both modify a notebook cell (including, in many cases, simply executing a cell withuout changing it), and then try to open that notebook later:

The reason for this stems from a fundamental incompatibility between the format Jupyter notebooks use (JSON) and the format that git conflict markers assume by default (plain lines of text). This is what it looks like when git adds its conflict markers to a notebook:
"source": [<<<<<< HEAD "z=3\n",====== "z=2\n",>>>>>> a7ec1b0bfb8e23b05fd0a2e6cafcb41cd0fb1c35 "z" ]That���s not valid JSON, and therefore Jupyter can���t open it. Conflicts are particularly common in notebooks, because Jupyter changes the following every time you run a notebook:
Every cell includes a number indicating what order it was run in. If you and a colleague run the cells in different orders, you���ll have a conflict in every single cell! This would take a very long time to fix manually For every figure, such as a plot, Jupyter includes not only the image itself in the notebook, but also a plain text description that includes the id (like a memory address) of the object, such as <matplotlib.axes._subplots.AxesSubplot at 0x7fbc113dbe90>. This changes every time you execute a notebook, and therefore will create a conflict every time two people execute this cell Some outputs may be non-deterministic, such as a notebook that uses random numbers, or that interacts with a service that provides different outputs over time (such as a weather service) Jupyter adds metadata to the notebook describing the environment it was last run in, such as the name of the kernel. This often varies across installations, and therefore two people saving a notebook (even without and other changes) will often end up with a conflict in the metadata.All these changes to notebook files also make git diffs of notebooks very verbose. This can make code reviews a challenge, and make git repos more bulky than necessary.
The result of these problems is that many Jupyter users feel that collaborating with notebooks is a clunky, error-prone, and frustrating experience. (We���ve even seen people on social media describe Jupyter���s notebook format as ���stupid��� or ���terrible���, despite otherwise professing their love for the software!)
It turns out, however, that Jupyter and git can work together extremely well, with none of the above problems at all. All that���s needed is a bit of special software���
The solutionJupyter and git are both well-designed software systems that provide many powerful extensibility mechanisms. It turns out that we can use these to fully and automatically solve the Jupyter+git problem. We identified two categories of problems in the previous section:
git conflicts lead to broken notebooks Unnecessary conflicts due to metadata and outputs.In our newly released nbdev2, an open source Jupyter-based development platform, we���ve solve each of the problems:
A new merge driver for git provides ���notebook-native��� conflict markers, resulting in notebooks that can be opened directly in Jupyter, even when there are git conflicts A new save hook for Jupyter automatically removes all unnecessary metadata and non-deterministic cell output.Here���s what a conflict looks like in Jupyter with nbdev���s merge driver:

As you see, the local and remote change are each clearly displayed as separate cells in the notebook, allowing you to simply delete the version you don���t want to keep, or combine the two cells as needed.
The techniques used to make the merge driver work are quite fascinating ��� let���s dive into the details!
The nbdev2 git merge driverWe provide here a summary of the git merge driver ��� for full details and source code see the nbdev.merge docs. Amazingly enough, the entire implementation is just 58 lines of code!
The basic idea is to first ���undo��� the original git merge which created the conflict, and then ���redo��� it at a cell level (instead of a line level) and looking only at cell source (not outputs or metadata). The ���undoing��� is straightforward: just create two copies of the conflicted file (representing the local and remove versions of the file), go through each git conflict marker, and replace the conflict section with either the local or remote version of the code.
Now that we���ve got the original local and remote notebooks, we can load the json using execnb.nbio, which will then give us an array of cells for each notebook. Now we���re up to the interesting bit ��� creating cell-level diffs based only on the cell source.
The Python standard library contains a very flexible and effective implementation of a diff algorithm in the difflib module. In particular, the SequenceMatcher class provides the fundamental building blocks for implementing your own conflict resolution system. We pass the two sets of cells (remote and local) to SequenceMatcher(...).get_matching_blocks(), and it returns a list of each section of cells that match (i.e. have no conflicts/differences). We can then go through each matching section and copy them into the final notebook, and through each non-matching section and copy in each of the remote and local cells (add cells between them to mark the conflicts).
Making SequenceMatcher work with notebook cells (represented in nbdev by the NbCell class) requires only adding __hash__ and __eq__ methods to NbCell. In each case, these methods are defined to look only at the actual source code, and not at any metadata or outputs. As a result, SequenceMatcher will only show differences in source code, and will ignore differences in everything else.
With a single line of configuration, we can ask git to call our python script, instead of its default line-based implementation, any time it is merging changes. nbdev_install_hooks sets up this configuration automatically, so after running it, git conflicts become much less common, and never result in broken notebooks.
The nbdev2 Jupyter save hookSolving git merges locally is extremely helpful, but we need to solve them remotely as well. For instance, if a contributor submits a pull request (PR), and then someone else commits to the same notebook before the PR is merged, the PR might now have a conflict like this:
"outputs": [ {<<<<<< HEAD "execution_count": 7,====== "execution_count": 5,>>>>>> a7ec1b0bfb8e23b05fd0a2e6cafcb41cd0fb1c35 "metadata": {},This conflict shows that the two contributors have run cells in different orders (or perhaps one added a couple of cells above in the notebook), so their commits have conflicting execution counts. GitHub will refuse to allow this PR to be merged until this conflict is fixed.
But of course we don���t really care about the conflict at all ��� it doesn���t matter what, if any, execution count is stored in the notebook. So we���d really prefer to ignore this difference entirely!
Thankfully, Jupyter provides a ���pre-save��� hook which allows code to be run every time a notebook is saved. nbdev uses this to set up a hook which removes all unnecessary metadata (including execution_count) on saving. That means there���s no pointless conflicts like the one above, because no commits will have this information stored in the first place.
BackgroundHere at fast.ai we use Jupyter for everything. All our tests, documentation, and module source code for all of our many libraries is entirely developed in notebooks (using nbdev, of course!) And we use git for all our libraries too. Some of our repositories have many hundreds of contributors. Therefore solving the Jupyter+git problem has been critical for us. The solution presented here is the result of years of work by many people.
Our first approach, developed by Stas Bekman and me, was to use git ���smudge��� and ���clean��� filters that automatically rewrote all notebook json to remove unneeded metadata when committing. This helped a bit, but git quite often ended up in an odd state where it was impossible to merge.
In nbdev v1 Sylvain Gugger created an amazing tool called nbdev_fix_merge which used very clever custom logic to manually fix merge conflicts in notebooks, to ensure that they could opened in Jupyter. For nbdev v2 I did a from-scratch rewrite of every part of the library, and I realised that we could replace the custom logic with the SequenceMatcher approach described above.
None of these steps fully resolved the Jupyter+git problem, since we were getting frequent merge errors caused by the smudge/clean git filters, and conflicts required manually running nbdev_fix_merge. Wasim Lorgat realised that we could resolve the smudge/clean issue by moving that logic into an nbdev save hook, and avoid the manual fix step by moving that logic into a git merge driver. This resolved the final remaining issues! (I was actually quite stunned that Wasim went from our first discussion of the outstanding problems, to figuring out how to solve all of them, in the space of about two days���)
The resultThe new tools in nbdev2, which we���ve been using internally for the last few months, have been transformational to our workflow. The Jupyter+git problem has been totally solved. I���ve seen no unnecessary conflicts, cell-level merges have worked like magic, and on the few occassions where I���ve changed the source in the same cell as a collaborator, fixing the conflict in Jupyter has been straightforward and convenient.
Postscript: other Jupyter+git toolsReviewNBThere is one other tool which we���ve found very helpful in using Jupyter with git, which is ReviewNB. ReviewNB solves the problem of doing pull requests with notebooks. GitHub���s code review GUI only works well for line-based file formats, such as plain python scripts. This works fine with the Python modules that nbdev exports, and I often do reviews directly on the Python files, instead of the source notebooks.
However, much of the time I���d rather do reviews on the source notebooks, because:
I want to review the documentation and tests, not just the implementation I want to see the changes to cell outputs, such as charts and tables, not just the code.For this purpose, ReviewNB is perfect. Just like nbdev makes git merges and commits Jupyter-friendly, ReviewNB makes code reviews Jupyter-friendly. A picture is worth a thousand words, so rather than trying to explain, I���ll just show this picture from the ReviewNB website of what PRs look like in their interface:
Another potential solution to the Jupyter+git problem might be to use Jupytext. Jupytext saves notebooks in a line-based format, instead of in JSON. This means that all the usual git machinery, such as merges and PRs, works fine. Jupytext can even use Quarto���s format, qmd, as a format for saving notebooks, which then can be used to generate a website.
Jupytext can be a bit tricky to manage when you want to save your cell outputs (which I generally want to do, since many of my notebooks take a long time to run ��� e.g training deep learning models.) Whilst Jupytext can save outputs in a linked ipynb file, managing this linkage gets complex, and ends up with the Jupyter+git problem all over again! If you don���t need to save outputs, then you might find Jupytext sufficient ��� although of course you���ll miss out on the cell-based code reviews of ReviewNB and your users won���t be able to read your notebooks properly when they���re browsing GitHub.
nbdimeThere���s also an interesting project called nbdime which has its own git drivers and filters. Since they���re not really compatible with nbdev (partly because they tackle some of the same problems in different ways) I haven���t used them much, so haven���t got an informed opinion about them. However I do use nbdime���s Jupyter extension sometimes, which provides a view similar to ReviewNB, but for local changes instead of PRs.
If you want to try to yourself, follow the directions on Git-friendly Jupyter to get started.
July 27, 2022
nbdev+Quarto: A new secret weapon for productivity
Today we���re excited to announce that we���ve teamed up with Quarto to give nbdev superpowers. nbdev offers Python programmers a common set of tools for using Jupyter notebooks to:
Write & distribute software packages Test code, and Author documentation and technical articlesAlthough notebooks are already widely used for once-off exploratory work, it���s less well-known that they are perfectly capable of writing quality software. In fact, we���ve used nbdev for a wide range of software projects over the last three years, including deep learning libraries, API clients, Python language extensions, terminal user interfaces, and more. We discovered that it is not only capable of writing great software but that it has also increased our productivity by 300% or more. With nbdev, developers simply write notebooks with lightweight markup and get high-quality documentation, tests, continuous integration, and packaging for free! Nbdev has allowed us to maintain and scale many open source projects. Pull requests are often accompanied by detailed documentation and tests���contributors simply write notebooks.
This is why we���re excited to share nbdev v2. It���s rewritten from the ground up, with much-anticipated features including:
Interoperation with non-nbdev codebases for tasks like documentation Support for any static site generator Wide variety of output mediums such as blogs, papers, slides, and websites A faster Jupyter kernel, which also means faster tests Cleaner and more extensible API, which supports custom directives, custom module exporters, and more nbdev in industry
nbdev in industryWe have piloted nbdev at several companies. We were delighted to receive the following feedback, which fits our own experience using and developing nbdev:

David Berg, on using nbdev for internal documentation at Netflix: ���Prior to using nbdev, documentation was the most cumbersome aspect of our software development process��� Using nbdev allows us to spend more time creating rich prose around the many code snippets guaranteeing the whole experience is robust. nbdev has turned what was once a chore into a natural extension of the notebook-based testing we were already doing.���

Erik Gaasedelen, on using nbdev in production at Lyft: ���I use this in production at my company. It���s an awesome tool��� nbdev streamlines everything so I can write docs, tests, and code all in one place��� The packaging is also really well thought out. From my point of view it is close to a Pareto improvement over traditional Python library development.���
Hugo Bowne-Anderson, on using nbdev for Outerbounds: ���nbdev has transformed the way we write documentation. Gone are the days of worrying about broken code examples when our API changes or [due to] human errors associated with copying & pasting code into markdown files. The authoring experience of nbdev��� [allows] us to write prose and live code in a unified interface, which allows more experimentation��� On top of this, nbdev allows us to include unit tests in our documentation which mitigates the burden of maintaining the docs over time.���

What���s nbdev?Roxanna Pourzand, on using nbdev for Transform: ���We���re so excited about using nbdev. Our product is technical so our resulting documentation includes a lot of code-based examples. Before nbdev, we had no way of maintaining our code examples and ensuring that it was up-to-date for both command inputs and outputs. It was all manual. With nbdev, we now have this under control in a sustainable way. Since we���ve deployed these docs, we also had a situation where we were able to identify a bug in one of our interfaces, which we found by seeing the error that was output in the documentation.���
Nbdev embraces the dynamic nature of python and REPL-driven development in ways that traditional IDEs and software development workflows cannot. We thoroughly discussed the motivation, history, and goals of nbdev in this initial launch post three years ago. The creator of Jupyter, Fernando P��rez, told us:
[Nbdev] should be celebrated and used a lot more - I have kept a tab with your original nbdev blog post open for months in Chrome because of how often I refer to it and point others to this work
In short, nbdev embraces ideas from literate programming and exploratory programming. These paradigms have been revisited in platforms like XCode Playgrounds and languages like Smalltalk, LISP, and Mathematica. With nbdev, we sought to push these paradigms even further by enabling it for one of the most popular dynamic programming languages in the world: Python.
 State of the Octoverse 2021, GitHub
State of the Octoverse 2021, GitHub Even though nbdev is most widely used in scientific computing communities due to its integration with Jupyter Notebooks, we���ve found that nbdev is well suited for a much wider range of software. We have used nbdev to write deep learning libraries, API clients, python language extensions,terminal user interfaces, and more!
Hamel: When I use nbdev, my colleagues are often astounded by how quickly I can create and distribute high-quality python packages. I consider nbdev to be a superpower that allows me to create tests and documentation without any additional friction, which makes all of my projects more maintainable. I also find writing software with nbdev to be more fun and productive as I can iterate very fast on ideas relative to more traditional software engineering workflows. Lastly, with nbdev I can also use traditional text-based IDEs if I want to, so I get the best of both worlds.
What we learned after three years of using nbdevWhile nbdev was originally developed to simplify the software development workflow for various fast.ai projects, we found that users wanted to extend nbdev to:
Write and publish blog posts, books, papers, and other types of documents with Jupyter Notebooks Document existing codebases not written in nbdev Accommodate traditional Python conventions���for those constrained in how their code is organized and formatted Publish content using any static site generatorWhile we created projects such as fastpages and fastdoc to accomplish some of these tasks, we realized that it would be better to have a single set of flexible tools to accomplish all of them. To this end, we were extremely excited to discover Quarto, an open-source technical publishing system built on pandoc.
Hamel: The more I used nbdev for creating Python modules, the more I wanted to use it for writing blogs and documenting existing codebases. The ability to customize the way notebooks are rendered (hiding vs. showing cells, stripping output, etc.), along with the facilities for including unit tests, made it my go-to authoring tool for all technical content. I���m excited that nbdev2 unlocks all of these possibilities for everyone!
Enter Quarto: A pandoc super-processorQuarto is a project that enables technical publishing with support for Jupyter Notebook, VSCode, Observable, and plaintext editors. Furthermore, Quarto enables the publishing of high-quality articles, reports, websites, and blogs in HTML, PDF, ePub, PowerPoint slides, and more. Quarto is maintained by RStudio, a company with a long history of products supporting literate programming, such as RMarkdown and RStudio.
Quarto is built on top of Pandoc, a universal document converter that supports nearly any format you can think of. Pandoc achieves this seemingly magical feat by representing documents in a common abstract syntax tree (AST) that serves as the medium through which different formats can be translated. By extension, Quarto allows you to generate content in almost any format you wish! You can use pandoc filters to modify the AST and the output format, which allows you to use any static site generator you want, and programmatically modify and generate content.
Quarto allows you to compose pandoc filters in a processing pipeline and apply them to specific documents or entire projects. You can also distribute filters as Quarto extensions, which makes Quarto extremely customizable.
We also find Quarto compelling because user interfaces such as comment directives (comments that start with #|) correlate with nbdev. In fact, we even learned that nbdev inspired Quarto in this regard! In general, Quarto and nbdev share many goals, and the Quarto team has been incredibly responsive to our suggestions. For example, the ability to create notebook filters to modify notebooks before rendering. Below is a screenshot of a Jupyter notebook rendered with Quarto and nbdev.
 Quarto rendering a Jupyter notebook written with nbdev
Quarto rendering a Jupyter notebook written with nbdev Finally, Quarto supports more programming languages than just Python and has been adding new features and fixing bugs at an impressive speed. This gives us confidence that we will be able to expand nbdev to support more use cases in the future. We discuss some of these future directions in the closing section.
A blazing fast notebook kernel: execnbA core component of nbdev is executing and testing notebooks programmatically. It is important that this notebook runner executes with minimal overhead to maintain our goal of providing a delightful developer experience. This is why we built execnb, a lightweight notebook runner for Python kernels, which executes notebooks blazingly fast. Furthermore, execnb allows parameterized execution of notebooks.
Hamel: I have been an enthusiastic user of tools like papermill that programmatically run notebooks for use-cases like creating dashboards or enabling new kinds of machine learning workflows. I believe execnb unlocks even more possibilities with its ability to inject arbitrary code at any place in a notebook, as well as the ability to pass callbacks that run before and/or after cells are executed. This opens up possibilities to create new types of workflows with notebooks that I am excited about exploring in the near future.
Towards a dialect of python that embraces its dynamic natureOne way to understand nbdev is part of an ecosystem that is designed to embrace Python���s dynamic properties for REPL-driven software engineering. Similar to Clojure, our goal is to provide tools that remove all friction from using the REPL in your programming workflow. We believe that the REPL enhances developer workflows thanks to context-sensitive auto-completion, signature inspection, and documentation���all based on the actual state of your code, and none of which are available in IDEs that depend solely on static analysis. We have found that for this reason, nbdev, with its Jupyter notebook foundation, makes programming significantly more productive and enjoyable.
Our efforts to support REPL-driven development and literate programming are not limited to nbdev. We maintain a number of libraries that extend python to bolster this programming experience. The most notable of these libraries is fastcore, which extends Python in terms of testing, documenting code, metaprogramming, attribute helpers, enhanced representations of objects, and notebook-friendly patching. This blog post offers a gentle introduction to fastcore. In addition to literate programming, fastcore encourages conventions such as brevity and efficient use of vertical space so you can accomplish more with significantly less code. For example, below is a simple decorator that enables notebook-friendly patching:
 @patch decorator from fastcore
@patch decorator from fastcore We believe that this combination of a new developer workflow (nbdev), Python extensions (fastcore), and associated norms form a new dialect of Python that is centered on leveraging its dynamic nature���in contrast to an ever-growing trend toward static analysis. We suspect that this dialect of Python will be more productive for programmers in many scenarios. We are framing this ecosystem as a ���dialect��� as it is still very much Python and is approachable by anyone who is familiar with the language. Furthermore, despite nbdev���s notebook workflow, our tools generate plaintext modules that can be navigated and edited with text-based IDEs, allowing programmers to experience the best of both worlds, if they desire.
Hamel: I believe this framing of a Python dialect is key to properly understanding what nbdev is. While it may be tempting to get stuck on specific features or technical details of nbdev, it is useful to zoom out to understand the overall intent of creating a better workflow rather than conforming too rigidly to existing ones. A good analogy is TypeScript���s relationship with JavaScript: it is an extension of an existing programming language that supports a new way of programming. I encourage you to treat nbdev in a similar fashion: be willing to try new ways of programming and observe which tradeoffs resonate with you. At the very least, I believe nbdev is a fun way to experience a different way of writing software, which will broaden your horizons about programming in general, all without having to learn an entirely new programming language!
The future of nbdevWhile we are excited about nbdev2, we believe we have only scratched the surface of what���s possible. We are considering the following features:
Supporting more languages beyond Python, such as Julia, R and JavaScript Offering interfaces for executing parameterized notebooks that mimic Python scripts Extensions for more static site generators and filters Supporting alternate testing backends, such as pytest Supporting a greater number of docstring formats, such as Google-style docstrings More options to use plain-text or human readable notebook backends other than JSONIf you have interesting ideas about how nbdev can be extended, please drop and chat with us on discord or post a message in the forums.
How you can get started with nbdevOur project���s website is at nbdev.fast.ai, where we will be posting tutorials, examples, and more documentation in the coming days.
Thank YouThis new version of nbdev was a team effort by many wonderful people. We want to highlight two people who have made outstanding contributions:
Wasim Lorgat was instrumental across different areas, including significant contributions to fastcore, execnb, and nbdev, as well as the implementation of the new nbdev home page. With Wasim���s help, we were able to push nbdev to a new level of functionality and quality.
JJ Allaire is not only the CEO of RStudio but also the steward of Quarto. JJ was incredibly responsive and eager to work with us on nbdev and added many features to Quarto specifically with nbdev in mind, such as notebook filters. We were also astounded by the attention to detail and the pace at which bugs are addressed. This new version of nbdev would not have been possible without JJ���s help, and we are excited to continue to work with him.
We also want to thank the amazing fastai community, notably Isaac Flath, Benjamin Warner and Zach Mueller for their tireless work on this project.
July 20, 2022
Practical Deep Learning for Coders 2022
Today we���re releasing Practical Deep Learning for Coders 2022���a complete from-scratch rewrite of fast.ai���s most popular course, that���s been two years in the making. Previous fast.ai courses have been studied by hundreds of thousands of students, from all walks of life, from all parts of the world. fast.ai���s videos have been viewed over 6,000,000 times already! The major differences are:
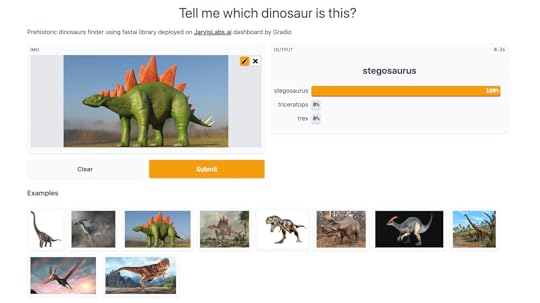
A much bigger focus on interactive explorations. Students in the course build simple GUIs for building decision trees, linear classifiers, and non-linear models by hand, using that experience to develop a deep intuitive understanding of how foundational algorithms work A broader mix of libraries and services are used, including the Hugging Face ecosystem (Transformers, Datasets, Spaces, and the Model Hub), Scikit Learn, and Gradio Coverage of new architectures, such as ConvNeXt, Visual Transformers (ViT), and DeBERTa v3By the end of the second lesson, students will have built and deployed their own deep learning model on their own data. Many students post their course projects to our forum. For instance, if there���s an unknown dinosaur in your backyard, maybe you need this dinosaur classifier!
Topics covered in this year���s course include:
Build and train deep learning models for computer vision, natural language processing, tabular analysis, and collaborative filtering problems Create random forests and regression models How to turn your models into web applications, and deploy them Use PyTorch, the world���s fastest growing deep learning software, plus popular libraries like fastai and Hugging Face Why and how deep learning models work, and how to use that knowledge to improve the accuracy, speed, and reliability of your models The latest deep learning techniques that really matter in practice How to implement the fundamentals of deep learning, including stochastic gradient descent and a complete training loop, from scratchAbout the courseThere are 9 lessons, and each lesson is around 90 minutes long. The course is based on our 5-star rated book, which is freely available online. No special hardware or software is needed ��� the course shows how to use free resources for both building and deploying models. University math isn���t needed either ��� the necessary calculus and linear algebra is introduced as needed during the course.

The course is taught by me, Jeremy Howard. I lead the development of fastai, the software used throughout this course. I have been using and teaching machine learning for around 30 years. I was the top-ranked competitor globally in machine learning competitions on Kaggle (the world���s largest machine learning community) two years running. Following this success, I became the President and Chief Scientist of Kaggle. Since first using neural networks over 25 years ago, I have led many companies and projects that have machine learning at their core, including founding the first company to focus on deep learning and medicine, Enlitic (chosen by MIT Tech Review as one of the ���world���s smartest companies���), and Optimal Decisions, the first company to develop a fully optimised pricing algorithm for insurance.
Students and resultsMany students have told us about how they���ve become multiple gold medal winners of international machine learning competitions, received offers from top companies, and having research papers published. For instance, Isaac Dimitrovsky told us that he had ���been playing around with ML for a couple of years without really grokking it��� [then] went through the fast.ai part 1 course late last year, and it clicked for me���. He went on to achieve first place in the prestigious international RA2-DREAM Challenge competition! He developed a multistage deep learning method for scoring radiographic hand and foot joint damage in rheumatoid arthritis, taking advantage of the fastai library.
Alumni of previous editions of Practical Deep Learning for Coders have gone on to jobs at organizations like Google Brain, OpenAI, Adobe, Amazon, and Tesla, published research at top conferences such as NeurIPS, and created startups using skills they learned here. Petro Cuenca, lead developer of the widely-acclaimed Camera+ app, after completing the course went on to add deep learning features to his product, which was then featured by Apple for its ���machine learning magic���.
Peter Norvig, author of Artificial Intelligence: A Modern Approach and previously the Director of Research at Google, reviewed our book (which this course is based on) and had this to say:
About deep learning���Deep Learning is for everyone��� we see in Chapter 1, Section 1 of this book, and while other books may make similar claims, this book delivers on the claim. The authors have extensive knowledge of the field but are able to describe it in a way that is perfectly suited for a reader with experience in programming but not in machine learning. The book shows examples first, and only covers theory in the context of concrete examples. For most people, this is the best way to learn. The book does an impressive job of covering the key applications of deep learning in computer vision, natural language processing, and tabular data processing, but also covers key topics like data ethics that some other books miss.
Deep learning is a computer technique to extract and transform data���-with use cases ranging from human speech recognition to animal imagery classification���-by using multiple layers of neural networks. A lot of people assume that you need all kinds of hard-to-find stuff to get great results with deep learning, but as you���ll see in this course, those people are wrong. Here���s a few things you absolutely don���t need to do world-class deep learning:
Myth (don���t need) Truth Lots of math Just high school math is sufficient Lots of data We���ve seen record-breaking results with <50 items of data Lots of expensive computers You can get what you need for state of the art work for free The lessons1: Getting started
In the first five minutes you���ll see a complete end to end example of training and using a model that���s so advanced it was considered at the cutting edge of research capabilities in 2015! We discuss what deep learning and neural networks are, and what they���re useful for.
We look at examples of deep learning for computer vision object classification, segmentation, tabular analysis, and collaborative filtering.
2: Deployment
This lesson shows how to design yown machine learning project, create your own dataset, train a model using your data, and finally deploy an application on the web. We use Hugging Face Space with Gradio for deployment, and also use JavaScript to implement an interface in the browser. (Deploying to other services looks very similar to the approach in this lesson.)
3: Neural net foundations
Lesson 3 is all about the mathematical foundations of deep learning, such as Stochastic gradient descent (SGD), matrix products, and the flexibility of linear functions layered with non-linear activation functions. We focus particularly on a popular combination called the Rectified linear function (ReLU).
4: Natural Language (NLP)
We look at how to analyse natural language documents using Natural Language Processing (NLP). We be focus on the Hugging Face ecosystem, especially the Transformers library, and the vast collection of pretrained NLP models. The project for this lesson is to classify that similarity of phrases used to describe US patents. A similar approach can be applied to a wide variety of practical issues, in fields as wide-reaching as marketing, logistics, and medicine.
5: From-scratch model
In this lesson we look at how to create a neural network from scratch using Python and PyTorch, and how to implement a training loop for optimising the weights of a model. We build up from a single layer regression model up to a neural net with one hidden layer, and then to a deep learning model. Along the way we also look at how we can use a special function called sigmoid to make binary classification models easier to train, and we learn about metrics.
6: Random forests
Random forests started a revolution in machine learning 20 years ago. For the first time, there was a fast and reliable algorithm which made almost no assumptions about the form of the data, and required almost no preprocessing. In lesson 6, you���ll learn how a random forest really works, and how to build one from scratch. And, just as importantly, you���ll learn how to interpret random forests to better understand your data.
7: Collaborative filtering and embeddings
You interact nearly every day with recommendation systems���algorithms which guess what products and services you might like, based on your past behavior. These systems largely rely on collaborative-filtering, an approach based on linear algebra that fills in the missing values in a matrix. In this lesson we���ll see two ways to do this: one based on a classic linear algebra formulation, and one based on deep learning. We finish off our study of collaborative filtering by looking closely at embeddings���a critical building block of many deep learning algorithms.
8: Convolutions (CNNs)
Here we dive into convolutional neural networks (CNNs) and see how they really work. We used plenty of CNNs in earlier lessons, but we didn���t peeked inside them to see what���s really going on in there.
As well as learning about the most fundamental building block of CNNs, the convolution, we also look at pooling, dropout, and more.
A vibrant communityMany fast.ai alumni have told us that one of their favorite things about the course is the generous and thoughtful community of interesting people that has sprung up around it.
If you need help, or just want to chat about what you���re learning about (or show off what you���ve built!), there���s a wonderful online community ready to support you at forums.fast.ai. Every lesson has a dedicated forum thread���with many common questions already answered.
For real-time conversations about the course, there���s also a very active Discord server.
Get startedTo get started with the course now, head over to Practical Deep Learning for Coders 2022!
Practical Deep Learning for Coders 2022
Today we���re releasing Practical Deep Learning for Coders 2022���a complete from-scratch rewrite of fast.ai���s most popular course, that���s been two years in the making. Previous fast.ai courses have been studied by hundreds of thousands of students, from all walks of life, from all parts of the world. fast.ai���s videos have been viewed over 6,000,000 times already! The major differences are:
A much bigger focus on interactive explorations. Students in the course build simple GUIs for building decision trees, linear classifiers, and non-linear models by hand, using that experience to develop a deep intuitive understanding of how foundational algorithms work A broader mix of libraries and services are used, including the Hugging Face ecosystem (Transformers, Datasets, Spaces, and the Model Hub), Scikit Learn, and Gradio Coverage of new architectures, such as ConvNeXt, Visual Transformers (ViT), and DeBERTa v3By the end of the second lesson, students will have built and deployed their own deep learning model on their own data. Many students post their course projects to our forum. For instance, if there���s an unknown dinosaur in your backyard, maybe you need this dinosaur classifier!
Topics covered in this year���s course include:
Build and train deep learning models for computer vision, natural language processing, tabular analysis, and collaborative filtering problems Create random forests and regression models How to turn your models into web applications, and deploy them Use PyTorch, the world���s fastest growing deep learning software, plus popular libraries like fastai and Hugging Face Why and how deep learning models work, and how to use that knowledge to improve the accuracy, speed, and reliability of your models The latest deep learning techniques that really matter in practice How to implement the fundamentals of deep learning, including stochastic gradient descent and a complete training loop, from scratchAbout the courseThere are 9 lessons, and each lesson is around 90 minutes long. The course is based on our 5-star rated book, which is freely available online. No special hardware or software is needed ��� the course shows how to use free resources for both building and deploying models. University math isn���t needed either ��� the necessary calculus and linear algebra is introduced as needed during the course.

The course is taught by me, Jeremy Howard. I lead the development of fastai, the software used throughout this course. I have been using and teaching machine learning for around 30 years. I was the top-ranked competitor globally in machine learning competitions on Kaggle (the world���s largest machine learning community) two years running. Following this success, I became the President and Chief Scientist of Kaggle. Since first using neural networks over 25 years ago, I have led many companies and projects that have machine learning at their core, including founding the first company to focus on deep learning and medicine, Enlitic (chosen by MIT Tech Review as one of the ���world���s smartest companies���), and Optimal Decisions, the first company to develop a fully optimised pricing algorithm for insurance.
Students and resultsMany students have told us about how they���ve become multiple gold medal winners of international machine learning competitions, received offers from top companies, and having research papers published. For instance, Isaac Dimitrovsky told us that he had ���been playing around with ML for a couple of years without really grokking it��� [then] went through the fast.ai part 1 course late last year, and it clicked for me���. He went on to achieve first place in the prestigious international RA2-DREAM Challenge competition! He developed a multistage deep learning method for scoring radiographic hand and foot joint damage in rheumatoid arthritis, taking advantage of the fastai library.
Alumni of previous editions of Practical Deep Learning for Coders have gone on to jobs at organizations like Google Brain, OpenAI, Adobe, Amazon, and Tesla, published research at top conferences such as NeurIPS, and created startups using skills they learned here. Petro Cuenca, lead developer of the widely-acclaimed Camera+ app, after completing the course went on to add deep learning features to his product, which was then featured by Apple for its ���machine learning magic���.
Peter Norvig, author of Artificial Intelligence: A Modern Approach and previously the Director of Research at Google, reviewed our book (which this course is based on) and had this to say:
About deep learning���Deep Learning is for everyone��� we see in Chapter 1, Section 1 of this book, and while other books may make similar claims, this book delivers on the claim. The authors have extensive knowledge of the field but are able to describe it in a way that is perfectly suited for a reader with experience in programming but not in machine learning. The book shows examples first, and only covers theory in the context of concrete examples. For most people, this is the best way to learn. The book does an impressive job of covering the key applications of deep learning in computer vision, natural language processing, and tabular data processing, but also covers key topics like data ethics that some other books miss.
Deep learning is a computer technique to extract and transform data���-with use cases ranging from human speech recognition to animal imagery classification���-by using multiple layers of neural networks. A lot of people assume that you need all kinds of hard-to-find stuff to get great results with deep learning, but as you���ll see in this course, those people are wrong. Here���s a few things you absolutely don���t need to do world-class deep learning:
Myth (don���t need) Truth Lots of math Just high school math is sufficient Lots of data We���ve seen record-breaking results with <50 items of data Lots of expensive computers You can get what you need for state of the art work for free The lessons1: Getting started
In the first five minutes you���ll see a complete end to end example of training and using a model that���s so advanced it was considered at the cutting edge of research capabilities in 2015! We discuss what deep learning and neural networks are, and what they���re useful for.
We look at examples of deep learning for computer vision object classification, segmentation, tabular analysis, and collaborative filtering.
2: Deployment
This lesson shows how to design yown machine learning project, create your own dataset, train a model using your data, and finally deploy an application on the web. We use Hugging Face Space with Gradio for deployment, and also use JavaScript to implement an interface in the browser. (Deploying to other services looks very similar to the approach in this lesson.)
3: Neural net foundations
Lesson 3 is all about the mathematical foundations of deep learning, such as Stochastic gradient descent (SGD), matrix products, and the flexibility of linear functions layered with non-linear activation functions. We focus particularly on a popular combination called the Rectified linear function (ReLU).
4: Natural Language (NLP)
We look at how to analyse natural language documents using Natural Language Processing (NLP). We be focus on the Hugging Face ecosystem, especially the Transformers library, and the vast collection of pretrained NLP models. The project for this lesson is to classify that similarity of phrases used to describe US patents. A similar approach can be applied to a wide variety of practical issues, in fields as wide-reaching as marketing, logistics, and medicine.
5: From-scratch model
In this lesson we look at how to create a neural network from scratch using Python and PyTorch, and how to implement a training loop for optimising the weights of a model. We build up from a single layer regression model up to a neural net with one hidden layer, and then to a deep learning model. Along the way we also look at how we can use a special function called sigmoid to make binary classification models easier to train, and we learn about metrics.
6: Random forests
Random forests started a revolution in machine learning 20 years ago. For the first time, there was a fast and reliable algorithm which made almost no assumptions about the form of the data, and required almost no preprocessing. In lesson 6, you���ll learn how a random forest really works, and how to build one from scratch. And, just as importantly, you���ll learn how to interpret random forests to better understand your data.
7: Collaborative filtering and embeddings
You interact nearly every day with recommendation systems���algorithms which guess what products and services you might like, based on your past behavior. These systems largely rely on collaborative-filtering, an approach based on linear algebra that fills in the missing values in a matrix. In this lesson we���ll see two ways to do this: one based on a classic linear algebra formulation, and one based on deep learning. We finish off our study of collaborative filtering by looking closely at embeddings���a critical building block of many deep learning algorithms.
8: Convolutions (CNNs)
Here we dive into convolutional neural networks (CNNs) and see how they really work. We used plenty of CNNs in earlier lessons, but we didn���t peeked inside them to see what���s really going on in there.
As well as learning about the most fundamental building block of CNNs, the convolution, we also look at pooling, dropout, and more.
A vibrant communityMany fast.ai alumni have told us that one of their favorite things about the course is the generous and thoughtful community of interesting people that has sprung up around it.
If you need help, or just want to chat about what you���re learning about (or show off what you���ve built!), there���s a wonderful online community ready to support you at forums.fast.ai. Every lesson has a dedicated forum thread���with many common questions already answered.
For real-time conversations about the course, there���s also a very active Discord server.
Get startedTo get started with the course now, head over to Practical Deep Learning for Coders 2022!
July 3, 2022
Masks for COVID: Updating the evidence
Contents The rise of better masks Masks work Omicron changes the game Better masks work better Pushing back against masks Respirators can be reused Fit tests are not required for respirators to be effective Donning and doffing masks is not complex or risky We should not reserve respirators for healthcare workers Respirators need not be uncomfortableThe rise of better masksThese are notes I took whilst preparing a paper on mask efficacy from Nov 2021 to Jan 2022. In the end, I gave up on the paper, because I felt like people had given up on masks, so there wasn���t much point in finishing it. I���ve decided to publish these notes in the hope some people will find them a useful starting point for their own research. My previous paper on this topic, in which I led a team of 19 experts, was written in April 2020, and published here in the Proceedings of the National Academy of Science.
In the US, 400 million N95 masks are being distributed for free, coming from the 750 million stored in the US��� Strategic National Stockpile. A similar campaign to distribute 650 millions masks in the US in 2020 was cancelled.
KN95 masks are being given to US congressional staff, and masks are required for federal workers and whilst in federal buildings.
The Los Angeles school district has required students to upgrade from cloth masks to ���well-fitting, non-cloth masks with a nose wire���.
Masks workA review paper discussed both lab evidence and empirical evidence for the importance of face masks, with eight ���seminal studies��� showing a reduction in transmission when masks are used, and one Danish study of surgical masks with ���several design limitations��� which ���demonstrated only a modest benefit in limiting COVID-19 transmission���. The authors note that ���laboratory studies have demonstrated the ability of surgical masks to block SARS-COV-2 and other viruses���, with the masks ���60%���70% effective at protecting others and 50% effective at protecting the wearer���.
An evidence review from early in the pandemic concluded that ���given the current shortages of medical masks, we recommend the adoption of public cloth mask wearing, as an effective form of source control���. It noted that ���by the end of June 2020, nearly 90% of the global population lived in regions that had nearly universal mask use, or had laws requiring mask use in some public locations.��� The review said that ���There has been one controlled trial of mask use for influenza control in the general community. The study looked at Australian households, was not done during a pandemic, and was done without any enforcement of compliance��� ��� and yet still found ���masks as a group had protective efficacy in excess of 80% against clinical influenza-like illness.���
An observational study of Beijing households analyzed the impact of mask use in the community on COVID-19 transmission, finding that face masks were 79% effective in preventing transmission, if used by all household members prior to symptoms occurring.
One study used a multiple regression of policy interventions and country and population characteristics to infer the relationship between mask use and SARS-CoV-2 transmission. It found that transmission was around 7.5 times higher in countries that did not have a mask mandate or universal mask use, a result similar to that found in an analogous study of fewer countries. Similar results were found by numerous other papers.
A mathematical model of mask use estimates that mask wearing reduces the reproduction number R by (1���mp)^2, where m is the efficacy of trapping viral particles inside the mask, and p is the percentage of the population that wears masks.
A report in Nature explained that researchers running a randomized controlled trial (RCT) of community mask use in Bangladesh ���began by developing a strategy to promote mask wearing, with measures such as reminders from health workers in public places. This ultimately tripled mask usage, from only 13% in control villages to 42% in villages where it was encouraged���, and ���then compared numbers of COVID-19 cases in control villages and the treatment communities���. They found that the number of infections in mask wearing communities decreased, with a reduction of COVID symptoms using surgical masks to 0.87 times the incidence in unmasked communities, and 0.91 times when using cloth masks. The report noted that ���the researchers suggest that the true risk reduction is probably much greater, in part because they did no SARS-CoV-2 testing of people without symptoms or whose symptoms did not meet the World Health Organization���s definition of the disease.��� The researchers concluded that ���promoting community mask-wearing can improve public health���.
The Johns Hopkins School of Public Health reviewed the work and concluded that ���This study is the largest and best-designed randomized controlled trial to date of a realistic non-pharmaceutical intervention on SARS-CoV-2 transmission.���
A paper investigating an upper bound on one-to-one exposure to infectious human respiratory particles concludes that ���face masks significantly reduce the risk of SARS-CoV-2 infection compared to social distancing. We find a very low risk of infection when everyone wears a face mask, even if it doesn���t fit perfectly on the face.��� They calculate that ���social distancing alone, even at 3.0 m between two speaking individuals, leads to an upper bound of 90% for risk of infection after a few minutes���, but that when both source and susceptible wear a well-fitting FFP2 mask, there is only 0.4% after one hour of contact. They found that to achieve good fit it is important to mold the nose piece wire to the size of the nose, rather than leaving it in a sharp folded position.
A similar study ���quantifies the extent to which transmission risk is reduced in large rooms with high air exchange rates, increased for more vigorous respiratory activities, and dramatically reduced by the use of face masks.��� The authors describe the six-foot rule widely used to ensure social distancing as ���a guideline that offers little protection from pathogen-bearing aerosol droplets sufficiently small to be continuously mixed through an indoor space.��� Instead, they develop a safety guideline based on cumulative exposure time,��� the product of the number of occupants and their time in an enclosed space. In particular, they identify that the greatest risk comes in places where people are speaking (other than quietly) or singing, and that ���the benefit of face masks is immediately apparent���, due to the multiplicative effect when both source and susceptible wear a mask. They further note that ���Air filtration has a less dramatic effect than face mask use in increasing the CET bound. Nevertheless, it does offer a means of mitigating indoor transmission with greater comfort, albeit at greater cost.���
Another study of the combined impacts of ventilation and mask effective filtration efficiency in classroom settings found that ���ventilation alone is not able to achieve probabilities <0.01 (1%)��� of transmitting COVID in a classroom. However, they found that good masks reduce infection probability by >5�� in some cases, and that ���reductions provided by ventilation and masks are synergistic and multiplicative���. However they also noted that ���most masks fit poorly���, recommending that work be done to ensure that high quality masks are used.
Similar results were found in a study of community public health interventions, which concluded that ���control the pandemic, our models suggest that high adherence to social distance is necessary to curb the spread of the disease, and that wearing face masks provides optimal protection even if only a small portion of the population comply with social distance���.
Guidance from the independent scientific advisory group OzSAGE points out ���that school children are able to wear masks. As an example, all children over two years of age in San Francisco are required to wear masks at school���.
Omicron changes the gameAn analysis of fine aerosol emissions found that, compared to the original wild type (WT) virus:
���Delta and Omicron both also have increased transmissibility: the number of cells infected for a given number of ribonucleic acid (RNA) virus copies was found to be doubled and quadrupled respectively. Furthermore, Omicron also seems to be better at evading the immune system. This implies that the critical dose of virus copies above which a situation is potentially infectious needs to be lowered. For the WT, we had proposed a critical dose of 500 virus copies. If the above-mentioned capacity to infect cells translates into an infection risk, this would imply a critical dose of around 300 virus copies for Delta and around 100 virus copies for Omicron.���
The study finds that ���surgical masks are no longer sufficient in most public settings, while correctly fitted FFP2 respirators still provide sufficient protection, except in high aerosol producing situations such as singing or shouting.���
Data from Hong Kong shows that ���Omicron SARS-CoV-2 infects and multiplies 70 times faster than the Delta variant and original SARS-CoV-2 in human bronchus���.
A study of transmission in Danish households estimated the secondary attack rate (SAR) of omicron compared to delta, finding it 1.2 times higher for unvaccinated people, 2.6 times higher for double-dosed, and 3.7 times higher for boosted. The authors conclude that ���the rapid spread of the Omicron VOC primarily can be ascribed to the immune evasiveness���.
According to UK statistics, the risk of hospitalization from omicron when unvaccinated is about the same as the wildtype virus, which is about half the risk of the delta variant.
The journal Infection Control Today reported that many experts are concerned that ������Omicron the Pandemic Killer��� Idea Ignores Dangers of Long COVID���:
Better masks work better���Linda Spaulding, RN-BC, CIC, CHEC, CHOP, a member of Infection Control Today�����s Editorial Advisory Board (EAB), says that she���s ���seen athletes in their 20s on the wait list for double lung transplants because of long COVID. That���s something that has long-term consequences. Some people talk of COVID fog. They just can���t put their thoughts together.��� In addition, even the treatments for those with long COVID can put toll on a patient���s body.���
���As noted by Kevin Kavanagh, MD, another member of ICT�����s EAB, a core difficulty in society���s attempt to guide COVID-19 from pandemic to endemic is that COVID is not just a respiratory virus. Kavanagh wrote in October that SARS-CoV-2 is similar to HIV because it can ���silently spread throughout the host���s body and attack almost every organ.������
The US Centers for Disease Control and Prevention (CDC) explains that:
���Loosely woven cloth products provide the least protection, layered finely woven products offer more protection, well-fitting disposable surgical masks and KN95s offer even more protection, and well-fitting NIOSH-approved respirators (including N95s) offer the highest level of protection.���
Unfortunately ���well-fitting disposable surgical masks��� do not exist out of the box, since there are large gaps on each side of the mask. Surgical masks require modifications to achive a good fit. That���s because they are made to stop liquid splashes during surgery, rather than made to stop airborne transmission. There are two methods shown by the CDC to improve fit:
Knot and Tuck: Tying the sides of the mask together to remove the side gap Double masking: Wearing a tight fitting cloth mask over a surgical maskResearch shows that both of these approaches dramatically reduce exposure to aerosols emitted during a period of breathing:
������adding a cloth mask over the source headform���s medical procedure mask or knotting and tucking the medical procedure mask reduced the cumulative exposure of the unmasked receiver by 82.2% (SD = 0.16) and 62.9% (SD = 0.08), respectively (Figure 2). When the source was unmasked and the receiver was fitted with the double mask or the knotted and tucked medical procedure mask, the receiver���s cumulative exposure was reduced by 83.0% (SD = 0.15) and 64.5% (SD = 0.03), respectively. When the source and receiver were both fitted with double masks or knotted and tucked masks, the cumulative exposure of the receiver was reduced 96.4% (SD = 0.02) and 95.9% (SD = 0.02), respectively.���
An airborne transmission simulator was used to estimate the ability of various types of face masks to block COVID-19 transmission. In this experiment, ���cotton mask led to an approximately 20% to 40% reduction in virus uptake compared to no mask. The N95 mask had the highest protective efficacy (approximately 80% to 90% reduction)���. All of the masks were much more effective at source control than at protecting the wearer, with the N95 stopping all detectable transmission.
The American Conference of Governmental Industrial Hygienists (ACGIH) say that ���workers need respirators���, noting that a worker with an ���N95 filtering facepiece respirator��� has 1-10% inward leakage and outward leakage���, but with a surgical mask ���has 50% inward leakage and outward leakage���, and with a cloth face covering ���has 75% inward leakage and outward leakage���. They explain that ���N95 FFRs have an assigned protection factor of 10 (10% inward leakage) but must receive a fit factor of 100 (1% inward leakage) on an individual worker.��� ACGIH created a table showing how, if we start with an assumption that it takes on average 15 minutes to get infected if no-one is wearing a mask (based on CDC contact tracing premises), we can calculate the time it would take on average to get infected if one or both of source and receiver are wearing various types of mask. This is calculated by simply dividing the base time of 15 minutes by the leakage factor for the source���s mask (if any), and then dividing that by the leakage factor for the receiver���s mask (if any).
This approach is, however, an over-simplification. Reseach based on a a single-hit model of infection shows that the probability of infection ���shows a highly nonlinear sensitivity��� to inhaled virus number. Therefore, ���In a virus-rich regime��� wearing a mask may not suffice to prevent infection.���
Research undertaken by the National Personal Protective Technology Laboratory (NPPTL) found that respirators with an exhalation valve ���reduce particle emissions to levels similar to or better than those provided by surgical masks, procedure masks, or cloth face coverings���. Furthermore, ���surgical tape secured over the valve from the inside of the FFR can provide source control similar to that of an FFR with no exhalation valve���.
Pushing back against masksProfessor Alison McMillan, Commonwealth Chief Nursing and Midwifery Officer in Australia claims that ���there is no evidence to suggest that we should be moving towards��� N95 respirators in the community setting.��� She added ���I am aware that there are some publications out there suggesting a move to N95 (masks). But that���s not supported in the empirical evidence���.
According to Norman Swan, host of the ABC���s Coronacast, ���If you���re wearing an N95 that hasn���t been fit tested ��� and it���s not an easy process to do yourself at home ��� there���s no guarantee that it���s an awful lot more effective than wearing a surgical mask. Professor Catherine Bennett, chair in epidemiology at Deakin University, claims that ���Technically, the instructions say you shouldn���t reuse��� respirators, and that ���If you���re not particularly checking its fit, you���re probably wasting your time���. Occupational environment physician Malcolm Sim agrees: ���If you put it [an N95 mask] off and put it on, they���re not meant for that purpose��� They���re easily damaged in somebody���s handbag,��� adding that the integrity of the masks can be compromised. He says that ���If you���re handling them a lot, taking them on and off, there���s much more potential for you to get it [the virus] on your hands, your face, different parts of your body.���
University of New South Wales epidemiologist Mary-Louise McLaws claimed that ���There���s no evidence yet that a N95 mask will protect you more than a surgical mask for Omicron.���
An opinion piece in Newsweek claims that ���the effectiveness of respirators is vastly overestimated, and there is scant evidence that they stop community transmission. Moreover, NIOSH-approved respirators are tight, uncomfortable, and can impede breathing.��� The article further claims that ���For respirators to work, they must be well fitting, must be tested by OSHA, and must be used for only short time windows as their effectiveness diminishes as they get wet from breathing.���
Recently there has been particular pushback against the use of masks by children, with the Newsweek article alleging that ���Respirators are not necessary to protect children from COVID-19 because of the astoundingly low risk COVID-19 presents to them���, and that in fact wearing masks involves ���existing well-documented harms���. There hasn���t been any documented harms to children from wearing masks,
Respirators can be reusedAccording to mask manufacturer 3M, respirators (which they refer to as ���Filtering Facepiece Respirators (FFRs)���) ���can be used many times.��� They say that ���There is no time limit to wearing an FFR. Respirators can be worn until they are dirty, damaged or difficult to breathe through.���
In reporting from CNN, Linsey Marr, a professor of civil and environmental engineering at Virginia Tech, explained that an N95 mask���s material and filtration ability aren���t ���going to degrade unless you physically rub it or poke holes in it. ���You���d have to be in really polluted air ��� for several days before it lost its ability to filter out particles. So, you can really wear them for a long time. People have been talking about 40 hours ��� I think that���s fine. Really, it���s going to get gross from your face or the straps will get too loose or maybe break before you���re going to lose filtration ability��� One of the first indicators of being able to change it if it looks nice and clean is that it just feels a little harder to breathe through. There appears to be more resistance with every breath.��� She also noted that the contamination risk in reusing N95 masks is ���lower, much lower, than the risk of you not wearing an N95 and breathing in particles���.
The CDC has prepared guidelines for optimizing the supply of respirators which recommend reusing respirators at most five times. This guidelines were created for people ���implementing policies and procedures for preventing pathogen transmission in healthcare settings���. They have been widely shared, incorrectly, by reporters as being recommendations for community use.
The inventor of N95 mask material, Peter Tsai, says that ���N95 masks can be rotated, 1 mask every 3���4 days���, and that in doing this ���there is no change in the mask���s properties.���
According to the NIOSH Guide to the Selection and Use of Particulate Respirators N95 respirators must maintain at least 95% filtration after a total mass loading of 200mg. This is designed to ensure they continue to work in sites with high particulate matter, such as some construction environment. However in normal use, even outside in a city with high levels of population, it would take over 200 days of 24 hour per day use to get to this level. The guide says that ���generally, the use and reuse of N-series �� lters would also be subject only to considerations of hygiene, damage, and increased breathing resistance���. The NIOSH guidelines are well supported by research.
Fit tests are not required for respirators to be effectiveIn one study non-experts were asked to read the instructions that come with a respirator, and then to don the respirator without assistance and complete a fit test. The average fit factor achieved was 88, and the lowest fit factor of the subjects was 15, with nearly half achieving a fit factor greater than 100.
Surgical masks have been found to have a much poorer fit in practice. One study showed that for surgical masks ���quantitative fit factors ranged from 2.5 to 9.6���, and another found an average fit factor of 3.0.
Guidance from the US Food and Drug Administration (FDA) explains that:
���Fit Factor is a means of expressing the difference in particle concentration inside the mask and outside the mask during use. For example, a fit factor of 2 means that the concentration of particles within the mask is �� or 50% of the concentration outside the mask; a fit factor of 5 means the concentration of particles within the mask is 1/5 th or 20% of the concentration outside the mask.���
The guidance says that failing to achieve a fit factor of 2 ���may suggest that respirator fit will not be sufficient to assure that the device will help reduce wearer exposure to pathogenic biological airborne particulates.���
An analysis of the fitted filtration efficiency (FFE) of surgical masks found that, unmodified, they only achieved an FFE of 38.5%. The ���knot and tuck��� technique improved that to 60.3%, and a DIY mask fitter consisting of three rubber bands increased it to 78.2%. A 3-layer cotton mask had an FFE of just 26.5%. An N95, on the other hand, achieved an FFE of 98.4%. Furthermore, the N95 FFE had a standard deviation of only 0.5% ��� that is, it was effective for multiple tests during ���a series of repeated movements of the torso, head, and facial muscles���. Interestingly, a 2-layer nylon mask had an FFE of 79.0% (standard devatiation 4.3%), showing that some cloth masks can be quite effective. These findings were replicated in a study of numerous types of cloth mask, which found that hybrids of 600 TPI cotton with silk, chiffon, or polypropelene achieved 72-96% filtration efficiency.
Researchers have calculated that ���the particle size most likely to deposit in the respiratory tract when wearing a mask is ���2��m���. Unfortunately, this particle size is not considered in N95 or similar standards. Instead, 0.3 ��m particles are used.
A 2010 study of fit testing respirators for public health medical emergencies found that 98% of non-experts wearing masks without training achieved a fit factor of over 5 (20% leakage) and 75% of them achieved a fit factor of over 10 (10% leakage).
Donning and doffing masks is not complex or riskyAnalysis by the CDC concludes that the risk of infection through surfaces (fomites) ���is generally considered to be low���, a view that was supported by the evidence as early as July 2020. An analysis of ���418 samples from mask fronts, cell phones, paper money, card machines, sewage, air and bedding��� during a COVID surge ���did not detect any trace of SARS-CoV-2 in all samples analyzed���.
We should not reserve respirators for healthcare workersAccording to Anne Miller, executive director of Project N95, there are many U.S. manufacturers of N95 masks and an ample supply.
The Economist reported that in Europe ���at the start of the pandemic, FFP2 masks were scarce and costly. Even governments fell victim to price gouging, paying more than ���4 ($4.50) per mask. Demand had previously been low, so stockpiles and production capacity could not satisfy the sudden surge. Governments wanted to reserve supplies for those most at risk of contracting the virus, such as health-care workers.��� However they reported that by the end of 2021 ���FFP2 masks are in healthy supply, and as the highly transmissible Omicron variant spreads across the world, updating guidance to recommend their wider use could be one way to help reduce transmission.���
In the first 6 months of 2020, over 70,000 new face mask companies were registered in China, many run by people with no previous experience and no registration or licensing. The Chinese government stepped in to make licensing more stringent, shutting down many companies, and international demand fell over quality concerns.
Due to ���a dramatic reduction in demand for N95s���, US mask factories are closing. In June 2021 the American Mask Manufacturer���s Association said that ���we have 28 members who are going to go out of business in the next 60 to 90 days.��� By July 2021 they estimated ���that 5,000 workers have been laid off across its member companies���. However following school mask mandates and demand during the omicron surge, demand in the US spiked in early 2022.
The CDC has found that 60% of KN95s are counterfeit.
In Australia it has been reported that ���general practitioners have been left without highly protective N95 masks as consumers rush to stock up after a sharp rise in COVID-19 cases.���
In May 2021 the CDC stated that ���The supply and availability of NIOSH-approved respirators have increased significantly over the last several months. Healthcare facilities should not be using crisis capacity strategies at this time and should promptly resume conventional practices.���
Demand distortions can increase as we proceed up the supply chain, creating inefficiencies for upstream firms. This is known as the Bullwhip Effect.
Respirators need not be uncomfortableIn an analysis of the physiological impact of the N95 filtering facepiece respirator (FFR) ���in healthy healthcare workers, FFR did not impose any important physiological burden during 1 hour of use, at realistic clinical work rates���.
A study of KF80, KF94, KF99, N95, and N99 masks found that self-reported comfort levels were nearly perfectly correlated with the ease of inhalation.
Masks for COVID: Updating the evidence
Contents The rise of better masks Masks work Omicron changes the game Better masks work better Pushing back against masks Respirators can be reused Fit tests are not required for respirators to be effective Donning and doffing masks is not complex or risky We should not reserve respirators for healthcare workers Respirators need not be uncomfortableThe rise of better masksThese are notes I took whilst preparing a paper on mask efficacy from Nov 2021 to Jan 2022. In the end, I gave up on the paper, because I felt like people had given up on masks, so there wasn���t much point in finishing it. I���ve decided to publish these notes in the hope some people will find them a useful starting point for their own research, and since I���ve noticed some signs in recent weeks that people might be open to avoiding COVID again. My previous paper on this topic, in which I led a team of 19 experts, was written in April 2020, and published here in the Proceedings of the National Academy of Science.
In the US, 400 million N95 masks are being distributed for free, coming from the 750 million stored in the US��� Strategic National Stockpile. A similar campaign to distribute 650 millions masks in the US in 2020 was cancelled.
KN95 masks are being given to US congressional staff, and masks are required for federal workers and whilst in federal buildings.
The Los Angeles school district has required students to upgrade from cloth masks to ���well-fitting, non-cloth masks with a nose wire���.
Masks workA review paper discussed both lab evidence and empirical evidence for the importance of face masks, with eight ���seminal studies��� showing a reduction in transmission when masks are used, and one Danish study of surgical masks with ���several design limitations��� which ���demonstrated only a modest benefit in limiting COVID-19 transmission���. The authors note that ���laboratory studies have demonstrated the ability of surgical masks to block SARS-COV-2 and other viruses���, with the masks ���60%���70% effective at protecting others and 50% effective at protecting the wearer���.
An evidence review from early in the pandemic concluded that ���given the current shortages of medical masks, we recommend the adoption of public cloth mask wearing, as an effective form of source control���. It noted that ���by the end of June 2020, nearly 90% of the global population lived in regions that had nearly universal mask use, or had laws requiring mask use in some public locations.��� The review said that ���There has been one controlled trial of mask use for influenza control in the general community. The study looked at Australian households, was not done during a pandemic, and was done without any enforcement of compliance��� ��� and yet still found ���masks as a group had protective efficacy in excess of 80% against clinical influenza-like illness.���
An observational study of Beijing households analyzed the impact of mask use in the community on COVID-19 transmission, finding that face masks were 79% effective in preventing transmission, if used by all household members prior to symptoms occurring.
One study used a multiple regression of policy interventions and country and population characteristics to infer the relationship between mask use and SARS-CoV-2 transmission. It found that transmission was around 7.5 times higher in countries that did not have a mask mandate or universal mask use, a result similar to that found in an analogous study of fewer countries. Similar results were found by numerous other papers.
A mathematical model of mask use estimates that mask wearing reduces the reproduction number R by (1���mp)^2, where m is the efficacy of trapping viral particles inside the mask, and p is the percentage of the population that wears masks.
A report in Nature explained that researchers running a randomized controlled trial (RCT) of community mask use in Bangladesh ���began by developing a strategy to promote mask wearing, with measures such as reminders from health workers in public places. This ultimately tripled mask usage, from only 13% in control villages to 42% in villages where it was encouraged���, and ���then compared numbers of COVID-19 cases in control villages and the treatment communities���. They found that the number of infections in mask wearing communities decreased, with a reduction of COVID symptoms using surgical masks to 0.87 times the incidence in unmasked communities, and 0.91 times when using cloth masks. The report noted that ���the researchers suggest that the true risk reduction is probably much greater, in part because they did no SARS-CoV-2 testing of people without symptoms or whose symptoms did not meet the World Health Organization���s definition of the disease.��� The researchers concluded that ���promoting community mask-wearing can improve public health���.
The Johns Hopkins School of Public Health reviewed the work and concluded that ���This study is the largest and best-designed randomized controlled trial to date of a realistic non-pharmaceutical intervention on SARS-CoV-2 transmission.���
A paper investigating an upper bound on one-to-one exposure to infectious human respiratory particles concludes that ���face masks significantly reduce the risk of SARS-CoV-2 infection compared to social distancing. We find a very low risk of infection when everyone wears a face mask, even if it doesn���t fit perfectly on the face.��� They calculate that ���social distancing alone, even at 3.0 m between two speaking individuals, leads to an upper bound of 90% for risk of infection after a few minutes���, but that when both source and susceptible wear a well-fitting FFP2 mask, there is only 0.4% after one hour of contact. They found that to achieve good fit it is important to mold the nose piece wire to the size of the nose, rather than leaving it in a sharp folded position.
A similar study ���quantifies the extent to which transmission risk is reduced in large rooms with high air exchange rates, increased for more vigorous respiratory activities, and dramatically reduced by the use of face masks.��� The authors describe the six-foot rule widely used to ensure social distancing as ���a guideline that offers little protection from pathogen-bearing aerosol droplets sufficiently small to be continuously mixed through an indoor space.��� Instead, they develop a safety guideline based on cumulative exposure time,��� the product of the number of occupants and their time in an enclosed space. In particular, they identify that the greatest risk comes in places where people are speaking (other than quietly) or singing, and that ���the benefit of face masks is immediately apparent���, due to the multiplicative effect when both source and susceptible wear a mask. They further note that ���Air filtration has a less dramatic effect than face mask use in increasing the CET bound. Nevertheless, it does offer a means of mitigating indoor transmission with greater comfort, albeit at greater cost.���
Another study of the combined impacts of ventilation and mask effective filtration efficiency in classroom settings found that ���ventilation alone is not able to achieve probabilities <0.01 (1%)��� of transmitting COVID in a classroom. However, they found that good masks reduce infection probability by >5�� in some cases, and that ���reductions provided by ventilation and masks are synergistic and multiplicative���. However they also noted that ���most masks fit poorly���, recommending that work be done to ensure that high quality masks are used.
Similar results were found in a study of community public health interventions, which concluded that ���control the pandemic, our models suggest that high adherence to social distance is necessary to curb the spread of the disease, and that wearing face masks provides optimal protection even if only a small portion of the population comply with social distance���.
Guidance from the independent scientific advisory group OzSAGE points out ���that school children are able to wear masks. As an example, all children over two years of age in San Francisco are required to wear masks at school���.
Omicron changes the gameAn analysis of fine aerosol emissions found that, compared to the original wild type (WT) virus:
���Delta and Omicron both also have increased transmissibility: the number of cells infected for a given number of ribonucleic acid (RNA) virus copies was found to be doubled and quadrupled respectively. Furthermore, Omicron also seems to be better at evading the immune system. This implies that the critical dose of virus copies above which a situation is potentially infectious needs to be lowered. For the WT, we had proposed a critical dose of 500 virus copies. If the above-mentioned capacity to infect cells translates into an infection risk, this would imply a critical dose of around 300 virus copies for Delta and around 100 virus copies for Omicron.���
The study finds that ���surgical masks are no longer sufficient in most public settings, while correctly fitted FFP2 respirators still provide sufficient protection, except in high aerosol producing situations such as singing or shouting.���
Data from Hong Kong shows that ���Omicron SARS-CoV-2 infects and multiplies 70 times faster than the Delta variant and original SARS-CoV-2 in human bronchus���.
A study of transmission in Danish households estimated the secondary attack rate (SAR) of omicron compared to delta, finding it 1.2 times higher for unvaccinated people, 2.6 times higher for double-dosed, and 3.7 times higher for boosted. The authors conclude that ���the rapid spread of the Omicron VOC primarily can be ascribed to the immune evasiveness���.
According to UK statistics, the risk of hospitalization from omicron when unvaccinated is about the same as the wildtype virus, which is about half the risk of the delta variant.
The journal Infection Control Today reported that many experts are concerned that ������Omicron the Pandemic Killer��� Idea Ignores Dangers of Long COVID���:
Better masks work better���Linda Spaulding, RN-BC, CIC, CHEC, CHOP, a member of Infection Control Today�����s Editorial Advisory Board (EAB), says that she���s ���seen athletes in their 20s on the wait list for double lung transplants because of long COVID. That���s something that has long-term consequences. Some people talk of COVID fog. They just can���t put their thoughts together.��� In addition, even the treatments for those with long COVID can put toll on a patient���s body.���
���As noted by Kevin Kavanagh, MD, another member of ICT�����s EAB, a core difficulty in society���s attempt to guide COVID-19 from pandemic to endemic is that COVID is not just a respiratory virus. Kavanagh wrote in October that SARS-CoV-2 is similar to HIV because it can ���silently spread throughout the host���s body and attack almost every organ.������
The US Centers for Disease Control and Prevention (CDC) explains that:
���Loosely woven cloth products provide the least protection, layered finely woven products offer more protection, well-fitting disposable surgical masks and KN95s offer even more protection, and well-fitting NIOSH-approved respirators (including N95s) offer the highest level of protection.���
Unfortunately ���well-fitting disposable surgical masks��� do not exist out of the box, since there are large gaps on each side of the mask. Surgical masks require modifications to achive a good fit. That���s because they are made to stop liquid splashes during surgery, rather than made to stop airborne transmission. There are two methods shown by the CDC to improve fit:
Knot and Tuck: Tying the sides of the mask together to remove the side gap Double masking: Wearing a tight fitting cloth mask over a surgical maskResearch shows that both of these approaches dramatically reduce exposure to aerosols emitted during a period of breathing:
������adding a cloth mask over the source headform���s medical procedure mask or knotting and tucking the medical procedure mask reduced the cumulative exposure of the unmasked receiver by 82.2% (SD = 0.16) and 62.9% (SD = 0.08), respectively (Figure 2). When the source was unmasked and the receiver was fitted with the double mask or the knotted and tucked medical procedure mask, the receiver���s cumulative exposure was reduced by 83.0% (SD = 0.15) and 64.5% (SD = 0.03), respectively. When the source and receiver were both fitted with double masks or knotted and tucked masks, the cumulative exposure of the receiver was reduced 96.4% (SD = 0.02) and 95.9% (SD = 0.02), respectively.���
An airborne transmission simulator was used to estimate the ability of various types of face masks to block COVID-19 transmission. In this experiment, ���cotton mask led to an approximately 20% to 40% reduction in virus uptake compared to no mask. The N95 mask had the highest protective efficacy (approximately 80% to 90% reduction)���. All of the masks were much more effective at source control than at protecting the wearer, with the N95 stopping all detectable transmission.
The American Conference of Governmental Industrial Hygienists (ACGIH) say that ���workers need respirators���, noting that a worker with an ���N95 filtering facepiece respirator��� has 1-10% inward leakage and outward leakage���, but with a surgical mask ���has 50% inward leakage and outward leakage���, and with a cloth face covering ���has 75% inward leakage and outward leakage���. They explain that ���N95 FFRs have an assigned protection factor of 10 (10% inward leakage) but must receive a fit factor of 100 (1% inward leakage) on an individual worker.��� ACGIH created a table showing how, if we start with an assumption that it takes on average 15 minutes to get infected if no-one is wearing a mask (based on CDC contact tracing premises), we can calculate the time it would take on average to get infected if one or both of source and receiver are wearing various types of mask. This is calculated by simply dividing the base time of 15 minutes by the leakage factor for the source���s mask (if any), and then dividing that by the leakage factor for the receiver���s mask (if any).
This approach is, however, an over-simplification. Reseach based on a a single-hit model of infection shows that the probability of infection ���shows a highly nonlinear sensitivity��� to inhaled virus number. Therefore, ���In a virus-rich regime��� wearing a mask may not suffice to prevent infection.���
Research undertaken by the National Personal Protective Technology Laboratory (NPPTL) found that respirators with an exhalation valve ���reduce particle emissions to levels similar to or better than those provided by surgical masks, procedure masks, or cloth face coverings���. Furthermore, ���surgical tape secured over the valve from the inside of the FFR can provide source control similar to that of an FFR with no exhalation valve���.
Pushing back against masksProfessor Alison McMillan, Commonwealth Chief Nursing and Midwifery Officer in Australia claims that ���there is no evidence to suggest that we should be moving towards��� N95 respirators in the community setting.��� She added ���I am aware that there are some publications out there suggesting a move to N95 (masks). But that���s not supported in the empirical evidence���.
According to Norman Swan, host of the ABC���s Coronacast, ���If you���re wearing an N95 that hasn���t been fit tested ��� and it���s not an easy process to do yourself at home ��� there���s no guarantee that it���s an awful lot more effective than wearing a surgical mask. Professor Catherine Bennett, chair in epidemiology at Deakin University, claims that ���Technically, the instructions say you shouldn���t reuse��� respirators, and that ���If you���re not particularly checking its fit, you���re probably wasting your time���. Occupational environment physician Malcolm Sim agrees: ���If you put it [an N95 mask] off and put it on, they���re not meant for that purpose��� They���re easily damaged in somebody���s handbag,��� adding that the integrity of the masks can be compromised. He says that ���If you���re handling them a lot, taking them on and off, there���s much more potential for you to get it [the virus] on your hands, your face, different parts of your body.���
University of New South Wales epidemiologist Mary-Louise McLaws claimed that ���There���s no evidence yet that a N95 mask will protect you more than a surgical mask for Omicron.���
An opinion piece in Newsweek claims that ���the effectiveness of respirators is vastly overestimated, and there is scant evidence that they stop community transmission. Moreover, NIOSH-approved respirators are tight, uncomfortable, and can impede breathing.��� The article further claims that ���For respirators to work, they must be well fitting, must be tested by OSHA, and must be used for only short time windows as their effectiveness diminishes as they get wet from breathing.���
Recently there has been particular pushback against the use of masks by children, with the Newsweek article alleging that ���Respirators are not necessary to protect children from COVID-19 because of the astoundingly low risk COVID-19 presents to them���, and that in fact wearing masks involves ���existing well-documented harms���. There hasn���t been any documented harms to children from wearing masks,
Respirators can be reusedAccording to mask manufacturer 3M, respirators (which they refer to as ���Filtering Facepiece Respirators (FFRs)���) ���can be used many times.��� They say that ���There is no time limit to wearing an FFR. Respirators can be worn until they are dirty, damaged or difficult to breathe through.���
In reporting from CNN, Linsey Marr, a professor of civil and environmental engineering at Virginia Tech, explained that an N95 mask���s material and filtration ability aren���t ���going to degrade unless you physically rub it or poke holes in it. ���You���d have to be in really polluted air ��� for several days before it lost its ability to filter out particles. So, you can really wear them for a long time. People have been talking about 40 hours ��� I think that���s fine. Really, it���s going to get gross from your face or the straps will get too loose or maybe break before you���re going to lose filtration ability��� One of the first indicators of being able to change it if it looks nice and clean is that it just feels a little harder to breathe through. There appears to be more resistance with every breath.��� She also noted that the contamination risk in reusing N95 masks is ���lower, much lower, than the risk of you not wearing an N95 and breathing in particles���.
The CDC has prepared guidelines for optimizing the supply of respirators which recommend reusing respirators at most five times. This guidelines were created for people ���implementing policies and procedures for preventing pathogen transmission in healthcare settings���. They have been widely shared, incorrectly, by reporters as being recommendations for community use.
The inventor of N95 mask material, Peter Tsai, says that ���N95 masks can be rotated, 1 mask every 3���4 days���, and that in doing this ���there is no change in the mask���s properties.���
According to the NIOSH Guide to the Selection and Use of Particulate Respirators N95 respirators must maintain at least 95% filtration after a total mass loading of 200mg. This is designed to ensure they continue to work in sites with high particulate matter, such as some construction environment. However in normal use, even outside in a city with high levels of population, it would take over 200 days of 24 hour per day use to get to this level. The guide says that ���generally, the use and reuse of N-series �� lters would also be subject only to considerations of hygiene, damage, and increased breathing resistance���. The NIOSH guidelines are well supported by research.
Fit tests are not required for respirators to be effectiveIn one study non-experts were asked to read the instructions that come with a respirator, and then to don the respirator without assistance and complete a fit test. The average fit factor achieved was 88, and the lowest fit factor of the subjects was 15, with nearly half achieving a fit factor greater than 100.
Surgical masks have been found to have a much poorer fit in practice. One study showed that for surgical masks ���quantitative fit factors ranged from 2.5 to 9.6���, and another found an average fit factor of 3.0.
Guidance from the US Food and Drug Administration (FDA) explains that:
���Fit Factor is a means of expressing the difference in particle concentration inside the mask and outside the mask during use. For example, a fit factor of 2 means that the concentration of particles within the mask is �� or 50% of the concentration outside the mask; a fit factor of 5 means the concentration of particles within the mask is 1/5 th or 20% of the concentration outside the mask.���
The guidance says that failing to achieve a fit factor of 2 ���may suggest that respirator fit will not be sufficient to assure that the device will help reduce wearer exposure to pathogenic biological airborne particulates.���
An analysis of the fitted filtration efficiency (FFE) of surgical masks found that, unmodified, they only achieved an FFE of 38.5%. The ���knot and tuck��� technique improved that to 60.3%, and a DIY mask fitter consisting of three rubber bands increased it to 78.2%. A 3-layer cotton mask had an FFE of just 26.5%. An N95, on the other hand, achieved an FFE of 98.4%. Furthermore, the N95 FFE had a standard deviation of only 0.5% ��� that is, it was effective for multiple tests during ���a series of repeated movements of the torso, head, and facial muscles���. Interestingly, a 2-layer nylon mask had an FFE of 79.0% (standard devatiation 4.3%), showing that some cloth masks can be quite effective. These findings were replicated in a study of numerous types of cloth mask, which found that hybrids of 600 TPI cotton with silk, chiffon, or polypropelene achieved 72-96% filtration efficiency.
Researchers have calculated that ���the particle size most likely to deposit in the respiratory tract when wearing a mask is ���2��m���. Unfortunately, this particle size is not considered in N95 or similar standards. Instead, 0.3 ��m particles are used.
A 2010 study of fit testing respirators for public health medical emergencies found that 98% of non-experts wearing masks without training achieved a fit factor of over 5 (20% leakage) and 75% of them achieved a fit factor of over 10 (10% leakage).
Donning and doffing masks is not complex or riskyAnalysis by the CDC concludes that the risk of infection through surfaces (fomites) ���is generally considered to be low���, a view that was supported by the evidence as early as July 2020. An analysis of ���418 samples from mask fronts, cell phones, paper money, card machines, sewage, air and bedding��� during a COVID surge ���did not detect any trace of SARS-CoV-2 in all samples analyzed���.
We should not reserve respirators for healthcare workersAccording to Anne Miller, executive director of Project N95, there are many U.S. manufacturers of N95 masks and an ample supply.
The Economist reported that in Europe ���at the start of the pandemic, FFP2 masks were scarce and costly. Even governments fell victim to price gouging, paying more than ���4 ($4.50) per mask. Demand had previously been low, so stockpiles and production capacity could not satisfy the sudden surge. Governments wanted to reserve supplies for those most at risk of contracting the virus, such as health-care workers.��� However they reported that by the end of 2021 ���FFP2 masks are in healthy supply, and as the highly transmissible Omicron variant spreads across the world, updating guidance to recommend their wider use could be one way to help reduce transmission.���
In the first 6 months of 2020, over 70,000 new face mask companies were registered in China, many run by people with no previous experience and no registration or licensing. The Chinese government stepped in to make licensing more stringent, shutting down many companies, and international demand fell over quality concerns.
Due to ���a dramatic reduction in demand for N95s���, US mask factories are closing. In June 2021 the American Mask Manufacturer���s Association said that ���we have 28 members who are going to go out of business in the next 60 to 90 days.��� By July 2021 they estimated ���that 5,000 workers have been laid off across its member companies���. However following school mask mandates and demand during the omicron surge, demand in the US spiked in early 2022.
The CDC has found that 60% of KN95s are counterfeit.
In Australia it has been reported that ���general practitioners have been left without highly protective N95 masks as consumers rush to stock up after a sharp rise in COVID-19 cases.���
In May 2021 the CDC stated that ���The supply and availability of NIOSH-approved respirators have increased significantly over the last several months. Healthcare facilities should not be using crisis capacity strategies at this time and should promptly resume conventional practices.���
Demand distortions can increase as we proceed up the supply chain, creating inefficiencies for upstream firms. This is known as the Bullwhip Effect.
Respirators need not be uncomfortableIn an analysis of the physiological impact of the N95 filtering facepiece respirator (FFR) ���in healthy healthcare workers, FFR did not impose any important physiological burden during 1 hour of use, at realistic clinical work rates���.
A study of KF80, KF94, KF99, N95, and N99 masks found that self-reported comfort levels were nearly perfectly correlated with the ease of inhalation.
May 31, 2022
Qualitative humanities research is crucial to AI
���All research is qualitative; some is also quantitative���Harvard Social Scientist and Statistician Gary King
Suppose you wanted to find out whether a machine learning system being adopted - to recruit candidates, lend money, or predict future criminality - exhibited racial bias. You might calculate model performance across groups with different races. But how was race categorised��� through a census record, a police officer���s guess, or by an annotator? Each possible answer raises another set of questions. Following the thread of any seemingly quantitative issue around AI ethics quickly leads to a host of qualitative questions. Throughout AI, qualitative decisions are made about what metrics to optimise for, which categories to use, how to define their bounds, who applies the labels. Similarly, qualitative research is necessary to understand AI systems operating in society: evaluating system performance beyond what can be captured in short term metrics, understanding what is missed by large-scale studies (which can elide details and overlook outliers), and shedding light on the circumstances in which data is produced (often by crowd-sourced or poorly paid workers).
 Attempting to measure racial bias leads to qualitative questions
Attempting to measure racial bias leads to qualitative questions Unfortunately, there is often a large divide between computer scientists and social scientists, with over-simplified assumptions and fundamental misunderstandings of one another. Even when cross-disciplinary partnerships occur, they often fall into ���normal disciplinary divisions of labour: social scientists observe, data scientists make; social scientists do ethics, data scientists do science; social scientists do the incalculable, data scientists do the calculable.��� The solution is not for computer scientists to absorb a shallow understanding of the social sciences, but for deeper collaborations. In a paper on exclusionary practices in AI ethics, an interdisciplinary team wrote of the ���indifference, devaluation, and lack of mutual support between CS and humanistic social science (HSS), [which elevates] the myth of technologists as ���ethical unicorns��� that can do it all, though their disciplinary tools are ultimately limited.���
 There are challenges when mixing computer scientsits with social scientists. (Gallery Britto image under Creative Commons Attribution-Share Alike 4.0 International)
There are challenges when mixing computer scientsits with social scientists. (Gallery Britto image under Creative Commons Attribution-Share Alike 4.0 International) This is further reflected in an increasing number of job ads for AI ethicists that list a computer science degree as a requirement, ���prioritising technical computer science infrastructure over the social science skills that can evaluate AI���s social impact. In doing so, we are building the field of AI Ethics to replicate the very flaws this field is trying to fix.��� Interviews with 26 responsible AI practitioners working in industry highlighted a number of challenges, including that qualitative work was not prioritised. Not only is it impossible to fully understand ethics issues solely through quantitative metrics, inappropriate and misleading quantitative metrics are used to evaluate the responsible AI practitioners themselves. Interviewees reported that their fairness work was evaluated on metrics related to generating revenue, in a stark misalignment of goals.
Qualitative research helps us evaluate AI systems beyond short term metrics Small-scale qualitative studies tell an important story even (and perhaps especially) when they seem to contradict large-scale ���objective��� studies Qualitative research sheds light on the context of data annotation What next?Qualitative research helps us evaluate AI systems beyond short term metricsWhen companies like Google and YouTube want to test whether the recommendations they are making (in the form of search engine results or YouTube videos, for example) are ���good��� - they will often focus quite heavily on ���engagement��� or ���dwell time��� - the time a user spent looking at or watching the item recommended to them. But it turns out, unsurprisingly, that a focus on engagement and dwell time, narrowly understood, raises all sorts of problems. Demographics can impact dwell time (e.g. older users may spend longer on websites than younger users, just as part of the way they use the internet). A system that ���learns��� from a user���s behavioural cues (rather than their ���stated preferences���) might lock them into a limiting feedback loop, appealing to that user���s short term interests rather than those of their ���Better Selves.��� Scholars have called for more qualitative research to understand user experience and build this into the development of metrics.
This is the part where people will point out, rightly, that companies like Google and YouTube rely on a complex range of metrics and signals in their machine learning systems - and that where a website ranks on Google, or how a YouTube video performs in recommendation does not boil down to simple popularity metrics, like engagement. Google employs an extensive process to determine ���relevance��� and ���usefulness��� for search results. In its 172-page manual for search result ���Quality��� evaluation, for example, the company explains how evaluators should assess a website���s ���Expertise/ Authoritativeness/ Trustworthiness��� or ���E-A-T���; and what types of content, by virtue of its harmful nature (e.g., to protected groups), should be given a ���low��� ranking. YouTube has identified specific categories of content (such as news, scientific subjects, and historical information) for which ���authoritativeness��� should be considered especially important. It has also determined that dubious-but-not-quite-rule-breaking information (what it calls ���borderline content���) should not be recommended, regardless of the video���s engagement levels.
Irrespective of how successful we consider the existing approaches of Google Search and YouTube to be (and partly, the issue is that evaluating their implementation from the outside is frustratingly difficult), the point here is that there are constant qualitative judgments being made, about what makes a search result or recommendation ���good��� and of how to define and quantify expertise, authoritativeness, trustworthiness, borderline content, and other values. This is true of all machine learning evaluation, even when it isn���t explicit. In a paper guiding companies about how to carry out internal audits of their AI systems, Inioluwa Deborah Raji and colleagues emphasise the importance of interviews with management and engineering teams to ���capture and pay attention to what falls outside the measurements and metrics, and to render explicit the assumptions and values the metrics apprehend.��� (p.40).
The importance of thoughtful humanities research is heightened if we are serious about grappling with the potential broader social effects of machine learning systems (both good and bad), which are often delayed, distributed and cumulative.
Small-scale qualitative studies tell an important story even (and perhaps especially) when they seem to contradict large-scale ���objective��� studiesHypothetically, let���s say you wanted to find out whether the use of AI technologies by doctors during a medical appointment would make doctors less attentive to patients - what do you think the best way of doing it would be? You could find some criteria and method for measuring ���attentiveness���, say tracking the amount of eye contact between the doctor and patient, and analyse this across a representative sample of medical appointments where AI technologies were being used, compared to a control group of medical appointments where AI technologies weren���t being used. Or would you interview doctors about their experiences using the technology during appointments? Or talk to patients about how they felt the technology did, or didn���t, impact their experience?
In research circles, we describe these as ���epistemological��� choices - your judgement of what constitutes the ���best��� approach is inextricably linked to your judgement about how we can claim to ���know��� something. These are all valid methods for approaching the question, but you can imagine how they might result in different, even conflicting, insights. For example, you might end up with the following results:
The eye contact tracking experiment suggests that overall, there is no significant difference in doctors��� attentiveness to the patient when the AI tech is introduced. The interviews with doctors and patients reveal that some doctors and patients feel that the AI technology reduces doctors��� attentiveness to patients, and others feel that it makes no difference or even increases doctors��� attention to the patient.Even if people are not negatively impacted by something ���on average��� (e.g., in our hypothetical eye contact tracking experiment above), there will remain groups of people who will experience negative impacts, perhaps acutely so. ���Many of people���s most pressing questions are about effects that vary for different people,��� write Matias, Pennington and Chan in a recent paper on the idea of N-of-one trials. To tell people that their experiences aren���t real or valid because they don���t meet some threshold for statistical significance across a large population doesn���t help us account for the breadth and nature of AI���s impacts on the world.
Examples of this tension between competing claims to knowledge about AI systems��� impacts abound. Influencers who believe they are being systematically downranked (���shadowbanned���) by Instagram���s algorithmic systems are told by Instagram that this simply isn���t true. Given the inscrutability of these proprietary algorithmic systems, it is impossible for influencers to convincingly dispute Instagram���s claims. Kelley Cotter refers to this as a form of ���black box gaslighting���: platforms can ���leverage perceptions of their epistemic authority on their algorithms to undermine users��� confidence in what they know about algorithms and destabilise credible criticism.��� Her interviews with influencers give voice to stakeholder concerns and perspectives that are elided in Instagram���s official narrative about its systems. The mismatch between different stakeholders��� accounts of ���reality��� is instructive. For example, a widely-cited paper by Netflix employees claims that Netflix recommendation ���influences choice for about 80% of hours streamed at Netflix.��� But this claim stands in stark contrast to Mattias Frey���s mixed-methods research (representative survey plus small sample for interviews) run with UK and US adults, in which less than 1 in 5 adults said they primarily relied on Netflix recommendations when deciding what films to watch. Even if this is because users underestimate their reliance on recommender systems, that���s a critically important finding - particularly when we���re trying to regulate recommendation and so many are advocating providing better user-level controls as a check on platform power. Are people really going to go to the trouble of changing their settings if they don���t think they rely on algorithmic suggestions that much anyway?
Qualitative research sheds light on the context of data annotationMachine learning systems rely on vast amounts of data. In many cases, for that data to be useful, it needs to be labelled/ annotated. For example, a hate speech classifier (an AI-enabled tool used to identify and flag potential cases of hate speech on a website) relies on huge datasets of text labelled as ���hate speech��� or ���not hate speech��� to ���learn��� how to spot hate speech. But it turns out that who is doing the annotating and in what context they���re doing it, matters. AI-powered content moderation is often held up as the solution to harmful content online. What has continued to be underplayed is the extent to which those automated systems are and most likely will remain dependent on the manual work of human content moderators sifting through some of the worst and most traumatic online material to power the machine learning datasets on which automated content moderation depends. Emily Denton and her colleagues highlight the significance of annotators��� social identity (e.g., race, gender) and their expertise when it comes to annotation tasks, and they point out the risks associated with overlooking these factors and simply ���aggregating��� results as ���ground truth��� rather than properly exploring disagreements between annotators and the important insights that this kind of disagreement might offer.
 Behind the Screen, by Sarah T. Roberts, and Netflix Reccomends, by Mattias Frey
Behind the Screen, by Sarah T. Roberts, and Netflix Reccomends, by Mattias Frey Human commercial content moderators (such as the people that identify and remove violent and traumatic imagery on Facebook) often labour in terrible conditions, lacking psychological support or appropriate financial compensation. The interview-based research of Sarah T. Roberts has been pioneering in highlighting these conditions. Most demand for crowdsourced digital labour comes from the Global North, yet the majority of these workers are based in the Global South and receive low wages. Semi-structured interviews reveal the extent to which workers feel unable to bargain effectively for better pay in the current regulatory environment. As Mark Graham and his colleagues point out, these findings are hugely important in a context where several governments and supranational development organisations like the World Bank are holding up digital work as a promising tool to fight poverty.
The decision of how to measure ���race��� in machine learning systems is highly consequential, especially in the context of existing efforts to evaluate these systems for their ���fairness.��� Alex Hanna, Emily Denton, Andrew Smart and Jamila Smith-Loud have done crucial work highlighting the limitation of machine learning systems that rely on official records of race or their proxies (e.g. census records), noting that the racial categories provided by such records are ���unstable, contingent, and rooted in racial inequality.��� The authors emphasise the importance of conducting research in ways that prioritise the perspectives of the marginalised racial communities that fairness metrics are supposed to protect. Qualitative research is ideally placed to contribute to a consideration of ���race��� in machine learning systems that is grounded in the lived experiences and needs of the racially subjugated.
What next?Collaborations between quantitative and qualitative researchers are valuable in understanding AI ethics from all angles.
Consider reading more broadly, outside your particular area. Perhaps using the links and researchers listed here as starting points. They���re just a sliver of the wealth that���s out there. You could also check out the Social Media Collective���s Critical Algorithm Studies reading list, the reading list provided by the LSE Digital Ethnography Collective, and Catherine Yeo���s suggestions.
Strike up conversations with researchers in other fields, and consider the possibility of collaborations. Find a researcher slightly outside your field but whose work you broadly understand and like, and follow them on Twitter. With any luck, they will share more of their work and help you identify other researchers to follow. Collaboration can be an incremental process: Consider inviting the researcher to form part of a discussion panel, reach out to say what you liked and appreciated about their work and why, and share your own work with them if you think it���s aligned with their interests.
Within your university or company, is there anything you could do to better reward or facilitate interdisciplinary work? As Humanities Computing Professor Willard McCarty notes, somewhat discouragingly, ���professional reward for genuinely interdisciplinary research is rare.��� To be sure, individual researchers and practitioners have to be prepared to put themselves out there, compromise and challenge themselves - but carefully tailored institutional incentives and enablers matter.
Qualitative humanities research is crucial to AI
���All research is qualitative; some is also quantitative���Harvard Social Scientist and Statistician Gary King
Suppose you wanted to find out whether a machine learning system being adopted - to recruit candidates, lend money, or predict future criminality - exhibited racial bias. You might calculate model performance across groups with different races. But how was race categorised��� through a census record, a police officer���s guess, or by an annotator? Each possible answer raises another set of questions. Following the thread of any seemingly quantitative issue around AI ethics quickly leads to a host of qualitative questions. Throughout AI, qualitative decisions are made about what metrics to optimise for, which categories to use, how to define their bounds, who applies the labels. Similarly, qualitative research is necessary to understand AI systems operating in society: evaluating system performance beyond what can be captured in short term metrics, understanding what is missed by large-scale studies (which can elide details and overlook outliers), and shedding light on the circumstances in which data is produced (often by crowd-sourced or poorly paid workers).
 Attempting to measure racial bias leads to qualitative questions
Attempting to measure racial bias leads to qualitative questions Unfortunately, there is often a large divide between computer scientists and social scientists, with over-simplified assumptions and fundamental misunderstandings of one another. Even when cross-disciplinary partnerships occur, they often fall into ���normal disciplinary divisions of labour: social scientists observe, data scientists make; social scientists do ethics, data scientists do science; social scientists do the incalculable, data scientists do the calculable.��� The solution is not for computer scientists to absorb a shallow understanding of the social sciences, but for deeper collaborations. In a paper on exclusionary practices in AI ethics, an interdisciplinary team wrote of the ���indifference, devaluation, and lack of mutual support between CS and humanistic social science (HSS), [which elevates] the myth of technologists as ���ethical unicorns��� that can do it all, though their disciplinary tools are ultimately limited.���
 There are challenges when mixing computer scientsits with social scientists. (Gallery Britto image under Creative Commons Attribution-Share Alike 4.0 International)
There are challenges when mixing computer scientsits with social scientists. (Gallery Britto image under Creative Commons Attribution-Share Alike 4.0 International) This is further reflected in an increasing number of job ads for AI ethicists that list a computer science degree as a requirement, ���prioritising technical computer science infrastructure over the social science skills that can evaluate AI���s social impact. In doing so, we are building the field of AI Ethics to replicate the very flaws this field is trying to fix.��� Interviews with 26 responsible AI practitioners working in industry highlighted a number of challenges, including that qualitative work was not prioritised. Not only is it impossible to fully understand ethics issues solely through quantitative metrics, inappropriate and misleading quantitative metrics are used to evaluate the responsible AI practitioners themselves. Interviewees reported that their fairness work was evaluated on metrics related to generating revenue, in a stark misalignment of goals.
Qualitative research helps us evaluate AI systems beyond short term metrics Small-scale qualitative studies tell an important story even (and perhaps especially) when they seem to contradict large-scale ���objective��� studies Qualitative research sheds light on the context of data annotation What next?Qualitative research helps us evaluate AI systems beyond short term metricsWhen companies like Google and YouTube want to test whether the recommendations they are making (in the form of search engine results or YouTube videos, for example) are ���good��� - they will often focus quite heavily on ���engagement��� or ���dwell time��� - the time a user spent looking at or watching the item recommended to them. But it turns out, unsurprisingly, that a focus on engagement and dwell time, narrowly understood, raises all sorts of problems. Demographics can impact dwell time (e.g. older users may spend longer on websites than younger users, just as part of the way they use the internet). A system that ���learns��� from a user���s behavioural cues (rather than their ���stated preferences���) might lock them into a limiting feedback loop, appealing to that user���s short term interests rather than those of their ���Better Selves.��� Scholars have called for more qualitative research to understand user experience and build this into the development of metrics.
This is the part where people will point out, rightly, that companies like Google and YouTube rely on a complex range of metrics and signals in their machine learning systems - and that where a website ranks on Google, or how a YouTube video performs in recommendation does not boil down to simple popularity metrics, like engagement. Google employs an extensive process to determine ���relevance��� and ���usefulness��� for search results. In its 172-page manual for search result ���Quality��� evaluation, for example, the company explains how evaluators should assess a website���s ���Expertise/ Authoritativeness/ Trustworthiness��� or ���E-A-T���; and what types of content, by virtue of its harmful nature (e.g., to protected groups), should be given a ���low��� ranking. YouTube has identified specific categories of content (such as news, scientific subjects, and historical information) for which ���authoritativeness��� should be considered especially important. It has also determined that dubious-but-not-quite-rule-breaking information (what it calls ���borderline content���) should not be recommended, regardless of the video���s engagement levels.
Irrespective of how successful we consider the existing approaches of Google Search and YouTube to be (and partly, the issue is that evaluating their implementation from the outside is frustratingly difficult), the point here is that there are constant qualitative judgments being made, about what makes a search result or recommendation ���good��� and of how to define and quantify expertise, authoritativeness, trustworthiness, borderline content, and other values. This is true of all machine learning evaluation, even when it isn���t explicit. In a paper guiding companies about how to carry out internal audits of their AI systems, Inioluwa Deborah Raji and colleagues emphasise the importance of interviews with management and engineering teams to ���capture and pay attention to what falls outside the measurements and metrics, and to render explicit the assumptions and values the metrics apprehend.��� (p.40).
The importance of thoughtful humanities research is heightened if we are serious about grappling with the potential broader social effects of machine learning systems (both good and bad), which are often delayed, distributed and cumulative.
Small-scale qualitative studies tell an important story even (and perhaps especially) when they seem to contradict large-scale ���objective��� studiesHypothetically, let���s say you wanted to find out whether the use of AI technologies by doctors during a medical appointment would make doctors less attentive to patients - what do you think the best way of doing it would be? You could find some criteria and method for measuring ���attentiveness���, say tracking the amount of eye contact between the doctor and patient, and analyse this across a representative sample of medical appointments where AI technologies were being used, compared to a control group of medical appointments where AI technologies weren���t being used. Or would you interview doctors about their experiences using the technology during appointments? Or talk to patients about how they felt the technology did, or didn���t, impact their experience?
In research circles, we describe these as ���epistemological��� choices - your judgement of what constitutes the ���best��� approach is inextricably linked to your judgement about how we can claim to ���know��� something. These are all valid methods for approaching the question, but you can imagine how they might result in different, even conflicting, insights. For example, you might end up with the following results:
The eye contact tracking experiment suggests that overall, there is no significant difference in doctors��� attentiveness to the patient when the AI tech is introduced. The interviews with doctors and patients reveal that some doctors and patients feel that the AI technology reduces doctors��� attentiveness to patients, and others feel that it makes no difference or even increases doctors��� attention to the patient.Even if people are not negatively impacted by something ���on average��� (e.g., in our hypothetical eye contact tracking experiment above), there will remain groups of people who will experience negative impacts, perhaps acutely so. ���Many of people���s most pressing questions are about effects that vary for different people,��� write Matias, Pennington and Chan in a recent paper on the idea of N-of-one trials. To tell people that their experiences aren���t real or valid because they don���t meet some threshold for statistical significance across a large population doesn���t help us account for the breadth and nature of AI���s impacts on the world.
Examples of this tension between competing claims to knowledge about AI systems��� impacts abound. Influencers who believe they are being systematically downranked (���shadowbanned���) by Instagram���s algorithmic systems are told by Instagram that this simply isn���t true. Given the inscrutability of these proprietary algorithmic systems, it is impossible for influencers to convincingly dispute Instagram���s claims. Kelley Cotter refers to this as a form of ���black box gaslighting���: platforms can ���leverage perceptions of their epistemic authority on their algorithms to undermine users��� confidence in what they know about algorithms and destabilise credible criticism.��� Her interviews with influencers give voice to stakeholder concerns and perspectives that are elided in Instagram���s official narrative about its systems. The mismatch between different stakeholders��� accounts of ���reality��� is instructive. For example, a widely-cited paper by Netflix employees claims that Netflix recommendation ���influences choice for about 80% of hours streamed at Netflix.��� But this claim stands in stark contrast to Mattias Frey���s mixed-methods research (representative survey plus small sample for interviews) run with UK and US adults, in which less than 1 in 5 adults said they primarily relied on Netflix recommendations when deciding what films to watch. Even if this is because users underestimate their reliance on recommender systems, that���s a critically important finding - particularly when we���re trying to regulate recommendation and so many are advocating providing better user-level controls as a check on platform power. Are people really going to go to the trouble of changing their settings if they don���t think they rely on algorithmic suggestions that much anyway?
Qualitative research sheds light on the context of data annotationMachine learning systems rely on vast amounts of data. In many cases, for that data to be useful, it needs to be labelled/ annotated. For example, a hate speech classifier (an AI-enabled tool used to identify and flag potential cases of hate speech on a website) relies on huge datasets of text labelled as ���hate speech��� or ���not hate speech��� to ���learn��� how to spot hate speech. But it turns out that who is doing the annotating and in what context they���re doing it, matters. AI-powered content moderation is often held up as the solution to harmful content online. What has continued to be underplayed is the extent to which those automated systems are and most likely will remain dependent on the manual work of human content moderators sifting through some of the worst and most traumatic online material to power the machine learning datasets on which automated content moderation depends. Emily Denton and her colleagues highlight the significance of annotators��� social identity (e.g., race, gender) and their expertise when it comes to annotation tasks, and they point out the risks associated with overlooking these factors and simply ���aggregating��� results as ���ground truth��� rather than properly exploring disagreements between annotators and the important insights that this kind of disagreement might offer.
 Behind the Screen, by Sarah T. Roberts, and Netflix Reccomends, by Mattias Frey
Behind the Screen, by Sarah T. Roberts, and Netflix Reccomends, by Mattias Frey Human commercial content moderators (such as the people that identify and remove violent and traumatic imagery on Facebook) often labour in terrible conditions, lacking psychological support or appropriate financial compensation. The interview-based research of Sarah T. Roberts has been pioneering in highlighting these conditions. Most demand for crowdsourced digital labour comes from the Global North, yet the majority of these workers are based in the Global South and receive low wages. Semi-structured interviews reveal the extent to which workers feel unable to bargain effectively for better pay in the current regulatory environment. As Mark Graham and his colleagues point out, these findings are hugely important in a context where several governments and supranational development organisations like the World Bank are holding up digital work as a promising tool to fight poverty.
The decision of how to measure ���race��� in machine learning systems is highly consequential, especially in the context of existing efforts to evaluate these systems for their ���fairness.��� Alex Hanna, Emily Denton, Andrew Smart and Jamila Smith-Loud have done crucial work highlighting the limitation of machine learning systems that rely on official records of race or their proxies (e.g. census records), noting that the racial categories provided by such records are ���unstable, contingent, and rooted in racial inequality.��� The authors emphasise the importance of conducting research in ways that prioritise the perspectives of the marginalised racial communities that fairness metrics are supposed to protect. Qualitative research is ideally placed to contribute to a consideration of ���race��� in machine learning systems that is grounded in the lived experiences and needs of the racially subjugated.
What next?Collaborations between quantitative and qualitative researchers are valuable in understanding AI ethics from all angles.
Consider reading more broadly, outside your particular area. Perhaps using the links and researchers listed here as starting points. They���re just a sliver of the wealth that���s out there. You could also check out the Social Media Collective���s Critical Algorithm Studies reading list, the reading list provided by the LSE Digital Ethnography Collective, and Catherine Yeo���s suggestions.
Strike up conversations with researchers in other fields, and consider the possibility of collaborations. Find a researcher slightly outside your field but whose work you broadly understand and like, and follow them on Twitter. With any luck, they will share more of their work and help you identify other researchers to follow. Collaboration can be an incremental process: Consider inviting the researcher to form part of a discussion panel, reach out to say what you liked and appreciated about their work and why, and share your own work with them if you think it���s aligned with their interests.
Within your university or company, is there anything you could do to better reward or facilitate interdisciplinary work? As Humanities Computing Professor Willard McCarty notes, somewhat discouragingly, ���professional reward for genuinely interdisciplinary research is rare.��� To be sure, individual researchers and practitioners have to be prepared to put themselves out there, compromise and challenge themselves - but carefully tailored institutional incentives and enablers matter.
May 16, 2022
AI Harms are Societal, Not Just Individual
When the USA government switched to facial identification service ID.me for unemployment benefits, the software failed to recognize Bill Baine���s face. While the app said that he could have a virtual appointment to be verified instead, he was unable to get through. The screen had a wait time of 2 hours and 47 minutes that never updated, even over the course of weeks. He tried calling various offices, his daughter drove in from out of town to spend a day helping him, and yet he was never able to get a useful human answer on what he was supposed to do, as he went for months without unemployment benefits. In Baine���s case, it was eventually resolved when a journalist hypothesized that the issue was a spotty internet connection, and that Baine would be better off traveling to another town to use a public library computer and internet. Even then, it still took hours for Baine to get his approval.
 Journalist Andrew Kenney of Colorado Public Radio has covered the issues with ID.me
Journalist Andrew Kenney of Colorado Public Radio has covered the issues with ID.me Baine was not alone. The number of people receiving unemployment benefits plummeted by 40% in the 3 weeks after ID.me was introduced. Some of these were presumed to be fraudsters, but it is unclear how many genuine people in need of benefits were wrongly harmed by this. These are individual harms, but there are broader, societal harms as well: the cumulative costs of the public having to spend ever more time on hold, trying to navigate user-hostile automated bureaucracies where they can���t get the answers they need. There is the societal cost of greater inequality and greater desperation, as more people are plunged into poverty through erroneous denial of benefits. And there is the undermining of trust in public services, which can be difficult to restore.
Potential for algorithmic harm takes many forms: loss of opportunity (employment or housing discrimination), economic cost (credit discrimination, narrowed choices), social detriment (stereotype confirmation, dignitary harms), and loss of liberty (increased surveillance, disproportionate incarceration). And each of these four categories manifests in both individual and societal harms.
It should come as no surprise that algorithmic systems can give rise to societal harm. These systems are sociotechnical: they are designed by humans and teams that bring their values to the design process, and algorithmic systems continually draw information from, and inevitably bear the marks of, fundamentally unequal, unjust societies. In the context of COVID-19, for example, policy experts warned that historical healthcare inequities risked making their way into the datasets and models being used to predict and respond to the pandemic. And while it���s intuitively appealing to think of large-scale systems as creating the greatest risk of societal harm, algorithmic systems can create societal harm because of the dynamics set off by their interconnection with other systems/ players, like advertisers, or commercially-driven media, and the ways in which they touch on sectors or spaces of public importance.
Still, in the west, our ideas of harm are often anchored to an individual being harmed by a particular action at a discrete moment in time. As law scholar Natalie Smuha has powerfully argued, legislation (both proposed and passed) in Western countries to address algorithmic risks and harms often focuses on individual rights: regarding how an individual���s data is collected or stored, to not be discriminated against, or to know when AI is being used. Even metrics used to evaluate the fairness of algorithms are often aggregating across individual impacts, but unable to capture longer-term, more complex, or second- and third-order societal impacts.
Case Study: Privacy and surveillanceConsider the over-reliance on individual harms in discussing privacy: so often focused on whether individual users have the ability to opt in or out of sharing their data, notions of individual consent, or proposals that individuals be paid for their personal data. Yet widespread surveillance fundamentally changes society: people may begin to self-censor and to be less willing (or able) to advocate for justice or social change. Professor Alvaro Bedoya, director of the Center on Privacy and Technology at the Georgetown University Law Center, traces a history of how surveillance has been used by the state to try to shut down movements for progress��� targeting religious minorities, poor people, people of color, immigrants, sex workers and those considered ���other���. As Maciej Ceglowski writes, ���Ambient privacy is not a property of people, or of their data, but of the world around us��� Because our laws frame privacy as an individual right, we don���t have a mechanism for deciding whether we want to live in a surveillance society.���
Drawing on interviews with African data experts, Birhane et al write that even when data is anonymized and aggregated, it ���can reveal information on the community as a whole. While notions of privacy often focus on the individual, there is growing awareness that collective identity is also important within many African communities, and that sharing aggregate information about communities can also be regarded as a privacy violation.��� Recent US-based scholarship has also highlighted the importance of thinking about group level privacy (whether that group is made up of individuals who identify as members of that group, or whether it���s a ���group��� that is algorithmically determined - like individuals with similar shopping habits on Amazon). Because even aggregated anonymised data can reveal important group-level information (e.g., the location of military personnel training via exercise tracking apps) ���managing privacy���, these authors argue ���is often not intrapersonal but interpersonal.��� And yet legal and tech design privacy solutions are often better geared towards assuring individual-level privacy than negotiating group privacy.
Case Study: Disinformation and erosion of trustAnother example of a collective societal harm comes from how technology platforms such as Facebook have played a significant role in elections ranging from the Philippines to Brazil, yet it can be difficult (and not necessarily possible or useful) to quantify exactly how much: something as complex as a country���s political system and participation involves many interlinking factors. But when ���deep fakes��� make it ���possible to create audio and video of real people saying and doing things they never said or did��� or when motivated actors successfully game search engines to amplify disinformation, the (potential) harm that is generated is societal, not just individual. Disinformation and the undermining of trust in institutions and fellow citizens have broad impacts, including on individuals who never use social media.
 Reports and Events on Regulatory Approaches to Disinformation
Reports and Events on Regulatory Approaches to Disinformation Efforts by national governments to deal with the problem through regulation have not gone down well with everyone. ���Disinformation��� has repeatedly been highlighted as one of the tech-enabled ���societal harms��� that the UK���s Online Safety Bill or the EU���s Digital Services Act should address, and a range of governments are taking aim at the problem by proposing or passing a slew of (in certain cases ill-advised) ���anti-misinformation��� laws. But there���s widespread unease around handing power to governments to set standards for what counts as ���disinformation���. Does reifying ���disinformation��� as a societal harm become a legitimizing tool for governments looking to silence political dissent or undermine their weaker opponents? It���s a fair and important concern - and yet simply leaving that power in the hands of mostly US-based, unaccountable tech companies is hardly a solution. What are the legitimacy implications if a US company like Twitter were to ban democratically elected Brazilian President Jair Bolsonaro for spreading disinformation, for example? How do we ensure that tech companies are investing sufficiently in governance efforts across the globe, rather than responding in an ad hoc manner to proximal (i.e. mostly US-based) concerns about disinformation? Taking a hands off approach to platform regulation doesn���t make platforms��� efforts to deal with disinformation any less politically fraught.
Individual Harms, Individual SolutionsIf we consider individual solutions our only option (in terms of policy, law, or behavior), we often limit the scope of the harms we can recognize or the nature of the problems we face. To take an example not related to AI: Oxford professor Trish Greenhalgh et al analyzed the slow reluctance of leaders in the West to accept that covid is airborne (e.g. it can linger and float in the air, similar to cigarette smoke, requiring masks and ventilation to address), rather than droplet dogma (e.g. washing your hands is a key precaution). One reason they highlight is the Western framing of individual responsibility as the solution to most problems. Hand-washing is a solution that fits the idea of individual responsibility, whereas collective responsibility for the quality of shared indoor air does not. The allowable set of solutions helps shape what we identify as a problem. Additionally, the fact that recent research suggests that ���the level of interpersonal trust in a society��� was a strong predictor of which countries managed COVID-19 most successfully should give us pause. Individualistic framings can limit our imagination about the problems we face and which solutions are likely to be most impactful.
Parallels with Environmental HarmsBefore the passage of environmental laws, many existing legal frameworks were not well-suited to address environmental harms. Perhaps a chemical plant releases waste emissions into the air once per week. Many people in surrounding areas may not be aware that they are breathing polluted air, or may not be able to directly link air pollution to a new medical condition, such as asthma, (which could be related to a variety of environmental and genetic factors).
 There are parallels between air polllution and algorithmic harms
There are parallels between air polllution and algorithmic harms There are many parallels between environmental issues and AI ethics. Environmental harms include individual harms for people who develop discrete health issues from drinking contaminated water or breathing polluted air. Yet, environmental harms are also societal: the societal costs of contaminated water and polluted air can reverberate in subtle, surprising, and far-reaching ways. As law professor Nathalie Smuha writes, environmental harms are often accumulative and build over time. Perhaps each individual release of waste chemicals from a refinery has little impact on its own, but adds up to be significant. In the EU, environmental law allows for mechanisms to show societal harm, as it would be difficult to challenge many environmental harms on the basis of individual rights. Smuha argues that there are many similarities with AI ethics: for opaque AI systems, spanning over time, it can be difficult to prove a direct causal relationship to societal harm.
Directions ForwardTo a large extent our message is to tech companies and policymakers. It���s not enough to focus on the potential individual harms generated by tech and AI: the broader societal costs of tech and AI matter.
But those of us outside tech policy circles have a crucial role to play. One way in which we can guard against the risks of the ���societal harm��� discourse being co-opted by those with political power to legitimise undue interference and further entrench their power is by claiming the language of ���societal harm��� as the democratic and democratising tool it can be. We all lose when we pretend societal harms don���t exist, or when we acknowledge they exist but throw our hands up. And those with the least power, like Bill Baine, are likely to suffer a disproportionate loss.
In his newsletter on Tech and Society, L.M. Sacasas encourages people to ask themselves 41 questions before using a particular technology. They���re all worth reading and thinking about - but we���re listing a few especially relevant ones to get you started. Next time you sit down to log onto social media, order food online, swipe right on a dating app or consider buying a VR headset, ask yourself:
How does this technology empower me? At whose expense? (Q16) What feelings does the use of this technology generate in me toward others? (Q17) What limits does my use of this technology impose upon others? (Q28) What would the world be like if everyone used this technology exactly as I use it? (Q37) Does my use of this technology make it easier to live as if I had no responsibilities toward my neighbor? (Q40) Can I be held responsible for the actions which this technology empowers? Would I feel better if I couldn���t? (Q41)It���s on all of us to sensitise ourselves to the societal implications of the tech we use.
Jeremy Howard's Blog

- Jeremy Howard's profile
- 42 followers

