
Sedat Kapanoglu's Blog
April 16, 2024
IPv6 for the remotely interested
I’ve known about IPv6 for the last two decades or so, but I’ve never gone beyond “an overengineered solution to the IPv4 address space problem”. IPv6 was even presented as “every atom could get its own IP address, no IP address shortages anymore”, but I didn’t know how true that was either. I occasionally saw an IPv6 address here and there because almost every device supports IPv6 today. I believe cellular network operators even default to it, so you’re probably reading this on a device that uses IPv6.
Last week, I decided to learn about how IPv6 works under the hood, and I’ve learned quite a few interesting facts about it.
Disclaimer: I’m not an expert on IPv6 or network engineering in general. This is the outcome of my personal reading journey over the last few weeks, and I’d love to be corrected if I made any mistakes. Read on :)
IPv6 vs IPv4The name IPv6 used to confuse me because I thought IPv4 took its name from the four octets it used to represent 32-bits, so, IPv6 should have been called IP16. But I learned that it was really the version of the protocol. There were apparently IPv1, IPv2, and IPv3 before IPv4 came out. They were used to research the IP protocol internally, and later got replaced with IPv4 we use today. There was even a proposal for IPv5 in the 80’s that was intended to optimize realtime communications, but got discarded in favor of IPv6 which additionally solved the address space problem. That’s why IPv6 is called IPv6. It’s literally IP Version 6. There have even been attempts at creating IPv7, IPv8 and more, but all have been either obsoleted or shelved.
Like IPv4, IPv6 protocol has an addressing scheme. IPv6 uses 128-bits for addresses instead of 32-bit IPv4 addresses. But, the difference in protocols are greater than address space sizes. Actually, IPv6 feels like an alien tech if you’ve only worked with IPv4 so far when you look at its quirky features such as:
IPv6 has no subnet masksIPv6 supports CIDR addressing like IPv4, but from a user’s perspective, IPv6 addresses are way simpler: first half is Internet (global), the second half is local. That’s the suggested way to use IPv6 addresses anyway. So, when you visit a whatismyipwhatever web site, it shows your IP address like this:
1111:2222:3333:4444:5555:6666:7777:8888
But, your ISP only knows you as 1111:2222:3333:4444 and assigns that portion (/64) to you. The remaining half of the address is unique for every device on your network. ISP just forwards any packet that starts with 1111:2222:3333:4444 to your router, and your router transfers the packet to the device. So, the second half of the address, 5555:6666:7777:8888, let’s call that part INTERFACE_ID from now on, is unique to your device. That means, every device you have has a unique IPv6 address, and can be accessed individually from anywhere in the world, because:
IPv6 has no NATI used to think that you could do NAT with IPv6, but nobody did it because of potential backlash from HackerNews community. Apparently, that’s not the case. There’s apparently no published standard for NAT for IPv6. There is a draft proposal called NAT66, but it hasn’t materialized.
NAT isn’t needed with IPv6 because it’s possible to have a separate globally accessible address for every device on Earth. That felt weird to me because NAT, despite how much you hate it when you want to play games online, gives you that warm feeling that your local devices are never accessible from outside unless you explicitly allow it using UPnP or port forwarding. It has that false sense of security which is really hard to shake off.
The bitter truth is, NAT isn’t a security barrier. It’s just an alternative packet forwarding mechanism. Your IPv6 router should never forward connection attempts from outside to your local devices by default anyway. So, you get the same security without having NAT at all. As a matter of fact, it’s fascinating that you’re able to access every device on your local network with their IPv6 address without having to go through your router, or a separate VPN configuration if you wish to do so: just authenticate, that’s it. Hypothetically, a smart toothbrush in Istanbul, Turkey can connect directly to a temperature sensor in Ontario, Canada, and create one of the most diverse botnets on the planet.
There is a security related catch with IPv6 though that comes with the luxury of having a separate IPv6 address per device: your devices can be fingerprinted and tracked individually. That’s bad for privacy. So, modern OS’s invented the concept of temporary IPv6 addresses that change INTERFACE_ID periodically. You can use your permanent IPv6 address for listening to connections from outside, but when establishing connections, your IPv6 address is shown with that secondary temporary address that changes frequently.
Now, having mentioned not needing to go through hoops for access, another interesting feature of IPv6 is:
IPv6 addresses are self-configuredIPv6 protocol doesn’t need a DHCP server, or manual network configuration to determine IP address, subnet mask, and gateway address. A device can get an IP address without asking a centralized server. That is accomplished by a protocol called SLAAC. It gradually builds a device’s IPv6 address by following these steps:
The operating system (specifically, the IPv6 stack of the OS) generates a 64-bit device identifier, usually random, let’s say 5555:6666:7777:8888 (chosen by a fair dice roll), and that makes up the INTERFACE_ID portion of your IPv6 address.The OS prefixes the INTERFACE_ID with fe80, the local only IPv6 network prefix. So, your IPv6 address is now: fe80::5555:6666:7777:8888. (Notice the “a::b” syntax; it means “there are all zero valued segments between ‘a’ and ‘b’”. More on that later)Your device now sends a packet to its designated neighbor multicast group on the local network to make sure that nobody else is using the same IPv6 address. That’s called Duplicate Address Detection (DAD). The chances of a duplicate address getting assigned is less than universe suddenly imploding due to a cataclysmic event, but that’s exactly when you don’t want to deal with duplicate IPv6 addresses and miss all the fun.Finally, the device sends the router (which, unlike IPv4, can always be reached with the multicast group address on IPv6 ff02::2) its acquired local address and asks for the actual prefix the router uses by sending a RS (Router Solicitation) ICMPv6 packet. After router responds with an RA (Router Advertisement) packet, it replaces fe80 with the actual prefix the router replies with, and starts using that as its permanent address. That’s now your IPv6 internet address.The advantage of stateless configuration is the reduced overhead on your router: it doesn’t have to maintain the IP configuration of every device on the network individually. That means better performance, especially in larger networks.
 This just happened. Explain this coincidence, atheists!IPv6 myths
This just happened. Explain this coincidence, atheists!IPv6 mythsIPv6 comes with bold claims too. Let’s debunk them:
Your device has one IPv6 address for every purposeI mean, yes, you use the same IPv6 address for both local and remote connections. But no, the “one IP address to rule them all, one IP address to find them” claim isn’t true. As I mentioned before, your device claims the ownership of multiple IPv6 addresses for different scopes like link-local (Remember fe80::) and Internet. Additionally, your device might acquire two different Internet IPv6 addresses too: permanent and temporary. Temporary IPv6 addresses are intended to preserve your privacy as they are rotated periodically. Permanent IPv6 addresses are primarily for servers which must have static IPv6 addresses.
An IP address for every atom in the universeNot even close. There are about 2²⁷² atoms in the universe. Even Earth has 2¹⁶⁶ atoms, so we need at least 168-bits (octet-aligned) address space for them. The actual IPv6 address space is slightly smaller than 128-bits too: the first 16-bits are IANA reserved. You only have the remaining 112-bits to identify devices. That’s still a lot, way more than probably all devices we can produce on Earth in the next millenia, but no, we can’t give every atom its own IP address. But, we can give IPv6 addresses to every grain of sand on Earth. We can even fit them all inside a single /64 prefix.
All in all, yes, IPv6 address space is vast regardless of how many arbitrary particles we can address with it.
Universal connectivity of every deviceYes, IPv6 has no NAT. So, that means no more port forwarding or address space to maintain. But, you still have to have a mechanism to open your device to connections from a remote host if you want to establish a direct connection. Remember, your router/firewall by default will prevent any connection attempt. What are you going to do?
As with UPnP/IGD days, apps today still need to work with a protocol like PCP (Port Control Protocol) in order to open access to a port programmatically. So, it’s not like you suddenly have universal connectivity with global local IPv6 addresses. You don’t have to set up manual port forwarding, but apps still need to work with the router in order to make themselves accessible.
It’s not just the benefits of IPv6 being exaggerated, but there are cases where IPv6 turns out worse than IPv4 too:
Downsides of IPv6There are several things that we take for granted in IPv4 world that IPv6 might make you nostalgic about, such as:
You are at the mercy of your ISP to have subnetsSince IPv6 has no NAT, many ISPs in United States default to forwarding only a single 64-bit prefix (usually called a “/64”) to your router. That means your router has no space left to put the subnet information into an IPv6 address. Remember: IPv6 addresses are auto-configured by devices, so, there is no way for a router to dictate those devices to use less than 64-bit local addresses. That means, your router would have no way to know which subnet to forward a packet to.
Essentially, you’re in the mercy of ISPs to receive prefixes shorter than 64-bit so that your router can use the remaining bits to identify which subnet they need to go to. ISPs can actually afford giving home users at least 16 subnets by simply assigning 60-bit prefixes, but ISPs don’t do that for reasons unknown to me. Maybe the PTSD they had from IPv4 address space shortage made them greedy bastards? Or, they just want to make money by extorting customers. “Hey, if you want a shorter prefix, pay us more”. As far as I know, both Comcast Xfinity and AT&T give their home users a mere /64 prefix: one subnet.
You might say that a home user may not need subnets at all, but, with the prevalence of IoT devices and our greater reliance of the security of our networks, isolating your untrusted devices is getting more important. RIPE, the European authority on IP address assignments, recommends a 56-bit prefix for residential ISP customers. That gives every customer 256 subnets, and that’s the greediest, the most conservative option that Europeans could come up with which an American can only dream of.
Of course, you can configure IPv6 address of every device manually, and give them subnet identifiers this way, but that would be a huge undertaking, especially considering the overhead of adding new devices. Do you want to spend your retirement as a human DHCP server?
IPv6 addresses need extra encoding in URIsRemember typing “http://192.168.0.1” on your browser and accessing your router settings? I do. Because “:” character is reserved for port numbers in the URI specification, it’s impossible to do the same using IPv6 addresses without additional encoding. In case you want to access a web page hosted on a device by its IPv6 address, you have to use the syntax: “http://[aaaa:bbbb:cccc:dddd:eeee:ffff...”, notice the brackets around the address. But, that’s not even the worst part because:
It’s impossible to memorize IPv6 addressesWe’ve never been supposed to memorize IP addresses, but the reality is different. I’m still not sure about which address I can use reliably and consistenly to access my router on IPv6. I can’t memorize its full IP address, that’s for sure. mDNS helps, but it doesn’t always reliably work either.
Hexadecimal is harder than regular numbers too. It’s like trying to memorize a Windows XP product activation code. What was that famous one? FCKGW-RHQQ2-??eh, whatever.
Memorizing an IPv4 address is a transferable skill; “cross-platform” if you will. It’s even universal due to pervasive NAT: 192.168.1.1 most of the time. I didn’t have to look that up. Figuring out the IPv6 address of your router on an arbitrary device you have requires different skills.
On the bright side, you now know that the rightmost 64-bit portion of an IPv6 address is always random, so, you can at least avoid assuming that it’s going to stay forever or supposed to make sense. You can even call that part BLABLA instead of INTERFACE_ID. You can memorize your /64 prefix and at least find out your router address, which is usually something like 1111:2222:3333:4444::1.
IPv6 addresses are complicatedMake no mistake, IPv4 addresses are complicated too. Did you know that 2130706433 is a valid IPv4 address? Or, 0x7F000001, 0177.0000.0000.0001 and 127.1 for that matter? Try pinging them on a shell if you don’t believe me. It’s hard to believe but, they’re all equivalent to 127.0.0.1.
IPv6 addresses have a similar level of variety in representation. Here are some of their characteristics:
The representation of an IPv6 address consists of 8 hextets: sixteen bit hexadecimal groups canonically called segments. (“Hextet” is a misnomer for hexadectet, but too late now). Anyway, now hex tricks like this are possible:![The output of a ping command on PowerShell console: PS D:\>ping facebook.com Pinging facebook.com [2a03:2880:f131:83:face:b00c:0:25de] with 32 bytes of data: Reply from 2a03:2880:f131:83:face:b00c:0:25de: time=3ms Reply from 2a03:2880:f131:83:face:b00c:0:25de: time=3ms](https://i.gr-assets.com/images/S/compressed.photo.goodreads.com/hostedimages/1713273491i/35419596._SX540_.png) “face:b00c” I see what you did there.Prefixing zeroes in hextets are not displayed. So, 2600:00ab is actually shown as 2600:ab.As I mentioned before, hextets with zero values can completely be removed from the address and replaced with double colons. So, 2600:ab:0:0:1234:5678:90ab:cdef would be displayed as 2600:ab::1234:5678:90ab:cdef. See the double colons? That can only be done with the first batch of zero hextets though. So, 2600:ab:0:0:1234:0:0:cdef would still render like 2600:ab::1234:0:0:cdef. Also, you can’t compact just a single zero hextet. So, the zero in 2600:0:1234:5678:abcd:ef01:2345:6789 remains as is.You can specifiy zone id: the network interface that you want to reach that address through with “%” suffix and a zone id. For example, you can be connected to a network over both WiFi and Ethernet, but may want to ping your router from LAN. In that case you append “%” to the address and add your zone id (network adapter identifier). Such as fe80::1%eth0 or fe80::1%3. The problem is, in addition to the brackets you need to use in IPv6 URIs, you must escape “%” to “%” in your browser address bar or any other place where you need to use zone id in a URI.IPv6 addresses can also be used to represent IPv4 addresses. So, you can ping 127.0.0.1 using IPv6 address syntax by prepending it with IPv4 translation prefix, and it’ll be regarded as an IPv4 address: ::ffff:127.0.0.1. But, that doesn’t mean your IPv4 requests will go through IPv6 network. That just tells the underlying networking stack to use an IPv4 connection instead. If you choose another prefix than ::ffff, the IPv4 portion will be made part of the last two hextets and you’ll connect that IP over IPv6 network. For example, 2600:1000:2000:3000::192.168.1.1 will be treated as 2600:1000:2000:3000::c0a8:101, the last two hextets being the hexadecimal equivalent of 192.168.1.1.
“face:b00c” I see what you did there.Prefixing zeroes in hextets are not displayed. So, 2600:00ab is actually shown as 2600:ab.As I mentioned before, hextets with zero values can completely be removed from the address and replaced with double colons. So, 2600:ab:0:0:1234:5678:90ab:cdef would be displayed as 2600:ab::1234:5678:90ab:cdef. See the double colons? That can only be done with the first batch of zero hextets though. So, 2600:ab:0:0:1234:0:0:cdef would still render like 2600:ab::1234:0:0:cdef. Also, you can’t compact just a single zero hextet. So, the zero in 2600:0:1234:5678:abcd:ef01:2345:6789 remains as is.You can specifiy zone id: the network interface that you want to reach that address through with “%” suffix and a zone id. For example, you can be connected to a network over both WiFi and Ethernet, but may want to ping your router from LAN. In that case you append “%” to the address and add your zone id (network adapter identifier). Such as fe80::1%eth0 or fe80::1%3. The problem is, in addition to the brackets you need to use in IPv6 URIs, you must escape “%” to “%” in your browser address bar or any other place where you need to use zone id in a URI.IPv6 addresses can also be used to represent IPv4 addresses. So, you can ping 127.0.0.1 using IPv6 address syntax by prepending it with IPv4 translation prefix, and it’ll be regarded as an IPv4 address: ::ffff:127.0.0.1. But, that doesn’t mean your IPv4 requests will go through IPv6 network. That just tells the underlying networking stack to use an IPv4 connection instead. If you choose another prefix than ::ffff, the IPv4 portion will be made part of the last two hextets and you’ll connect that IP over IPv6 network. For example, 2600:1000:2000:3000::192.168.1.1 will be treated as 2600:1000:2000:3000::c0a8:101, the last two hextets being the hexadecimal equivalent of 192.168.1.1.These are all valid IPv6 addresses:
:: That’s all zeroes0:0:0:0:0:0:0:0.2600:: That’s an equivalent to 2600:0:0:0:0:0:0:0.::ffff:1.1.1.1 is an equivalent to 1.1.1.1 IPv4 address.2607:f8b0:4005:80f::200e is the address I get when I ping google.com. You know the drill; it’s equivalent to 2607:f8b0:4005:80f:0:0:0:200e. As you can see, Like Facebook, Google also took the hard road and decided to assign manually designated INTERFACE_ID ‘s to its IPv6 addresses. Godspeed.In the end, an IPv6 address you write on your address bar might look like this as a contrived example:
https://[542b:b2ae:ed5c:cb5a:e38b:2c4...
No way I’m memorizing that.
That all said, I loved learning about IPv6! The learning experience clarified a few things for me. For example, I didn’t know IPv6 addresses were self-configured with a stateless protocol. I didn’t know it had no NAT. I didn’t know the address space was just conveniently split in half.
I wish we had a shortcut IPv6 address for our default gateway. I propose fe80::1. IETF, take note! :)
I remember that IPv6 support in Windows 2000 was a big step when announced, and we all thought IPv6 would get adopted in a decade or so. Could we be more wrong? Yet, learning about it made me understood why it hasn’t caught on fast.
IPv6 provides no benefit to end-usersDespite how technologically advanced IPv6 is, IPv4 just works. It works even behind NAT, even behind multiple layers of NATs, even with its extremely cramped address space, cumbersome DHCP, and port forwarding. It keeps working. When people find a way that it doesn’t work, and can never work, somebody comes up and makes that work too.
There’s probably a latency advantage of IPv6 not having NAT, but that’s not good enough to make a dent in user experience.
Because IPv6 doesn’t provide any tangible benefit, users will never demand it, and they’ll just be pushed to it without them even knowing, like how we almost always use IPv6 on cellular internet nowadays.
That means, when ISPs feel enough pressure from the limitations of IPv4, they’ll switch to IPv6 in an instant. No question about it.
I wish IPv6 enabled some features that enabled a few distinct scenarios not possible with IPv4, so people could demand IPv6 to use them. Yet, I love the alienesque nature of IPv6 networks, and look forward to the time we fully abandon IPv4 and build everything around IPv6 instead.
[image error]

June 7, 2023
Solving disinformation with Internet literacy
Fake people and fake news have existed on Internet since forever. They didn’t make such a terrible impact at the beginning because Internet in the 90’s lacked two things: users and amplification.
Internet users were an elite minority in the 90’s, mostly consisted of university students. They could see through fake. Some couldn’t and that was okay too, because fake news couldn’t go far either because there was no “retweet” button. You had to be very intentional about whom you wanted that piece of information reach to.
It took years for sensational sites (called ragebait today) like Bonsai Kitten or Manbeef to make an actual dent in the mainstream news. Even then, it didn’t matter, because the whole world didn’t move in synchrony to react to the news. It took years for people to discover the sites one by one, get offended personally or with a couple of friends, then figure out that they were actually fake, calm down and relax.
For a long time, the most sensational fake news on Ekşi Sözlük, the social platform I founded in 1999, were fake celebrity deaths. There was no moderation for fake news on the web site, on the contrary the footprint said “Everything on this website is wrong” which put the onus on the user to verify the information.
Fake celebrity deaths kept coming over the years, but people had started to be more careful. This kind of hands-on training created a new kind of Internet user: the literate.
The literate would be aware that any person or any news on the Internet could be fake, and the onus were on them to verify if they are real any time they consume the content or communicate with someone. They could see the typos in a phishing mail as red flags, they could see the signals in fake news, they could see how Anita22 could be a man using a fake profile picture. They knew that the prince of Nigeria couldn’t care less to give you a penny, they knew how to do reverse image search.
 The literate
The literateUnfortunately, the floodgates opened when iPhone revolution came and suddenly everyone on the planet had Internet access from their pockets. This new generation of people, our parents, relatives, the illiterate so to speak, didn’t go through the similar process that the literate had. They were clueless, lacked the tools, and could easily be manipulated. We let the sheep out to the meadow full of wolves.
That kind of user flow could still be managed well if we had slow and intentional sharing mechanics of the 90’s. You wanted to share something? You had to be very deliberate about it. You had to write an email, or forward it, but still you had to pick recipients yourself. Unfortunately, in 2010, we had already been part of the “amplification platforms” for years then. We call them social media today, but what they’re known for is their amplification mechanics. You consume the content from your little social bubble, but when you share it, it gets shared with the whole world. This asymmetric information flow could cause any kind of information regardless how true or credible to become a worldwide topic in mere hours.
The illiterate lacked tools to deal with this. They were forced inside their bubble. If someone had corrected a fake news article, the victim of disinformation would have no way to know about it. Because their bubble wouldn’t convey that information.
Because the illiterate are trapped in their bubble, they have no way to hone their skills about categorizing information themselves either. Their bubble consists of people mostly with similar levels of Internet literacy.
We basically lack healthy community structures on Internet.
I find Reddit one of the healthier platforms among the others in English-speaking world. Considering that how much it suffers from toxicity itself, the relativity of my statement begs emphasis. In fact, it resembles Ekşi Sözlük a lot in its community structure, but does some things better. For example, subreddits themselves can be great flow guards for information, and disinformation for that matter. Every subreddit is a broadcast channel and a community at the same time, causing people to focus their attention and efforts into only a single type of content. That leads them making fewer mistakes.
The conversation structure on Reddit, the hierarchical threads are better than Twitter’s mentions or Facebook’s replies which are linear. Reddit’s style helps organizing information better along with opposing views. The visibility of content is influenced by people’s votes, so, people have lots of tools to deal with disinformation on Reddit, and moderation may not be even the most important part of it.
There is a reason most controversial disinformation scandals appear on Twitter, because it has the most exponential amplification systems in place with as little controls as possible. There’s no downvote, no hierarchical discussion structure, no moderation hierarchy. Everything is designed to make content amplification easier: the retweet icon, retweets showing up on your main timeline with the same priority as original content, “trending topics” so you can retweet the most retweeted content even more. Everything becomes a feedback loop for more amplification of the content, not necessarily high quality content either. It just has to be controversial in some way.
Because Twitter is “social media”, people with the most followers have the most reach. Only a minority actually gets the most engagement on the platform, and the majority barely gets anything at all. This hurts content quality. Reddit doesn’t have this problem because amplification dynamics doesn’t take number of followers into account. You can have zero followers yet still get upvoted to the front page that day if you had produced content the subreddit community likes. I know, Reddit still has a “follower” mechanism, but it’s not the backbone of how engagement works on the site.
There are supposedly moderated communities which I think was an attempt to fix Twitter’s structural deficiencies, but the way they’re designed makes them pretty much useless. Should I share my content with the whole world through my followers, or just this small room of hundred people who cannot share my content even if they wanted to? I understand what problem they’re trying to solve: the uncontrolled amplification, but they fail to provide other ways for user to get engagement.
Elon Musk seems to be trying to address this problem with “For You” tab on Twitter which tries to make you contact with people outside your bubble, and let those people to promote their content to the people who’re not following them. But, the effective result becomes is just another way of uncontrolled flow of information causing disinformation distribute in new ways in addition to the existing ones.
Essentially, healthy communities are not profitable enough, and the engagement Rube Goldberg machine is fed with controversy. Controversy is the natural output of a for-profit social platform as it brings the most page views.
Paid memberships can’t fix this issue either because there’s no way that it can get near to the income generated by ads. Even if they can match the income, they can’t match the growth. The investors want immediate growth.
How do we fix this? Do we need more regulation? I don’t think so, because I don’t think people who design those regulations is capable to understand this problem better than the platforms themselves.
I believe that we need more Internet literacy. We have to make Internet literacy perhaps a prerequisite for accessing Internet. We need to teach it in schools, in courses, on web sites, but we have to have a curriculum for Internet. Let’s teach children about fake news, fake people, how people can harm us over the Internet, how trolls seek engagement, how they can protect their private information, and what tools can be used to avoid harm. Let’s teach them to navigate Internet skillfully and deliberately.
The literate will break this amplification chain because they will think twice before retweeting. They will research if they think the content seems off. Because of their education, they will ask for better platforms, they will migrate to them when they appear. The bad platforms will either have to change, or turn into a graveyard.
[image error]June 9, 2022
Hover is over

This is my UI design advice inspired from “Eval is evil.” Stop relying on hover for revealing hidden actions, or providing essential information. Hover’s distracting, clunky, undiscoverable, inaccessible, and frustrating.
DistractingWhen you reveal a certain part of your UI layout using hover, unhovering would hide the same UI. That might easily turn into a a flicker on the UI where the user’s scrolling or just moving the mouse pointer around. Remember the web page ads that popped up when you only hovered on a word? Remember those feelings? That feeling is exactly what made Anakin Skywalker turn to the dark side.
ClunkyTo avoid the problem with distraction, UI designers add delays, so the hidden part is only revealed when you wait long enough on the certain region of the interface. That solves the distraction problem, but now you have a clunky UI that makes you wait much longer. Every time you have to use the same UI, you’re charged a non-distracting UI fee from your time.
UndiscoverableThere’s no universal UI language that says “this item can be hovered, and will do this if you do so.” You only accidentally discover a hoverable UI, or you hover over every UI element like the old LucasArts adventure games where you had to find the right pixel to pick up the right item to solve the puzzle. I loved those games but not the pixel finding parts.
InaccessibleIn addition to being undiscoverable, which is also an accessibility issue in itself, hover-based UI designs require mouse finesse. You must avoid moving the mouse too much or you might lose the hover. People have developed numerous techniques to prevent you from losing your hover status on a drop down menu item.
You have to be able to target a certain area with mouse without accidentally click on it either. I’m sure operating systems provide certain fallback mechanisms to alleviate some of these issues, hover isn’t accessible by default. It’s hard to use.
Some screen readers might use hover text information and present it in a meaningful way, but there are other, better suited ways for that like ARIA labels without relying over the hover itself.
FrustratingHover state can easily get lost by accidentally moving the mouse and that can cause the user to click on something else instead unintentionally. Similarly, losing hover would make you wait another second to see the UI again. It’s all prone to mistakes, accidents, tears, and screams.
Besides, mobile devices can’t support hover because we haven’t invented such screen sensors yet. Mobile web browsers treat clicks as hovers. That means when you click an element that shows a different style when hovered, you’ll have to click on it once again, because your first click would only register as hover. Arguably, any sane designer would add conditionals to avoid such behavior on mobile, but that means there’s a disconnect between the UX provided by platforms which is an issue in itself. Users will have to learn different ways of using your app regardless how subtle the differences are, which is also frustrating.
The hoverless wayJust integrate the revealed portion of the interface into the main UI, or under a clickable action. You might think that it’s an extra step for UI interaction, but it’s actually faster than waiting for menu to appear.
When is it acceptable to use hover?Ideally, never use hover. If you have to, use hover only to amplify the quality of the user’s experience, and never as the core of your user interaction flow. Your UI should be perfectly usable and accessible without hover.
P.S. If you like my content, I have a book about programming tips; check out Street Coder.
[image error]October 11, 2021
To test or not to test
This is an excerpt from my book Street Coder , prepared by Christopher Kaufmann from Manning Publications.
 Street Coder cover
Street Coder coverHow can you keep your code reliable without testing?
Take 40% off Street Coder by entering fcckapanoglu into the discount code box at checkout at manning.com.
Don’t write testsYes, testing is helpful, but nothing is better than avoiding writing tests completely. How do you get away without writing tests and still keep your code reliable?
Don’t write codeIf a piece of code doesn’t exist, it doesn’t need to be tested either. Deleted code has no bugs. Think about this when writing code. Is that something worth writing tests for? Maybe you don’t need to write that code at all. Can you opt for using an existing package over implementing it from scratch? Can you use an existing class that does the exact same thing you’re trying to implement? For example, you might be tempted to write custom regular expressions for validating URLs when all you need to do is use System.Uri class.
Third-party code isn’t guaranteed to be perfect or always suitable for your purposes. You might later discover that the code doesn’t work for you. It’s usually worth taking that risk before trying to write something from scratch. Similarly, the same codebase you’re working on might have the code doing the same job implemented by a colleague. Search your code base to see if something is there.
If nothing works, be ready to implement your own. Don’t be scared of reinventing the wheel; it can be educational.
Don’t write all the testsThe famous Pareto principle states that eighty percent of consequences are the results of twenty percent of the causes. At least, this is what eighty percent of the definitions say. It’s more commonly called the 80/20 principle. It’s applicable in testing too. You can get eighty percent reliability from twenty percent test coverage if you choose your tests wisely.
Bugs don’t appear homogenously. Not every code line has the same probability of producing a bug. It’s more likely to find bugs in more commonly used code, and code with high churn. You can call those areas of the code hot paths where a problem is more likely to happen.
This is exactly what I did with my web site. It had no tests whatsoever even after it became one of the most popular Turkish web sites in the world. Then, I had to add tests because too many bugs started to appear with the text markup parser. The markup was custom, it barely resembled Markdown, but I developed it before Markdown was even a vitamin in the oranges Dave Gruber ate. Because parsing logic was complicated and prone to bugs, it became economically infeasible to fix every issue after deploying to production. I developed a test suite for it. That was before the advent of test frameworks, and I had to develop my own. I incrementally added more tests as more bugs appeared, because I hated creating the same bugs, and we developed a quite extensive test suite later, which saved us thousands of failing production deployments. Tests just work.
Even navigating to your web site’s home page in a browser provides a good amount of code coverage because it exercises many shared code paths with other pages. This is called smoke testing. It comes from the times when they developed the first prototype of the computer and tried to turn it on to see if smoke came out of it. If there was no smoke, that was pretty much a good sign. Similarly, having good test coverage for critical, shared components is more important than having one hundred percent code coverage. Don’t spend hours to add test coverage to that missing line in the constructor of a class if it won’t make much difference. You already know that code coverage isn’t the whole story.
Let the compiler test your codeWith a strongly-typed language, you can use the type system to reduce the number of test cases needed. We already discussed how nullable references can help you to avoid null checks in the code, which also reduces the need to write tests for null cases. Let’s go over a simple example. We need to validate if a chosen username is valid, and we need a function that validates usernames.
Eliminate null checksLet our rule for a username be lowercase alphanumeric characters up to eight characters long. A regular expression pattern for such a username is “ ^[a-z0–9]{1,8}$”. We can write a username class as in listing 1. We define a Username class to represent all usernames in the code. We avoid the need to think about where we should validate our input by passing this to any code that requires a username.
In order to make sure that a username is never invalid, we validate the parameter in the constructor and throw an exception if it’s not in the correct format. Apart from the constructor, the rest of the code is boilerplate to make it work in comparison scenarios. Remember, you can always derive such a class by creating a base StringValue class and write minimal code for each string-based value class. I wanted these to remain here to be explicit about what the code entails.
Listing 1 A username value type implementation
https://medium.com/media/8ef85f0aab7c8c5b722708a2a95de38b/href
#A We validate the username here, once and for all.
#B Our usual boilerplate to make a class comparable.
Testing the constructor of Username requires us to create three different test methods as in listing 2. One for nullability because a different exception type is raised, the other one is for non-null but invalid inputs, and finally for the valid inputs because we need to make sure that it recognizes valid inputs as valid also.
Listing 2 Tests for Username class
https://medium.com/media/98b1212c2048ba3a00e2cd4f268d12b3/hrefHad we enabled nullable references for the project Username class was in, we wouldn’t need to write tests for the null case at all. The only exception to this is when writing a public API, which may not run against a nullable-references-aware code. In that case, you still need to check against nulls.
Similarly, declaring Username as a struct when suitable makes it a value type, which also removes the requirement for a null check. Using correct types and correct structures for types helps you reducing number of tests. The compiler ensures the correctness of our code instead.
Using specific types for our purposes reduces the need for tests. When your registration function receives a Username instead of a string, you don’t need to check if registration function validates its arguments. Similarly, when your function receives a URL argument as a Uri class, you don’t need to check if your function processes the URL correctly anymore.
Eliminate range checksYou can use unsigned integer types to reduce the surface area of invalid input space. You can see unsigned versions of primitive integer types in table 1. There you can see the varieties of data types with their possible ranges which might be more suitable for your code. It’s also important that you keep in mind whether the type is directly compatible with int as it’s the go-to type of .NET for integers. You probably have already seen these types, but you might not have considered that they can save you from writing extra test cases. For example, if your function needs only positive values, then why bother with int and checking for negative values and throwing exceptions? Receive uint instead.
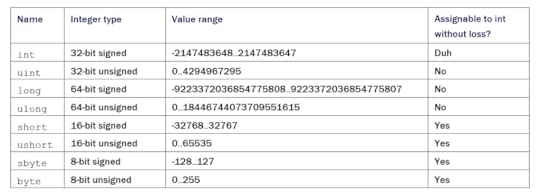 Table 1 Alternative integer types with different value ranges
Table 1 Alternative integer types with different value rangesWhen you use an unsigned type, trying to pass a negative constant value to your function causes a compiler error. Passing a variable with a negative value is possible only with explicit type casting which makes you think about if your value is suitable for that function at the call site. It’s not the function’s responsibility to validate for negative arguments anymore. Assume that a function needs to return trending tags in your microblogging web site up to only specified number of tags. It receives a number of items to retrieve rows of posts as in listing 3.
In listing 3, we have a GetTrendingTags function which returns items by taking the number of items into account. Notice that the input value is a byte instead of int, because we don’t have any use case more than 255 items in trending tag list. This immediately eliminates the cases where an input value can be negative or too large. We don’t even need to validate the input anymore. One fewer test case and a much better range of input values, which reduces the area for bugs immediately.
Listing 3 Receive posts only belonging a certain page
https://medium.com/media/146be9f38454cedd399fb1f3563c8afe/href
#A We chose byte instead of int.
#B A byte or a ushort can be passed as safely as int too.
Two things are happening here; first, we chose a smaller data type for our use case. We don’t intend to support billions of rows in a trending tag box. We don’t even know what that looks like. We narrowed down our input space. Second, we chose byte, an unsigned type, which is impossible to become negative. This way, we avoid a possible test case and a potential problem that might cause an exception. LINQ’s Take function doesn’t throw an exception with a List, but it can when it gets translated to a query for a database like Microsoft SQL Server. By changing the type, we avoided those cases, and we don’t need to write tests for them.
Note that .NET uses int as the de facto standard type for many operations like indexing and counting. Opting for a different type might have to be cast and converted into int if you happen to interact with standard .NET components with that type. You need to make sure that you’re not digging yourself into a hole. For example, if you need more than 255 items in the future, you’ll have to replace all references to bytes with shorts or ints which can be a time-consuming task. You need to make sure that you are saving yourself from writing tests for a worthy cause. You might even find writing additional tests more favorable in many cases rather than dealing with different types. In the end, it’s only your comfort and your time that matters despite how powerful types are for hinting at valid value ranges.
Eliminate valid value checksSometimes we use values to signify an operation in a function. A common example is fopen function in C programming language. It takes a second string parameter that symbolizes the open mode, which can mean “open for reading”, “open for appending”, “open for writing”, and like this.
.NET team, decades after C has made a better decision and created separate functions for them. You have File.Create, File.OpenRead, File.OpenWrite methods separately, avoiding the need for an extra parameter and the need for parsing that parameter. It’s impossible to pass along the wrong parameter. It’s impossible for functions to have bugs in parameter parsing because there’s no parameter.
It’s common to use such values to signify a type of operation. You should consider separating them into distinct functions instead, which can both convey the intent better, and reduce your test surface.
One of the common ways in C# is to use Boolean parameters to change the logic of the running function. An example is to have a sorting option in our trending tags retrieval function as in listing 4, because, assume that we need trending tags in our tag management page too, and it’s better to show them sorted by title there. In contradiction with laws of thermodynamics, developers tend to constantly lose entropy. They always try to make the change with the least entropy, without thinking that how much burden it will be in the future. The first instinct of a developer can be to add a Boolean parameter and be done with it.
Listing 4 Boolean parameters
https://medium.com/media/02d527529b0a78a3050394fd9215a022/href
#A Newly added parameter
#B Newly introduced conditional
The problem is, if we keep adding Booleans like this, it can get complicated because of the combinations of those variables. Let’s say another feature required trending tags from yesterday. We add that to other parameters in listing 5. Now, our function needs to support combinations of sortByTitle and yesterdaysTags too.
Listing 5 More Boolean parameters
https://medium.com/media/7f3c4cacf362a0e94c716d758bcedfc5/href#A More parameters!
#B More conditionals!
An ongoing trend is our function’s complexity increases with every Boolean parameter. Although we have three different use cases, we have four flavors of the function. With every added Boolean parameter we create fictional versions of the function that no one uses, yet someone might try and get into a bind. A better approach to have a separate function for each client, as in listing 6.
Listing 6 Separate functions
https://medium.com/media/dd1df49164736f435f264f86487aa92d/href#A We separate functionality by function names instead of parameters.
We now have one less test case and you get slightly increased performance for free as a bonus. The gains are miniscule and unnoticeable for a single function, but at points where the code needs to scale, they can make a difference without you even knowing. The savings increase exponentially when you avoid trying to pass state in parameters and use functions as much as possible. You might still be irked by repetitive code, which can easily be refactored into common functions as in listing 7.
Listing 7 Separate functions with common logic refactored out
https://medium.com/media/4208bceed62489dd4918bf024d012480/href#A Common functionality
Our savings aren’t impressive here, but such refactors can make greater differences in other cases. The important takeaway is to use refactoring to avoid code repetition and combinatorial hell.
The same technique can be used with enum parameters which are used to dictate a certain operation to a function. Use separate functions, and you can even use function composition, instead of passing along shopping list of parameters.
If you want to learn more about the book, check it out on Manning’s liveBook platform here.
[image error]October 6, 2020
I’m writing a book
I’m writing a book titled Street Coder for beginner and medium-level programmers. It’s got released recently as part of Manning Early Access Program (MEAP). Here is how the cover looks:
 The cover illustration doesn’t necessarily depict you at work, but it also might.
The cover illustration doesn’t necessarily depict you at work, but it also might.I’m a self-taught programmer and I’ve found that the gap between what you’re taught at school, bootcamp, courses, or in your room, and what you need to know in your professional software development career is something that can be addressed early.
We start our professional career with demanding workloads. There is always something to do and deadlines can always be pressuring to revisit our approach to software development. That kind of desperation forces us into a loop of doing things the way that requires the least thinking, because we don’t have time to think.
Because of the state of arrested development, we don’t get a chance to improve ourselves and get tend to stay at a certain level without growing. We become doomed to stay mid-level for an unnecessarily long time.
Street Coder aims to teach you certain about certain topics that you might have already learned but have never figured out how it can make you a more efficient developer. You might even think that some of those things, like algorithms, data structures, are just boring topics that just get in your way. The book teaches about what works in the streets and in what way. It aims to teach you how to approach well-known techniques with skepticism, and embrace even seemingly bad practices when needed. You’ll see advice like “Use GOTO!”, “DO Repeat Yourself!” and can get shocked. Trust me though, it’s all going to be okay in the end.
The early access program is great for receiving feedback and getting the best out of the limited number of pages on the medium. I’m looking forward to your feedback in case you find the book a good fit for you! Here is the link if you’re interested: https://www.manning.com/books/street-coder
See you in the streets!
P.S.: You can use the discount code “slkapanoglu” for a 40% discount at the checkout, if there isn’t any better promotion is active on Manning’s web site.
[image error]June 29, 2020
Hey isn’t for me, for now
I’ve tried Hey email service for ten days in its fourteen-day evaluation period and have finally decided that it’s not for me.
I was awestruck by Hey’s phenomenal introduction video. It resembled the presentations of Steve Jobs. It got me excited and eager to try it out. I’ve been a loyal GMail user since it was released sixteen years ago but the privacy concerns have made me to look for alternatives. I looked at fully-encrypted solutions which were too much for my threat model. I just want to be able to search my mail without downloading everything on my machine.
I immediately switched to Hey with full commitment as soon as I received an invitation code from a friend. I forwarded all my email addresses to it and installed the app, made it the default email app on my phone.
I tried to use Hey’s Windows Store app too but it was just a less accessible version of the web app. For example, it wasn’t possible to adjust the text size on the app. So, I decided to stick to the web on desktop.
Hey impressed me on some aspects. I really liked the proactive “Spy Tracker Shaming” feature that immediately exposes any email that tries to trace your views and clicks:
body[data-twttr-rendered="true"] {background-color: transparent;}.twitter-tweet {margin: auto !important;}function notifyResize(height) {height = height ? height : document.documentElement.offsetHeight; var resized = false; if (window.donkey && donkey.resize) {donkey.resize(height);resized = true;}if (parent && parent._resizeIframe) {var obj = {iframe: window.frameElement, height: height}; parent._resizeIframe(obj); resized = true;}if (window.location && window.location.hash === "#amp=1" && window.parent && window.parent.postMessage) {window.parent.postMessage({sentinel: "amp", type: "embed-size", height: height}, "*");}if (window.webkit && window.webkit.messageHandlers && window.webkit.messageHandlers.resize) {window.webkit.messageHandlers.resize.postMessage(height); resized = true;}return resized;}twttr.events.bind('rendered', function (event) {notifyResize();}); twttr.events.bind('resize', function (event) {notifyResize();});if (parent && parent._resizeIframe) {var maxWidth = parseInt(window.frameElement.getAttribute("width")); if ( 500 < maxWidth) {window.frameElement.setAttribute("width", "500");}}— @esesci
The feature made me feel empowered. I was suddenly aware of a privacy problem that I was oblivious to previously. I was later told by a friend who works at Google that GMail also prevented these from working by mirroring the image contents to its local server, so you’re actually never exposed to that kind of tracking when using GMail. I just wasn’t aware. It could have been communicated better I guess.
body[data-twttr-rendered="true"] {background-color: transparent;}.twitter-tweet {margin: auto !important;}function notifyResize(height) {height = height ? height : document.documentElement.offsetHeight; var resized = false; if (window.donkey && donkey.resize) {donkey.resize(height);resized = true;}if (parent && parent._resizeIframe) {var obj = {iframe: window.frameElement, height: height}; parent._resizeIframe(obj); resized = true;}if (window.location && window.location.hash === "#amp=1" && window.parent && window.parent.postMessage) {window.parent.postMessage({sentinel: "amp", type: "embed-size", height: height}, "*");}if (window.webkit && window.webkit.messageHandlers && window.webkit.messageHandlers.resize) {window.webkit.messageHandlers.resize.postMessage(height); resized = true;}return resized;}twttr.events.bind('rendered', function (event) {notifyResize();}); twttr.events.bind('resize', function (event) {notifyResize();});if (parent && parent._resizeIframe) {var maxWidth = parseInt(window.frameElement.getAttribute("width")); if ( 500 < maxWidth) {window.frameElement.setAttribute("width", "500");}}— @ahmetb
First friction I encountered was that there was no shortcut key in the “Mark All As Seen” in the “Read Together” tab. I’m not a “full keyboard” person. I use mail app pretty much like an FPS game. My left hand on WASD keys and my right hand on mouse. “E” being the archive key on GMail, I usually scroll the mail using mouse and archive it by pressing it. I wanted to do the same on Hey, but I wasn’t able to. To their credit, Hey team was nothing but a good sport about it.
body[data-twttr-rendered="true"] {background-color: transparent;}.twitter-tweet {margin: auto !important;}function notifyResize(height) {height = height ? height : document.documentElement.offsetHeight; var resized = false; if (window.donkey && donkey.resize) {donkey.resize(height);resized = true;}if (parent && parent._resizeIframe) {var obj = {iframe: window.frameElement, height: height}; parent._resizeIframe(obj); resized = true;}if (window.location && window.location.hash === "#amp=1" && window.parent && window.parent.postMessage) {window.parent.postMessage({sentinel: "amp", type: "embed-size", height: height}, "*");}if (window.webkit && window.webkit.messageHandlers && window.webkit.messageHandlers.resize) {window.webkit.messageHandlers.resize.postMessage(height); resized = true;}return resized;}twttr.events.bind('rendered', function (event) {notifyResize();}); twttr.events.bind('resize', function (event) {notifyResize();});if (parent && parent._resizeIframe) {var maxWidth = parseInt(window.frameElement.getAttribute("width")); if ( 500 < maxWidth) {window.frameElement.setAttribute("width", "500");}}— @dhh
Approving every new contact seemed empowering at first, but quickly turned into a chore. It was just too much cognitive overload for me because I’m not always in the mindset that I can decide which contact I want to continue messaging with, and which folder (Imbox, The Feed, Paper Trail) I should be putting it in. I decided that I just don’t want to decide these upfront. I can spread those tasks over my entire session in GMail. I glance at mail. I let it stay there for a while. I revisit it, I archive it, I mark it as spam, but never upfront on a single run.
Also, approval causes the fear of blocking out some contacts accidentally. I know, there must be a history of these somewhere (and there is, don’t worry), but going back and trying to find that is just another problem to tackle. I just don’t want to deal with these. Mail should have as little friction as possible.
Another problem with Hey is that reading an individual mail implies that you’re effectively done with it unless you set it aside explicitly. That’s not my default, reading rarely means that I’m done with an email. I prefer to have it stay in inbox, and decide on what to do with it later. I need this to be the default. This is one of the core philosophical differences of Hey, and that’s one of the things that made me think that Hey can’t work for me in its current shape.
The mail that I set aside becomes too prominent. It’s good for some email that I need to stay prominent but not for the ones that I need to look at sometime. I usually make the distinction in GMail by using the newly adopted Snooze functionality from Google Inbox. It’s perfect. “Add as a task” on GMail also as a good alternative.
The problems with all those features of Hey were that I was constantly anxious of doing the wrong thing like ignoring an important recipient, or forgetting to follow up an email. GMail alleviates these with additional features with the right defaults, and by showing an “Undo” link after every action which gives me confidence on my decisions. Undo is theoretically possible with Hey by visiting some other history page, but not as easy as an Undo.
The final dealbreaker for me was that not having the ability to use different “From” addresses which is important for me to keep the conversation on the right channel. I just don’t want to perplex the recipient by showing up in a new email address. That would make them think “Is that Sedat’s new address? Was it a mistake? Should I add this to my contact list? Is it a scam? What’s going on?”. I just didn’t want that, and recently had to reply to a conversation over GMail because of that. I don’t want to do that.
I thought about subscribing once to keep my relatively shorter email alias as a forwarding address but didn’t want to do that either as I wouldn’t be using the email address anyway.
Make no mistake, I like Hey’s opinionated approach. I believe that such thinking will eventually lead us to better products, but it has that slight designed by programmers feel to it, which isn’t always ideal, and I’m saying this as a programmer. The “you can undo by visiting the history page” recommendation is the best example of it. User needs to jump through the hoops of disconnected but complete features while GMail just says “you can undo by clicking Undo”. I’m not saying that Hey hasn’t focused on scenarios, but they seem to have mostly focused on the happy path only.
I’m also an Inbox Zero person. Any email in my inbox means I’m not done with them yet, and ideally I have as few email as possible in my inbox at any given time. As I understand, that’s not Hey’s target user base. Hey might be great for people who have thousands of email in their inbox. Maybe, that’s why it doesn’t work for me.
So, UX frictions that I encountered as well as Hey’s opinionated decisions on email scenarios made it a no for me. I’m going back to GMail, but I hope Hey addresses these issues in the future, or I don’t know, an alternative product comes out with better designs. Their presentation video convinced me that there is still a lot of space for innovation in Email.
[image error]January 8, 2020
How is computer programming different today than 20 years ago?
I saw a question on Quora asking this and I started to write an answer. But it got so long that I converted into a post here.
Here are some changes I have noticed over the last 20 years, in random order:
Some programming concepts that were mostly theoretical 20 years ago have since made it to mainstream including many functional programming paradigms like immutability, tail recursion, lazily evaluated collections, pattern matching, first class functions and looking down upon anyone who don’t use them.A desktop software now means a web page bundled with a browser.Object-Oriented Programming (OOP) has lost a lot of street cred although it’s still probably the most popular programming model. New trait-based programming models are more pervasive in modern languages like Go, Rust and Swift. Composition is preferred over inheritance.You are not officially considered a programmer anymore until you attend a $2K conference and share a selfie from there.Because of the immense proliferation of multi-processor CPUs, parallel programming is now usually supported at the programming language level rather than primitive OS calls of 20 years ago. It brought in asynchronous programming primitives (async/await), parallel coroutines like goroutines in Go language or channels in D, composability semantics like observables with reactive programming.A pixel is no longer a relevant unit of measurement.Garbage collection has become the common way of safe programming but newer safety models are also emerging like lifetime semantics of Rust and snarky jokes in code reviews.3 billion devices run Java. That number hasn’t changed in the last 10 years though.A package management ecosystem is essential for programming languages now. People simply don’t want to go through the hassle of finding, downloading and installing libraries anymore. 20 years ago we used to visit web sites, downloaded zip files, copied them to correct locations, added them to the paths in the build configuration and prayed that they worked.Being a software development team now involves all team members performing a mysterious ritual of standing up together for 15 minutes in the morning and drawing occult symbols with post-its.Language tooling is richer today. A programming language was usually a compiler and perhaps a debugger. Today, they usually come with the linter, source code formatter, template creators, self-update ability and a list of arguments that you can use in a debate against the competing language.Even programming languages took a side on the debate on Tabs vs Spaces.Adobe Flash, which was the only way to provide some smooth interaction on the web, no longer exists, thankfully. Now we have to develop on three different platforms with entirely different programming models in order to provide the same level of interaction.IDEs and the programming languages are getting more and more distant from each other. 20 years ago an IDE was specifically developed for a single language, like Eclipse for Java, Visual Basic, Delphi for Pascal etc. Now, we have text editors like VS Code that can support any programming language with IDE like features.Code must run behind at least three levels of virtualization now. Code that runs on bare metal is unnecessarily performant.Cross-platform development is now a standard because of wide variety of architectures like mobile devices, cloud servers, embedded IoT systems. It was almost exclusively PCs 20 years ago.Running your code locally is something you rarely do.Documentation is always online and it’s called Google. No such thing as offline documentation anymore. Even if there is, nobody knows about it.A tutorial isn’t really helpful if it’s not a video recording that takes orders of magnitude longer to understand than its text.There is StackOverflow which simply didn’t exist back then. Asking a programming question involved talking to your colleagues.People develop software on Macs.Internet connectivity is the norm and being offline is an exception which is the opposite of how it was back then.Security is something we have to think about now.Mobile devices can now show regular web pages, so no need to create a separate WAP page on a separate subdomain anymore. We create mobile pages on separate subdomains instead.We open source everything by default except the code that would really embarass us.There are many more talented women, people of color and LGBT in the industry now, thanks to everyone who fought against discrimination. I still can’t say we’re there in terms of equality but we are much better.Getting hacked is a regular occurence. Losing all your user data usually circumvented by writing a blog post that recommends changing passwords and that’s pretty much it. Apology isn’t required.Working as a programmer remotely is easier than ever thanks to the new technologies like video conferencing, ubiquitous internet access and Keurigs.We don’t use IRC for communication anymore. We prefer a bloated version called Slack because we just didn’t want to type in a server address.We run programs on graphics cards now.Your project has no business value today unless it includes blockchain and AI, although a centralized and rule-based version would be much faster and more efficient.For some reason, one gigabyte is now insufficient storage space.Because of side-channel attacks we can’t even trust the physical processor anymore.A significant portion of programming is now done on the foosball table.Since we have much faster CPUs now, numerical calculations are done in Python which is much slower than Fortran. So numerical calculations basically take the same amount of time as they did 20 years ago.Creating a new programming language or even creating a new hardware is a common hobby.Unit testing has emerged as a hype and like every useful thing, its benefits were overestimated and it has inevitably turned into a religion.Storing passwords in plaintext is now frowned upon, but we do it anyway.[image error]January 5, 2020
A Pledge for Namespace Directives in C#
UPDATE: File scoped namespaces came to C# 10 as of today! Celebrate! 🥳
TradeNet (later TradeSoft), the company I worked for back in 2000 had me enrolled in a .NET Early Adopter Training Program which taught .NET Programming using a beta version of Visual Studio .NET.
I had mostly written code in Borland Delphi until then because of its rapid prototyping features for Windows applications, heck even for web applications. Delphi’s IDE was unmatched. The programming language it came with, Object Pascal, was clean for such a low-level one, had the right high-level constructs and abstractions in places and had a robust standard library called VCL. The only downside was manual memory management. Only alternatives with the same usability back then were Visual Basic and Java. Visual Basic didn’t have a good IDE and Java was slow as hell. Remember that this was back in 2000. Java lacked serious tooling too. It would still take another year before Java got a serious IDE called Eclipse.
Visual Studio .NET had shaken the throne of Delphi as Microsoft hired the Delphi’s locomotive force Anders Hejlsberg to design a new programming language called C#.
What made C# stand out?C# was what Object Pascal should have been: concise. Here is what a simple class looked like in Object Pascal if my memory serves me correctly:
unit MyUnit;interfacetype TMyClass = class(TObject)procedure Hello(s:string);
end;implementationprocedure TMyClass.Hello(s:string)
begin
WriteLn('Hello world ', s);
end;end.
Too much noise, repetition of declarations, and too many keywords. C# version of it would look simpler which makes the actual code stand out more, and required you to type less too:
namespace MyNamespace{
class MyClass
{
void Hello(string s)
{
Console.WriteLine($"Hello world {s}");
}
}
}
See, there is minimum amount of decoration. The code blocks are distinguishable yet easy on the eyes. The interface and implementation are in the same place to avoid duplication, albeit it’s arguable if that’s better or not. No frivolous keywords scattered around adding to the cognitive overload. Classes inherited Object class automatically. It’s a considerable improvement over Delphi. But is it an improvement over Java? See for yourself:
package MyPackage;class MyClass{
void Hello(string s)
{
System.out.format("Hello world %s", s);
}
}
Java version looks even simpler and cleaner than C# despite that I kept the Allman brace style for easier comparison. What makes the difference? Well, Java does not have namespace blocks. Instead, it has a “package” directive which applies a namespace declaration for the whole scope of the file.
Why Does C# Have Namespace Blocks?C# set out to be a successor to Java with better features. Anders Hejlsberg added the right touches to the language which made it more practical such as properties andforeach statements in its first release. The team kept adding to the list of niceties in the following versions: type-inference, generics, lambda, LINQ, tuples, pattern matching, switch expressions, non-nullable references and so forth. Despite that it was released years before C#, Java has become the one that tries to catch up.
One of the handy additions to C# was the removing the restriction of “one-type per file” limit in Java. It was one of the archaic rules in Java, supposedly to encourage developers to program better. Well, using one file per type is usually good but having the option to keep a small type next to your class is great too. But it meant that a single file could contain classes from multiple namespaces, so namespaces had to have scopes. Scopes are defined by blocks, so we got namespace blocks.
What’s Wrong With Namespace Blocks?Two words: unnecessary indentation. You need indentation to follow the structure and flow. However, a namespace contributes nothing in that aspect. Think about it: when was the last time did you have to have two different namespaces in a single file? What good would come from it? StyleCop already recommends single type per file, let alone namespaces.
But the greatest reason isn’t that, it’s the left margin. The left margin of a text editor is a greatly underestimated programming tool. When a text is right next to the left margin, you can easily say that it’s at the global scope. One indent in and you can say that you are inside a scope. But after the second indent, it becomes harder to track your contextual location in the source code. C# foregoes the benefits of the left margin from the day one, your code is always at least three indents in. Since it’s harder to discern between three and four indents than one and two, it’s easier to get clueless about whether the code is inside, say, a while or an if statement.
I know, the practices like writing the code in smaller chunks or returning early can help avoiding this problem but not altogether. You can always have the code at the top of the editor so it won’t matter how small your function is; you are still contextually lost. At least more so than one indent less.
So, Get Rid Of ThemYes. That is easily one of the greatest and cheapest improvements to C#’s syntax. It is one of the things that Java got right. Why not change it to a directive and make it applicable to the file instead:
namespace My.Unique.Namespace;That should have been done years ago. I know people carefully analyze risks versus benefits, backward compatibility, keeping it working with existing tools and whatnot. I can’t think of any sane reason to not improve upon that. Yes, I know that C# supports multiple classes and multiple namespaces per file so a “block-based” namespace syntax is required and I agree, to have backward compatibility or to address nested blocks or whatnot. But I think having mostly separate files for classes is helpful in larger projects.
I know that C# needs improvement on many fronts. It faces stiff competition in particular with the arrival of new generation languages like Go, Rust and Swift. C# can adopt better parallel processing paradigms like Goroutines, or stronger type systems or lifetime semantics as in Rust or better type-inference as in Swift. Heck, C# can even benefit a lot from “enums with methods”. But those require thorough analysis, careful decision-making not to dig yourself into a hole. I might say that’s exactly what D language has done. I admire C# team’s track record on their careful discretion on which features they bring into the ecosystem. Unfortunately, it also means that trivial stuff like optional namespace blocks might not make it into the language forever.
There is an open proposal for namespace directives. V̶o̶t̶e̶ ̶f̶o̶r̶ ̶i̶t̶.̶ (While I have been writing this article, uservoice is gone. So, just comment your support in the GitHub issue instead)
[image error]October 25, 2019
Transitioning to Nullable References
So you plan on switching to .NET Core 3.0 but you’re not sure if you also want to make use of the new feature called “nullable references”. Yes, it is a great feature in terms of preventing bugs and crashes so you should be using it, but how should you approach switching to it?
But Weren’t References Already Nullable?I know, “nullable references” is a confusing term because you have always been able to assign null to a reference in C#. As I understand, C# team implies that if the value can be encapsulated inside a Nullable, it’s nullable, not that if it can be assigned null or not. Because the previous feature to make value types nullable was called nullable value types.
Think of it this way: now with C# 8.0, you can’t assign references null or nullable values anymore. So, all references are non-nullable by default which means that we have a new construct called “nullable references”. I hope that clears some confusion.
string s; // non-nullable referencestring? s; // nullable referenceNullable References Don’t Save You From (All) Null Checks
The idea that C# 8.0 will save you from all those pesky null checks is a misconception. It makes the developer believe that the null-checking code can finally go away and we can deal with correct types directly. Unfortunately, it’s not true. First, you still have to check for null values in your public functions that are open to the third-party callers, like in a library code, because the caller isn’t guaranteed to use nullable references themselves. So, for a code that doesn’t use nullable references, your function signatures are just as nullable as a C pointer. It doesn’t magically make all the third-party code “null-aware”. Your externally facing functions in your libraries will still have to check for null values and throw ArgumentNullException accordingly.
Second, you’ll still have to account for nulls when you use nullable types, duh. The compiler will make you do those checks gracefully. Nullable references don’t make the dreaded null go away; on the contrary, it lets you use them whenever you see fit, which brings to my next point:
Nullable References Are Not FreeYes, I know, your compiler will take care of many of the null checks in your code and gladly prevent you from passing a nullable value to a function, keeping you safe. However, there is still a cost: Now, you have to think about every reference you use about its nullability semantics, something a C# programmer isn’t very accustomed to. It’s important because not thinking about it can make the whole feature useless. You can easily devolve into that spiral of “Hey I’ll just add a question mark or a bang to that to make the compiler shut up” and blindly make everything nullable or ignore the nullability because it creates so much friction to you.
Remember, nullability errors are there to help you but they don’t work without your investment.
I’ve got some tricks to help you in deciding on a variable’s or a property’s nullability easily:
Try to keep a mindset of making everything NON-NULLABLE by default unless they are, in fact, optional. Creators of C# 8.0 already did some of the work by making you show extra effort by putting a question mark at the end of the type but it’s still not that hard.Make sure that nullable members are nullable for good reason.One question to ask yourself when deciding on nullability is “do I have any plans for the absence of this value?”. If your answer is no, keep it non-nullable.Always use nullability as a mnemonic to signify what’s optional or not in your domain model. If your code expects the argument to always have a valid value, it simply can’t be null.Don’t fix compiler errors by changing your understanding of what’s optional or what’s required. Fix your model instead.and then comes the migration part, aka “the fun part”.
Don’t Do Everything At The Same TimeDo NOT switch to .NET Core 3.0 and nullable references at the same time. Switch to .NET Core 3.0 and make sure your code builds and runs fine first. Build and test your application. Then you can start switching to nullable references. You should always follow a minimal/incremental approach when refactoring large chunks of code. The other way never works.
Enabling Nullable ReferencesYou can enable nullable references partially or altogether. I usually prefer altogether because the warnings in a small project are so few that it’s not worth to do it incrementally. In order to enable it globally, add this to your project file in a PropertyGroup section:
enableIf you want to disable or enable nullable settings you can use compile-time directives:
#nullable enable// This part of code will make use of nullable references#nullable restore
// This part of code will run according to the global setting#nullable disable
// This part of code will have nullable references disabled#nullable restore
// This code will use global settings againTools Of The Trade
Nullable references come with some new syntactic elements to help you declare your intent better when handling potentially null values.
The “It’s Okay, I Know What I’m Doing” OperatorWhen you append “!” to an expression, it means that “I know that this expression can have a null value theoretically but I’m sure that it will never be null and I bet my application’s lifetime on it, because I know that my app will crash if it ever becomes null”. It’s especially useful in class and struct declarations where compiler complains about property or field not being assigned a value in the constructor.
Example:
string? s1 = "Hello";string s2 = s1!; // compiler error avoidedThe “This Parameter Will Never Be Null” Code Contract
Sometimes, you have to declare your function accepting nullable parameters because of the interface you’re implementing or because of the base class you inherited from but you are actually sure that it will never be null. The compiler will complain about you not checking the nullability of the value yet you know that it’s impossible. So you add an assumption contract:
public void Process(string? s){
Contract.Assume(x != null);
Console.WriteLine(s);
}Entity FrameworkUninitialized Properties in EF Entities
The compiler will complain about your EF entity declarations that they don’t initialize their properties. If you don’t want to add a custom constructor code, you can simply bypass the compiler error by adding “= null!;” to non-nullable properties.
Before nullable references:
[Required]public string FirstName { get; set; }
With nullable references:
public string FirstName { get; set; } = null!;The advantage of using non-nullable references over using Required attributes with nullable references is that the C# compiler will still be checking some illegitimate uses of the null assignment (e.g. you won’t be assigning a nullable version of the same data type to this field).
I just learned that EF Core also supports custom constructors for object instantiation as long as the parameter names in the constructor matches with the properties by name sans casing, which is great news!
Before nullable references:
[Required]public string FirstName { get; set; }public string MiddleName { get; set; }
With custom constructors:
public string FirstName { get; set; }public string? MiddleName { get; set; }public Person(string firstName){
FirstName = firstName;
}
Although we don’t have “middleName” in the parameter list, EF will still assign MiddleName property correctly after calling the custom constructor. So you can limit your custom construction code to required properties only.
This approach can be more involved than adding null! to properties but definitely the most correct way because it’s impossible to make a mistake in the code.
The [Required] AttributeThe use of the Required attribute isn’t required (!) anymore with EF Core 3.0. Nullability is decided by the existence of “?” at the end of the data type.
Before nullable references:
public class Person{
[Required]
public string FirstName { get; set; } // NOT NULL public string MiddleName { get; set; } // NULL
}
With Nullable references enabled:
public class Person{
public string FirstName { get; set; } = null!; // NOT NULL public string? MiddleName { get; set; } // NULL
}
The `= null!` allows the compiler to bypass the “property not initialized” errors for EF entities. Use this only with EF entities. For other classes, create a constructor instead (see the part about uninitialized properties).
Dereference of a possible null referenceC# compiler shows this warning when you define a query with nullable relationships in it. Consider this code:
var parentPosts = db.Posts.Where(p => p.ParentPost.Id == postId)
.ToList();
Here, p.ParentPost can in fact be null, but EF Core doesn’t actually care about this. So you just need to make the compiler happy by saying “this won’t be an issue, I guarantee you”:
var parentPosts = db.Posts.Where(p => p.ParentPost!.Id == postId)
.ToList();ASP.NET Core MVCThe [Required] Attribute On Models
Since ASP.NET Core also needs to initialize the models out of thin air, you need to follow a pattern similar to Entity Framework, you get rid of the Required attributes and use nullability as the indicator of optionality.
Before nullable references:
public class RegistrationForm{
[Required]
public string FirstName { get; set; } // required field public string MiddleName { get; set; } // optional field
}public IActionResult MyAction([Required]RegistrationForm form)
{
if (form == null || !ModelState.IsValid)
{
return View();
}
// .. blabla
}
After nullable references:
public class RegistrationForm{
public string FirstName { get; set; } = null!; // required field public string? MiddleName { get; set; } // optional field
}public IActionResult MyAction(RegistrationForm form)
{
if (!ModelState.IsValid)
{
return View();
}
// .. blabla
}
What you need to pay attention to is not to apply any rule everywhere blindly. So don’t add != null to all of your properties, don’t add ! to all the data type that you were supposed to be checking for nullability. That kills the whole purpose of nullable references. Focus on how nullable references help you in avoiding bugs and try to think about nullability more than usual. Let the compiler fail and make sure you’re making the best decision when choosing how to solve problems.
That pretty much sums it up. I haven’t encountered any other issues while migrating to nullable references but I’ll publish more articles in the series if I happen to.
[image error]April 29, 2019
The Critique of The Night King
WARNING: This article might contain spoilers from Season 8 Episode 3 of Game of Thrones.
Everyone’s bashing the alliance at Winterfell about their clusterfuck battle tactics but I think Night King also performed really poorly. I’d like to point out some issues about his handling of total world destruction.
Night King Failed To Drive The NarrativeI think Night King failed in PR throughout the series. Here, you have the most impressive, fearful, terrifying, horror show of an army, you can raise dead at will who cannot be killed, yet your enemies don’t even know the half of the story. Nobody in Westeros knows about you. Some who do actually only know about some “white walkers”. Night King completely ignores propaganda and fails to infuse his agenda in the enemy.
Here we’re talking about some guy who can fly and raise dead at will. This can be a great disruption to the preparedness of the battle, cause uproar, political clashes. He is completely oblivious towards politics and psychological operations which makes him a shallow, single-dimensional leader.
Night King Failed To Be A Successful CommanderThere is one more commander in the history of fiction who sends armies to their death until they overflow the defense mechanism so it finally stops working: Zapp Brannigan from Futurama. To his credit, Night King has more than enough resources to allow such a tactic but he wastes precious resources that can be leveraged for the success. As evidenced in the series, the result of a battle is never known until the last minute.
Night King Failed To Create A Solid OrganizationOrganization comes with hierarchy, a healthy delegation of power. Night King actually accumulates all the power to himself. That level of overconfidence creates a weakness in the whole organization of the white walker army. First, it creates a single point of failure: killing Night King means total loss of war. Well, the white walkers seem to be connected to Night King through some spiritiual link so killing him makes the rest vanish, but, Night King could have employed living, too. But as I said, overconfidence creates weakness.
That level of accumulation of power deprives the rest of the organization of a critical asset: initiative. That’s why nobody cared to defend Night King or took measures for defense when he was about to slay Bran, because Night King was driving the whole command at the moment. Centralizing power was his utmost failure.
Night King Failed To Drive A VisionNobody among white walkers knew about Night King’s goal. They were dumb soldiers. We know that by how they never acted independently of Night King’s will. Night King relied on total loyalty over competence and failed to communicate his ambition with his colleagues.
Night King Underestimated The CompetitionThe way how Night King avoided to enrich his strategic approach to his ultimate goal and how he only recruited dumb soldiers in astronomical numbers actually points out how Night King sees the competition: also dumb. Bad data may cause bad results but bad assumptions certainly will. He didn’t research his subject, he didn’t plan extensively. He didn’t even take lessons from his former self: supposedly a human. He is not a robot as we can see he can show some attitude albeit mostly brash snobbery.
I don’t want this article to be a complete downer for the Night King though. He was able to create a functional army, breached The Wall, annihilated armies, inflicted fear and got a dragon which were no easy feats to say the least. So, his achievements are commendable but since he failed in his final goal, all he did was to have repaired the fault lines in Westeros among most of the rival dynasties. He did nobody else could, he united Westeros.
I’d easily give him a good 5/7 as the evil leader who wants to destroy everything.
[image error]

