
Jayanth Kumar's Blog
December 8, 2025
OME GOD

⭐️ PROLOGUE
The Four Yugas and the One Story All Religions Tell
Every civilization, every prophet, every scripture — from the hymns of the Ṛig Veda to the laments of the Old Testament, from the songs of the Avesta to the chants of the Nile — whispers the same ancient truth:
Time does not move like an arrow.
It moves like a wheel.
Hinduism names its spokes Satya, Treta, Dvapara, Kali — four Yugas spiraling through creation, decline, darkness, and rebirth.
Yet when you look deeply enough, the same fourfold rhythm pulses beneath Christian ages, Greek mythic eras, Islamic prophetic cycles, Buddhist kalpas, Norse epochs, and even the cosmology of Zoroaster and Egypt.
This is not coincidence.
This is a universal human memory.
A memory that resurfaced in symbols — Vishnu’s ten avatars, Christ’s four archangels, the Greek Ages of Man, the Jewish and Islamic Ages of Prophets, and the Zoroastrian story of Good and Evil fighting for cosmic time.
All religions keep trying to say one thing:
The universe breathes in cycles.
Every age has its guardian.
Every fall has its redeemer.
And every darkness awaits a rider of light.
This is that story — spanning all religions — told through the lens of the Yugas.
🌕 NARRATIVEThe Cycle of Ages Across All Religions
CHAPTER I — The First Age: Satya YugaThe Age When the World Was Young
Satya Yuga is the Golden Age, pristine and unbroken — where dharma stands on four legs, where truth is the only language, where consciousness is whole.
Every religion remembers a time like this:
Eden in Christianity and JudaismFirdaws in IslamThe Golden Age of Kronos in GreeceThe reign of Ahura Mazda in ZoroastrianismThe First Age of the Norse, before deceit was bornAcross these traditions, the first age is ruled not by kings but by purity itself.
In Hinduism, Vishnu’s earliest avatars — Matsya, Kurma, Varaha — preserve life, uphold the cosmic order, and stabilize the young universe.
In Christianity, the first age is guarded by Raphael, the healer.
In Islam, it is remembered as the age before corruption touched the earth.
In Greece, it is when humans “lived like gods, free from sorrow”.
Humanity begins in light.
But the wheel must turn.
The Age of Law, Ritual, and Divine Intervention**
As truth slightly diminishes, the world enters the Silver Age — still bright, but cracked with complexity.
This is the age of:
Vamana, who humbles kingsParashurama, who resets corrupted powerRama, the perfect kingAcross other religions, this age manifests as:
The Patriarchal Age (Judaism–Christianity–Islam)Abraham, Isaac, Jacob — the founding patriarchs — establish covenants, laws, and rituals.
Moses brings commandments.
The battle between truth (Asha) and falsehood (Druj) intensifies.
EgyptMaat (cosmic order) becomes something that must be maintained, not simply lived.
Treta Yuga is not innocence — it is responsibility.
Humanity begins to shoulder the weight of moral order.
CHAPTER III — Dvapara YugaThe Age of Doubt, Heroes, and Knowledge
Now dharma stands on two legs.
The world becomes heavier, more human, more uncertain.
This is the age of Krishna, the cosmic teacher who speaks the Gita in the twilight between divinity and war.
Across religions:
Christianity’s Prophets and KingsDavid, Solomon, Isaiah — wisdom, songs, doubts, poetry, rebellion.
Islam’s Prophetic LineEach prophet arrives in a world increasingly divided.
Greek Bronze AgeHeroes rise and fall.
Knowledge expands.
Conflicts darken.
Job questions suffering.
Ecclesiastes questions life itself.
Dvapara is the age where humanity asks for meaning and receives paradox.
Divinity becomes philosophical.
Faith becomes inquiry.
CHAPTER IV — Kali YugaThe Age of Iron, Fire, and Forgetting
The darkest age — yet the most self-aware.
This age is not purely evil.
It is the age where consciousness hits its minimum — which paradoxically makes awakening possible.
Kali Yuga appears everywhere:
ChristianityThe “Last Days”The rise of conflictThe prophecy of the rider on the white horseIslamThe fitna (age of trials)The arrival of the MahdiThe return of IsaZoroastrianismThe age of greatest deceitAwaiting Saoshyant, the world-renewerNorse MythologyThe time before RagnarokThe world-tree shakingBuddhismThe age of Dharma-decline, awaiting MaitreyaHinduismThe age of industrial noise, forgotten rituals, inward corruptionAwaiting Kalki, the avatar who restores dharmaEvery tradition speaks of an impending renewal — a final avatar, messiah, savior, or rider who breaks the cycle of decay.
Darkness brings longing.
Longing brings awakening.
Awakening brings rebirth.
Thus the wheel turns.
CHAPTER V — Ten Avatars Across All ReligionsWhen Deities Wear Different Names**
The Dashavatara is not uniquely Hindu — it is the Indian expression of a global archetype.
Matsya ↔ Noah / Nuh / UtnapishtimThe flood hero appears everywhere.
Kurma ↔ Atlas / ShuThe cosmic supporter.
Varaha ↔ Marduk / St. MichaelOrder defeating chaos.
Narasimha ↔ Angel of the Lord / KhidrJustice that manifests beyond rules.
Vamana ↔ Christ’s Parable of MeeknessSmallness containing infinity.
Parashurama ↔ MosesRighteous destruction to restore law.
Rama ↔ Solomon / ApolloThe archetype of the just king.
Krishna ↔ Christ / Dionysus / HermesDivine love, cosmic play, philosophical clarity.
Buddha ↔ Jesus the Reformer / Isa / MaitreyaCompassion reshaping tradition.
Kalki ↔ Messiah / Mahdi / Saoshyant / BaldrThe world-renewer on a white horse.
All religions arrive at the same figure:
the final rider who ends the dark age.
The Cosmic Unity We Forgot
While Vishnu governs the flow of incarnations, Shiva stands behind the cycle itself.
Shiva is Mahākāla — Time.
Shakti is Prakṛti — Space.
In Greek myth, these appear as:
Kronos — devouring timeGaia — the womb of worldsIn Hinduism they merge as:
ArdhanārīśvaraHalf Shiva, half Shakti.
Half Time, half Space.
A single reality with two faces.
The universe is born when Time moves through Space.
And dissolves when Time consumes Space back into silence.
Every religion echoes this nondual truth in its own way — the union of opposites, the marriage of heaven and earth, yin and yang, spirit and matter.
Ardhanārīśvara is the hidden equation beneath all mythologies.
⭐️ EPILOGUEThe One Story Beneath Every Scripture
When the names are removed — when Vishnu, Christ, Muhammad, Zoroaster, Abraham, Buddha, and the Greek poets step aside — the pattern remains.
A pattern older than temples.
Older than languages.
Older than writing.
Creation
Decline
Forgetfulness
Renewal
The Yugas are not just Hindu cosmology.
They are the blueprint of human consciousness.
Every religion remembered a piece of the puzzle.
Hinduism preserved the cycle.
Abrahamic traditions preserved the prophets.
Greek myth preserved the psychology.
Zoroastrianism preserved the ethical battle.
Buddhism preserved the meditative mapping.
Put together, they form a single revelation:
There is only one story.
Humanity keeps telling it in different tongues.
And time — sacred, circular, eternal time — keeps turning its luminous wheel.
[image error]
Time
Time is beauty.
Beauty is divine. (सत्यम शिवम् सुंदरम् )
Flowing cyकाल
Cycle
OME GOD was originally published in Technopreneurial Treatises on Medium, where people are continuing the conversation by highlighting and responding to this story.


October 30, 2025
Evolution of Research: From Foundations to Frontier
 In Memory of Pushpak Bhattacharyya, Computation For Indian Language Technology (CFILT) Lab, CSE at IIT Bombay and Indian Institute of Technology, PatnaPrologue
In Memory of Pushpak Bhattacharyya, Computation For Indian Language Technology (CFILT) Lab, CSE at IIT Bombay and Indian Institute of Technology, PatnaPrologueEvery discipline carries within it an invisible tapestry — threads woven from questions posed, methods tested, insights harvested, and new frontiers charted. In natural language processing (NLP), the culture of inquiry grows like roots and branches, nurtured by each generation of scholars, then passed on. These traditions become the unspoken curriculum, the scaffolding behind breakthroughs years later. If we liken this to a silent transmission — like Bodhidharma’s oral transmission of the Vedas — then one of these foundational threads is the study of opinion summarization.
Opinion summarization is more than summarising text: it is distilling sentiment, aspect, voice — the kaleidoscope of human evaluation. The journey from modelling to evaluation to generative systems in this domain offers a textbook of how academic research evolves: from fundamental theory, to critique, to benchmark, to next-gen system. This article traces one such chain — and in doing so I honour Prof. Pushpak Bhattacharyya, whose work anchors the foundation of this chain.
The Journey of an Idea1. Foundations (2015)In 2015, the paper Monotone Submodularity in Opinion Summaries (Jayanth Jayanth, Jayaprakash Sundararaj & Pushpak Bhattacharyya) laid a rigorous foundation: summarizing opinions is not simply picking frequent phrases — it is a problem of coverage, redundancy, and sentiment intensity. They framed it as a monotone submodular optimisation problem: adding sentences increases subjectivity (monotonicity) but the benefit per additional sentence diminishes (diminishing returns). CSE IIT Bombay Paper in EMNLP This work put the lens of optimisation theory onto opinion summarisation, setting a formal bedrock.
2. Critical Evaluation (2019)Fast-forward to 2019: the paper Red‑faced ROUGE: Examining the Suitability of ROUGE for Opinion Summary Evaluation (Tay W; Joshi A; Zhang X; Karimi S; Wan S) challenged one of the core tools of summarisation research: ROUGE. They showed that for opinion summaries — where what is said (aspect) and how it is said (polarity) matter — ROUGE’s overlap-based scoring fails to distinguish correct versus opposite sentiment. ACL Anthology Paper This was an inflection point: the evaluation metric, not just the method, required scrutinising.
3. Benchmarking Evaluation (2023)In 2023, the work OpinSummEval: Revisiting Automated Evaluation for Opinion Summarization (Shen Z & Wan S) picked up the mantle of evaluation. They built datasets and metrics aligned with human judgement for opinion summarisation — implicitly motivated by the 2019 critique of ROUGE. arXiv Paper Thus the academic attention shifted from “how do we build summaries?” to “how do we evaluate them correctly?”
4. System-level Innovation (2025)Finally, the 2025 paper LLMs as Architects and Critics for Multi‑Source Opinion Summarization (Attri A; Attri A; Bhattacharyya P; Banerjee S; Patil A; Chelliah M; Garera N) synthesises the prior threads into a next-generation system: multi-source input (reviews + metadata + QA) and large language models (LLMs) as both architects (generators) and critics (evaluators). The paper cites the 2023 evaluation benchmark explicitly and builds upon the evaluation concerns raised earlier. This brings the research arc full circle: modelling → evaluation critique → benchmark → system innovation.
Directed Acyclic Graph (DAG) of the Research Chain[2015: Monotone Submodularity in Opinion Summaries]↑
│ (influence and citation)
[2019: Red-faced ROUGE]
↑
│ (evaluation benchmark build)
[2023: OpinSummEval]
↑
│ (cited by & extended in system paper)
[2025: LLMs as Architects & Critics]
Graphviz representation
digraph Evolution {node [shape=box];
P2015 [label="2015 – Jayanth et al.\nMonotone Submodularity"];
P2019 [label="2019 – Tay et al.\nRed-faced ROUGE"];
P2023 [label="2023 – Shen & Wan\nOpinSummEval"];
P2025 [label="2025 – Attri et al.\nLLMs as Architects & Critics"];
P2019 -> P2015;
P2023 -> P2019;
P2025 -> P2023;
}Table of Key Contributions
 Reflection: The Lifecycle of ContributionVision & Formalisation — The 2015 paper gave us a rigorous lens.Scrutiny & Weaknesses — The 2019 paper exposed the weak link in evaluation metrics.Infrastructure & Benchmarking — The 2023 work built the tools needed to measure progress correctly.Integration & Scale — The 2025 work delivered the system that synthesises earlier theory, metrics, and technology into a modern paradigm.
Reflection: The Lifecycle of ContributionVision & Formalisation — The 2015 paper gave us a rigorous lens.Scrutiny & Weaknesses — The 2019 paper exposed the weak link in evaluation metrics.Infrastructure & Benchmarking — The 2023 work built the tools needed to measure progress correctly.Integration & Scale — The 2025 work delivered the system that synthesises earlier theory, metrics, and technology into a modern paradigm.This is how research advances: each stage feeds the next. Foundational ideas enable critique; critique drives benchmarking; benchmarking supports system innovation.
In Memory of Prof. Pushpak BhattacharyyaProf. Bhattacharyya’s work with Jayanth K. in Computation For Indian Language Technology (CFILT) Lab , especially his contribution to the 2015 paper, holds a central place in this journey. His insights into opinion summarisation modelling continue to ripple through the field. This article stands as a tribute to his legacy — thank you for shaping the path of advance.
 Epilogue
EpilogueIn the end, research is not just the publication of papers — it’s the weaving of ideas across time, the lifting of standards, the challenging of assumptions, the building of new systems. The chain we charted — 2015 through 2025 — is but one example of many. But for us, it is instructive: build on sound theory, be ready to critique the foundations, create robust measurement, then dare to build at system scale. That is the path to meaningful progress.
“May we all stand on the shoulders of past giants, reach further, and leave a foundation for future ones.” — Jayanth K.
ReferencesJayanth K. , Jayaprakash Sundararaj , & Pushpak Bhattacharyya (2015). Monotone Submodularity in Opinion Summaries. In Proceedings of EMNLP 2015, 169–178. DOI:10.18653/v1/D15–1017. CSE IIT Bombay Paper in EMNLPTay, W., Aditya Joshi , Zhang, X., Karimi, S., & Wan, S. (2019). Red-faced ROUGE: Examining the Suitability of ROUGE for Opinion Summary Evaluation. In Proceedings of ALTA 2019, 52–60. ACL Anthology PaperShen, Z., & Wan, S. (2023). OpinSummEval: Revisiting Automated Evaluation for Opinion Summarization. arXiv:2310.18122. arXiv PaperAttri, A., Attri, A., Bhattacharyya, P., Banerjee, S., Patil, A., Chelliah, M., & Garera, N. (2025). LLMs as Architects and Critics for Multi-Source Opinion Summarization. arXiv:2507.04751. arXiv Paper[image error]Evolution of Research: From Foundations to Frontier was originally published in Technopreneurial Treatises on Medium, where people are continuing the conversation by highlighting and responding to this story.
October 15, 2025
The Cure Is Reflection: When Life Remembers Itself
Reflection and Refraction — Dual Manifestation
Neural Node Theory: The Tree That Awakes
Duality of Neurons and Nodes
January 24, 2025
A Pendulum Swung Too Far — Again
 Prologue
PrologueIn the unending quest to build intelligent systems, we find ourselves at a crossroads once again. The march toward Artificial General Intelligence (AGI) is dazzling, relentless, and, at times, utterly blinding. For every breakthrough, there is an unspoken undercurrent: Have we swung too far — again?
Swing of the PendulumProgress, like a pendulum, oscillates. It does not move in a straight line. It sweeps from one extreme to another, dragging entire fields of inquiry with it. In Kenneth Church’s brilliant paper, “A Pendulum Swung Too Far,” he chronicles this very phenomenon in the evolution of computational linguistics. Rationalism gave way to Empiricism, theoretical rigor bowed to data-driven pragmatism, and somewhere along the way, the pendulum reached its apex.
Today, in the AGI revolution, we see the pendulum swinging with similar ferocity. Scaling dominates our collective psyche. Compute, data, and parameter counts — these are the new gods of progress. We marvel at their power, but do we pause long enough to ask: What are we leaving behind in their shadow?
History as a MirrorIn the 1990s, for example, empiricism surged because we suddenly had access to unprecedented amounts of data. Researchers pragmatically tackled simpler, solvable tasks like part-of-speech tagging instead of obsessing over AI-complete problems. But as Church highlights, this pragmatism has its limits. Many of these methods (like n-grams and finite-state systems) work well for short-distance dependencies but fail to capture the big picture — long-distance dependencies and deeper linguistic insights.
Church reminds us that in the 1990s, the rise of empiricism was a necessary corrective. Data had become abundant, and researchers, reeling from the overpromises of earlier decades, turned to pragmatic, solvable problems. But in the heady rush to harness data, foundational questions — those dealing with long-distance dependencies and the nature of meaning itself — were left by the wayside.
Empiricism’s triumphs were real but limited. Methods like n-grams and finite-state systems delivered results, but they could not grasp the deeper, more intricate fabric of language. It was only later, when the pendulum began to swing back, that the field reconnected with these deeper truths.
And now, AGI finds itself at a similar inflection point. Scaling — massive models, billions of parameters, unfathomable compute — has delivered stunning results. But let us not mistake these results for true intelligence. Let us not forget that scaling, like empiricism before it, is a means, not an end.
Often breakthroughs come from revisiting the so-called “limitations.”The Illusion of Progress
Here lies the bitter truth: the systems we celebrate today — transformers, large language models — excel at optimization but falter at understanding. They are pattern matchers, not philosophers. They mimic intelligence but do not embody it.
Church’s pendulum teaches us that this is not failure; it is inevitability. Progress is cyclical. The limitations we ignore today will become the fertile ground of tomorrow’s breakthroughs. The deeper truths of AGI — reasoning, causality, adaptability — are waiting to be rediscovered, just as syntax and semantics waited in the shadows during the empirical rush of the 1990s.
Scaling will plateau. It always does.
And when it does, we will be forced to confront the questions we have deferred:
What does it mean to reason?How do systems adapt to the unknown?Can intelligence exist without understanding?The Duality of AGI: Scale vs. DepthIf there is a lesson here, it is this:
Progress requires duality.
Scaling and depth, pragmatism and philosophy, engineering and science — these are not opposites. They are partners, two sides of the same coin. To swing too far toward one at the expense of the other is to court stagnation.
The AGI revolution will not be won by scaling alone. The next great leap will come from harmonizing brute computational power with the subtlety of human-centric design. It will come from systems that do not just predict but understand, that do not just scale but adapt.
A Manifesto for BalanceTo those working at the edge of AGI, here is the manifesto:
Revisit the Forgotten: The past holds treasures. Concepts dismissed as too narrow or outdated often contain the seeds of innovation. Look back to move forward.Scale with Purpose: Scaling is a tool, not a destination. Use it to explore deeper questions, not as an end in itself.Celebrate the Specific: Task-specific insights are not limitations; they are foundations. The leap to generality begins with mastery of the particular.Bridge the Divide: Refuse to choose between pragmatism and philosophy. Build systems that honor both.Question the Easy Wins: The low-hanging fruit of scaling will run out. Prepare now for the harder, higher-hanging challenges of reasoning, adaptability, and true intelligence.The balance will come from accepting this duality: leaning into computational scale while staying grounded in the nuances of human-centric modeling.
MessageDon’t despair if your work feels task-specific or narrow. The intuitions you develop today could inspire a leap forward tomorrow. Keep looking for concepts that feel both powerful and general, and don’t shy away from asking, “How do we scale this?”. As Church warns, we need to strike a balance. Scaling is crucial, but let’s not lose sight of foundational challenges.
Low-hanging fruit is great, but we can’t stop there.Epilogue
The pendulum will swing again — it always does.
Scaling will give way to introspection, and the glittering achievements of today will become the stepping stones of tomorrow. Whether you’re in machine learning, computational linguistics, or another domain, remember:
Progress isn’t linear — it oscillates. And in that back-and-forth, every step matters and in that oscillation lies the beauty of discovery.
The AGI revolution is not just a race to build bigger models. It is a journey to understand the essence of intelligence itself. And in this journey, every step matters.
What do you think? Are we, as a community, striking the right balance? Or are we destined to repeat the cycles of history, swinging too far before we swing back?
Let’s reflect — and, more importantly, let’s act.
[image error]A Pendulum Swung Too Far — Again was originally published in Technopreneurial Treatises on Medium, where people are continuing the conversation by highlighting and responding to this story.
June 10, 2023
Building Configurability in SaaS
 Prologue
Prologue Every change breaks someone’s workflow. (credits: xkcd comics)
Every change breaks someone’s workflow. (credits: xkcd comics)So, you have decided to build a data-driven Software as a Service (SaaS) start-up after reading my old article — To pivot or not to pivot but after deciding on the business requirements of your application, you start contemplating what will be the right configurability of the software based on your requirements. You revisit the possible options for configurability, relook at the business requirements, and then, comes the problem:
The ProblemAs you continue to build your new SaaS application and sell it, there is another critical aspect that demands your attention: building and managing configuration properly. The configuration of your application, including its technical and business settings, becomes crucial for ensuring the security, privacy, durability, and configurability of your SaaS.
In the following sections, we will explore the difficulties and importance of building application configuration correctly in the context of SaaS, providing insights and guidelines to help you navigate this complex landscape effectively.
The SolutionConfigurability is a crucial requirement for any SaaS application, encompassing both technical and business needs. To address this, configurations are divided into two categories: technical configuration (referred to as the application manifest) and business configuration (referred to as settings and preferences). It is vital to keep both configurations separate from the code for security, privacy, durability, and ease of customization. Let’s explore each in detail:
Application ManifestThe application manifest consists of technical configurations that are specific to the application and may vary across different deployments, such as staging, production, or developer environments. It typically includes:
● Resource handles for databases, caches, and other supporting services.
● Credentials for external services like Amazon S3 or Twitter.
● Deploy-specific values like the canonical hostname.
According to the 12-factor app manifesto, these configurations should be stored in the environment. The manifest should support versioning, not only for the application but also for the manifest itself, including the manifest schema and versioning.
Guidelines
Some of these guidelines are adopted from the twelve-factor app methodology.
● Configuration settings should be stored and maintained as close as possible to the environment they apply to.
Placing application settings near the application clarifies their association. From a security standpoint, these settings can only be accessed and modified within their corresponding environment. For production settings like connection strings and passwords, it is essential to limit access. Application-specific settings should reside alongside the code or in the root of the application, while platform-specific settings should be available at a higher level, such as environment variables or web server settings. Website-specific settings should not be accessible at the web server’s root.
● Configuration settings should contain only environment-specific settings.
To maintain simplicity and clarity, configuration files should only include environment-specific settings such as caching, logging, and connection strings. All other settings should be configurable within the application itself.
● Configuration settings, especially secrets, should not be stored under version control.
Storing environment-specific settings (e.g., passwords, connection strings, tokens) in version control is a security risk. These values should be set and stored as close to their respective environments as possible, following a “just-in-time” mindset. Better use Github’s encrypted secrets or Gitlab’s secrets.
● There should be a single location for configuring application settings.
Application settings should be configured as close to the application as possible. Introducing multiple configuration locations leads to chaos and insecure maintenance.
● Configuration values should be automatically set during deployment.
To streamline the process of configuring multiple environments and settings, it is advisable to automate the configuration process during deployment. This ensures repeatability and reduces the likelihood of errors.
● Changing a configuration setting should not necessitate a new deployment.
Most often an application resource (for example, a web application) relies on a core resource (for example, a storage account). An application resource is dependent on the existence of this core resource and needs its settings to run properly. For example, a web application needs a storage account key to access a blob storage, or a frontend needs an URL and token address to access an API. Changes in the core resource and its settings shouldn’t result in a redeploy of the application resource, which relies on it. When an API has many unknown clients changing the URL shouldn’t impact these clients. This can be challenging but there are many solutions for it.
Realization
They can be more Platform-centric like settings for Cloudfoundry or application-centric like GE Predix Apphub Configuration. For example, these are the common attribute sets for manifest for Cloudfoundry:
● Buildpack/Image
● Command
● Instances
● Memory quota
● Disk quota
● Health Check (endpoint, timeout and type — port, process, http)
● Metadata, path, and routes
● Environment Variables
● Services
Architecture
The application manifest configuration, which can be realized as the key-value store can be coupled with the service registry and service discovery while load balancing can be coupled with the reverse proxy router for the services (health-checking can be supported by either). Some of the tools for service configuration are:
● Consul
● Etcd
● Eureka
The most used Consul provides first-class support for service discovery, health checking, and Key Value storage for configuration. Eureka only solves a limited subset of problems of health-checking, service registry, and discovery, expecting other tools such as ZooKeeper as a distributed key-value store to be used alongside. Etcd is the most lightweight and serves only as a strongly consistent configuration key-value store. Both Consul and Etcd are written in Golang while Zookeeper and Eureka are written in Java.
Manifest Specification Formats
The manifest can be specified on either YAML or JSON. One of the benefits of specifying in YAML is to share the configuration through YAML anchors and aliases, which provides the ability to reference other data objects. With this referencing, it is possible to write recursive data in the YAML file. On the other hand, JSON has better serialization-deserialization support across languages and is more suited for API transport.
Apart from the manifest, these technical configurations can also be directly handled in a separate application like Settings microapp from GE Predix, but that is more suited to configure business settings and preferences, which is discussed in detail next.
Settings and PreferencesSettings and Preferences encompass the specific requirements of a business, catering to various levels such as tenants, applications, and users. These settings primarily include format settings like time format, currency format, and metric format, as well as internationalization and localization settings. Additionally, preference settings allow users to customize their dashboard display arrangement. It is advisable to store these settings in a datastore to ensure their persistence during platform and version upgrades, as well as their availability for cross-application and cross-user sharing.
Guidelines
To effectively manage Settings and Preferences, the following guidelines should be followed:
● Settings and Preferences should be stored and maintained in the datastore, ensuring their centralized management.
● Settings and Preferences should be able to be set in the application itself, allowing for customization.
● Settings and Preferences should be configurable at multiple levels i.e. tenant-specific, application-specific, and user-specific.
● Settings and Preferences should have standard defaults, initialized as the application or platform constants to ensure consistency.
● Settings and Preferences should be persisted cross-deployment and application versions to maintain continuity and avoid data loss.
Realization
They can be more application-centric like settings for Django Application or application-centric like GE Predix Microapp Settings. For example, these can be the common settings based on the above:
● Timezone
● Country
● Locale
● Currency
● Units of Measurement
● Input and Output Formats (Date, DateTime)
● Separators (Thousand, Decimal)
● Symbols (Language, Currency)
● Themes (Links, Display)
● Display Arrangement and Ordering
Architecture
The preferences can be implemented as a three-layer hierarchy similar to read-write-execute settings for user-groups-others on Linux.
We can have a similar set of actors in the system:
1. Admin
2. User
3. Groups
4. Others (default)
Similarly, we can have a similar set of principals in the system:
1. System (default)
2. Tenant
3. Application
We have the following actions on Settings and preferences in the system:
1. Read
2. Write
3. Delete
The permissions of the actors over the principal’s configuration will follow these permission-based restrictions, where R stands for Read, W for Write, and D for Delete :
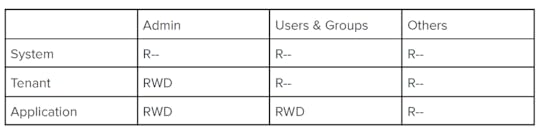 Configuration Permission Model
Configuration Permission ModelFor actors, Admin has the highest privileges and can read, write or delete the configuration for all except System, which holds default values. Users and user groups can only change their specific application settings and configurations. Anonymous Unauthenticated users can just read the application configurations. For principals, the application configuration will take priority over tenant configuration, and the tenant configuration will take priority over System configuration, which will be set of smart defaults. Here, priority implies an inheritance model, where the application will override tenant configuration and will inherit it, if it is not set locally. Similarly, tenants will override system configuration and will inherit it as it is, if the admin does not configure the tenants.
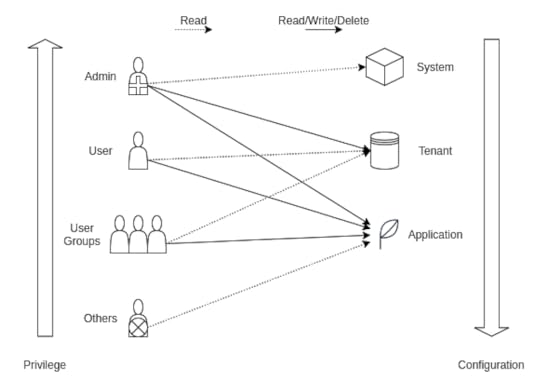 SaaS Privilege-based Configuration Model
SaaS Privilege-based Configuration ModelThe ability to configure settings and preferences at different levels, such as tenant-specific, application-specific, and user-specific, provides a high degree of customization and personalization. This flexibility allows your application to cater to diverse user needs and preferences, enhancing the overall user experience.
EpilogueAs you continue your journey towards building a highly scalable and flexible system, it is crucial to emphasize the importance of following the above guidelines for building application configurability.
The importance of technical configuration becomes even more evident when considering the challenges associated with cloud enterprise software and SaaS solutions. With the adoption of microservices and a distributed architecture, the management of multiple servers, caches, and databases can become complex. Proper configuration management simplifies this process, allowing you to effectively allocate resources and optimize performance.
Furthermore, storing and maintaining settings and preferences (business configuration) in a datastore ensures their persistence across platform and version upgrades. This not only saves time and effort but also enables seamless sharing of configurations across different applications and users. Having standard defaults and initialization as the application or platform constants ensures consistency and ease of use. By adhering to these guidelines, you ensure that your application can adapt to varying requirements and scenarios.
In conclusion, by following the guidelines for building application configurability, you empower your SaaS solution with the necessary flexibility, adaptability, and scalability.
Solve the problem once, use the solution everywhere![image error]
Building Configurability in SaaS was originally published in Technopreneurial Treatises on Medium, where people are continuing the conversation by highlighting and responding to this story.
May 25, 2023
The Right Approach to Effective Code Reviews
 Prologue
PrologueSo, you have inculcated the “right attitude” for software engineering after reading my old article — The Right Approach to Software Engineering but you are working in a silo in a small team or a startup, churning a lot of code. You start wondering whether you are making the right architectural decisions, producing good-quality code, and properly, maintaining the software, that you are building. You often face the same set of operational issues after deploying, which makes you revisit your repository, relook at the code, check the code quality using code analyzers like Codacy and SonarQube, and then, realize the problem:
ProblemYou have been churning out poor-quality code, with the same set of design issues, inconsistent style, and bugs, all adding up to a lot of technical debt. Now, you want to improve your technical know-how, improve the software quality as well as reduce the technical debt of the code, you are churning out.
Software Engineers, when working in silos end up producing poor-quality code and struggle with learning patterns and anti-patterns of software design. Without the right guidance and review of your common design issues, errors, and bugs, you end up making the same code quality mistakes again and again, which eventually adds to the technical debt and poor software maintainability.
SolutionIf you are working in a team, you should definitely do code reviews to improve both your own skills and the quality of the codebase and foster knowledge sharing and collaboration, contributing to a positive development culture.
Let’s understand what, why, and how of effective code reviews.
What is code review? Code Mocking — An Engineering Tradition (credits: Dilbert comics)
Code Mocking — An Engineering Tradition (credits: Dilbert comics)Code review is a process in software development where one or more developers systematically examine and evaluate the code written by their peers. It involves reviewing the code for quality, correctness, adherence to coding standards, best practices, and overall maintainability. Code reviews are typically conducted before merging code changes into a shared codebase, aiming to catch bugs, improve code design, identify potential issues, and ensure that the code meets the requirements and expectations of the project. The goal of code review is to enhance the overall code quality, promote collaboration and learning within the development team, and ultimately deliver reliable and maintainable software.
Why do code reviews? Wanna see the code (credits: xkcd comics)
Wanna see the code (credits: xkcd comics)Code reviews serve several important purposes in software development:
1. Bug Detection: Code reviews help identify bugs, logic errors, and other issues in the code before they reach production. Reviewers can catch mistakes that the original developer might have missed, leading to higher quality and more reliable software.
2. Knowledge Sharing and Learning: Code reviews provide an opportunity for developers to learn from each other. Reviewers can share their expertise, suggest improvements, and introduce new techniques or best practices. It promotes collaboration within the team and helps in spreading knowledge across the organization.
3. Code Quality and Consistency: Code reviews help maintain a high level of code quality and consistency throughout the codebase. By following coding standards, best practices, and design patterns, reviewers can ensure that the codebase is maintainable, readable, and adheres to the established guidelines.
4. Continuous Improvement: Code reviews foster a culture of continuous improvement. Through constructive feedback and discussions, developers can refine their coding skills, enhance their understanding of the project, and identify areas where they can improve their code.
5. Team Building and Accountability: Code reviews encourage collaboration and team building within the development team. It creates a shared responsibility for the codebase, as developers review each other’s work and provide feedback. It also helps establish a sense of accountability, as developers are held responsible for the quality and reliability of their code.
Overall, code reviews contribute to better software quality, improved developer skills, and a more cohesive and efficient development process.
It’s better to succeed together than to fail alone.How to comment the code?
 Bad code (credits: xkcd comics)
Bad code (credits: xkcd comics)Commenting code is an essential practice in software development as it helps improve code readability, maintainability, and understanding. Here are some guidelines for effective code commenting:
1. Use Clear and Concise Comments: Write comments that are easy to understand and concise. Avoid ambiguous or vague comments that can lead to confusion. Comment only where necessary and focus on explaining the intent or purpose of the code.
2. Comment Purpose and High-Level Logic: Comment on the overall purpose and functionality of the code block or function. Explain the high-level logic and any important decisions made during the implementation. This helps other developers understand the code’s intent without diving into the implementation details.
3. Document Complex or Non-Obvious Code: If the code contains complex algorithms, non-trivial logic, or intricate business rules, provide comments to explain how it works. This helps other developers, including your future self, comprehend the code more easily.
4. Use Self-Explanatory Variable and Function Names: Naming variables and functions descriptively can eliminate the need for excessive comments. When code is self-explanatory, it becomes easier to understand without relying heavily on comments.
5. Comment Tricky or Non-Standard Code: If you encounter code that deviates from standard practices or uses workarounds, provide comments to explain the reason behind it. This helps prevent others from mistakenly considering it as an error or making unnecessary changes.
6. Update Comments with Code Changes: When you modify code, ensure that you update the corresponding comments to reflect the changes accurately. Outdated comments can be misleading and cause confusion.
7. Avoid Redundant Comments: Avoid commenting on obvious code or duplicating information that is already apparent from the code itself. Redundant comments can clutter the code and make it harder to read.
8. Use Comment Styles Consistently: Follow consistent comment styles and formatting conventions throughout the codebase. This helps maintain a unified and organized appearance.
Remember that comments should complement the code and provide valuable information that enhances understanding. Well-placed and meaningful comments can significantly improve the readability and maintainability of your codebase.
There are only two hard things in Computer Science: cache invalidation and naming things.How can it help me as a developer to do code reviews of other developers?
 Code Quality (credits: xkcd comics)
Code Quality (credits: xkcd comics)Performing code reviews of other developers’ work can greatly benefit you as a developer in several ways:
1. Enhancing Code Quality: Code reviews provide an opportunity to identify and address potential issues, bugs, or inefficiencies in the codebase. By reviewing other developers’ code, you can catch mistakes or suggest improvements, leading to higher code quality.
2. Learning Opportunities: Code reviews expose you to different coding styles, techniques, and problem-solving approaches. You can learn from the strengths and weaknesses of others’ code, gaining insights into new patterns, best practices, and innovative solutions.
3. Collaboration and Teamwork: Code reviews promote collaboration and foster a sense of shared responsibility within the development team. Through the review process, you can engage in constructive discussions, share knowledge, and work together to improve the overall codebase.
4. Consistency and Standards: Code reviews help maintain consistency and adherence to coding standards across the project. By reviewing code, you can ensure that the codebase follows established guidelines, naming conventions, formatting rules, and other project-specific requirements.
5. Knowledge Sharing: Code reviews facilitate knowledge sharing among team members. As you review the code, you can provide explanations, suggest alternative approaches, and offer guidance. This sharing of knowledge benefits both the developer whose code is being reviewed and the reviewer.
6. Identifying Patterns and Anti-patterns: Code reviews allow you to identify recurring patterns or anti-patterns in the codebase. By recognizing such patterns, you can propose refactoring opportunities, suggest code reuse, or identify areas where design patterns can be applied.
7. Error Prevention: Code reviews act as a preventive measure against introducing bugs or issues into the codebase. By thoroughly reviewing code, you can identify potential pitfalls, evaluate edge cases, and spot logic errors before they reach the production environment.
8. Continuous Improvement: Code reviews promote a culture of continuous improvement within the development team. By providing constructive feedback and suggestions, you contribute to the growth of individual developers and the overall team’s skills.
By actively participating in code reviews, you can contribute to a positive development culture and improve both your own skills and the quality of the codebase.
The more you help people, the stronger you get.How should I do code reviews? How to learn it?
 Code Quality 2 (credits: xkcd comics)
Code Quality 2 (credits: xkcd comics)To effectively conduct code reviews, consider the following steps and tips:
1. Set clear expectations: Establish guidelines and standards for code reviews within your team or organization. Define the goals of code reviews, the scope of review, and the expected timeline.
2. Review the code independently: Start by examining the code on your own, without any distractions. Understand the purpose, functionality, and design choices made in the code.
3. Follow a checklist: Use a checklist or a set of predefined criteria to ensure thoroughness and consistency in your code reviews. This can include aspects like code style, readability, performance, security, error handling, and adherence to best practices. For example, check for code smells and then, resolve code smells using refactoring techniques.
4. Provide constructive feedback: When you identify areas for improvement, offer clear and specific feedback. Explain the issues you’ve found and suggest possible solutions or alternative approaches.
5. Prioritize and categorize feedback: Differentiate between critical issues that need immediate attention and minor suggestions for improvement. Organize your feedback to help the developer understand the importance and impact of each comment.
6. Be objective and impartial: Focus on the quality of the code and adherence to established standards, rather than personal preferences. Base your feedback on objective criteria and best practices.
7. Balance between nitpicking and high-level feedback: While it’s important to catch small issues, also provide feedback on the overall design, architecture, and problem-solving approach. Find the right balance between detailed suggestions and high-level guidance.
8. Foster collaboration and learning: Code reviews should be seen as an opportunity for growth and knowledge sharing. Encourage open discussions, ask questions, and be receptive to different perspectives. Promote a culture of continuous learning and improvement.
9. Document your feedback: Keep a record of the feedback you provide, either through comments in the code review tool or in a separate document. This helps track progress and allows developers to refer back to the feedback.
10. Learn from others: Participate in code reviews of your peers and learn from their feedback. Observe how experienced reviewers provide suggestions and explanations. Seek feedback on your own code to enhance your skills and understanding.
11. Practice and seek feedback: The more you engage in code reviews, the better you’ll become. Practice regularly and seek feedback from both developers and reviewers to improve your code review skills.
12. Learn from resources and training: Explore online resources, articles, books, and courses on code review best practices. Some organizations also offer internal training or mentorship programs to enhance code review skills. Take advantage of these resources to deepen your knowledge.
By following these steps and continuously learning and practicing from the experience, you can become an effective code reviewer.
Practice makes a man perfect.How to convey messages politely in code reviews?
 Code Quality 3 (credits: xkcd comics)
Code Quality 3 (credits: xkcd comics)When conveying messages politely in code reviews, it’s important to consider the following guidelines:
1. Use a friendly and constructive tone: Frame your feedback in a positive and encouraging manner. Instead of simply pointing out flaws, offer suggestions for improvement.
2. Start with positive feedback: Begin by acknowledging the strengths or good aspects of the code. This helps create a positive atmosphere and shows appreciation for the developer’s efforts.
3. Be specific and objective: Clearly articulate the issues you’ve identified or the improvements you suggest. Use specific examples from the code to illustrate your points. Avoid vague or general statements.
4. Focus on the code, not the developer: Critique the code itself rather than to criticize the developer personally. Remember that the goal is to improve the code, not to attack the individual who wrote it.
5. Offer alternatives or solutions: Instead of simply pointing out problems, provide alternative approaches or solutions. This demonstrates your willingness to help and encourages collaboration.
6. Use constructive language: Frame your feedback in a way that promotes learning and growth. Use phrases like “Have you considered…” or “What if we tried…” to encourage dialogue and exploration of different options.
7. Be respectful and empathetic: Keep in mind that behind every line of code is a developer who invested time and effort. Show empathy and respect for their work while providing suggestions for improvement.
8. Provide context and explanations: When suggesting changes or improvements, explain the reasoning behind your suggestions. Help the developer understand why a certain approach may be more beneficial.
9. Focus on the bigger picture: Consider the overall goals of the project and the team. Align your feedback with those goals and emphasize how the suggested changes contribute to the project’s success.
10. Follow up with support: Offer assistance and clarification if the developer has questions or needs further guidance. Engage in a constructive dialogue to ensure that the feedback is well understood.
By conveying messages politely and constructively, you create a positive and collaborative environment for growth and development.
There is a very thin line between hand-holding and spoon-feeding. Spoon feed an infant, but hand hold an adult.Epilogue
So, to be an effective software engineer, it is necessary to be an effective code reviewer and also, get your code reviewed. In quality control, Four competent eyes are always better than two. After all, software engineering is a collaborative and creative learning process, not a siloed labor.
Being a great engineer is all about having the right attitude.[image error]
The Right Approach to Effective Code Reviews was originally published in Technopreneurial Treatises on Medium, where people are continuing the conversation by highlighting and responding to this story.
May 21, 2023
Picking the Event Store for Event Sourcing
 Prologue
Prologue Building event-driven architecture
Building event-driven architectureSo, you have decided to go the event-driven route of building your enterprise application using the event-sourcing paradigm after reading my old article — Architecting Event-driven Systems the right way but for deciding on the core of your application — the datastore, you start contemplating which will be the right datastore for your architecture based on your requirements. You revisit the possible database choices, relook at the business requirements, and then, comes the problem:
ProblemThere are multiple requirements for Event Store and thus, different database strategies for using event sourcing for such requirements. How can you ahead and choose the right database based on the event-sourcing requirement?
Before we dive deep into the requirements, let’s go through the basic terms used in event sourcing.
ConceptsState — A state is a description of the status of a system waiting to execute a transition.
Transition — A transition is a change from one state to another. A transition is a set of actions to execute when a condition is fulfilled or an event is received.
Domain Event — The entity that drives the state changes in the business process.
Aggregates — Cluster of domain objects that can be treated as a single unit, modeling a number of rules (or invariants) that always should hold in the system. Can also, be called “Event Provider” as “Aggregate” is really a domain concept and an Event Storage could work without a domain.
Aggregate Root — Aggregate Root is the mothership entity inside the aggregate controlling and encapsulating access to its members in such a way as to protect its invariants.
Invariant — An invariant describes something that must be true within the design at all times, except during a transition to a new state. Invariants help us to discover our Bounded Context.
Bounded Context — A Bounded Context is a system boundary designed to solve a particular domain problem. The bounded context groups together a model that may have 1 or many objects, which will have invariants within and between them.
Requirements1. Sequential Durable Write — Be able to store state changes as a sequence of events, chronologically ordered.
2. Domain Aggregate Read — Be able to read events of individual aggregates, in the order they persisted.
3. Sequential Read — Be able to read all events, in the order they were persisted.
4. Atomic Writes — Be able to write a set of events in one transaction, either all events are written to the event store or none of them are.
Comparison of DatastoresLet’s walk through different database types and dive deep into how they will support the above requirements.
Relational Database
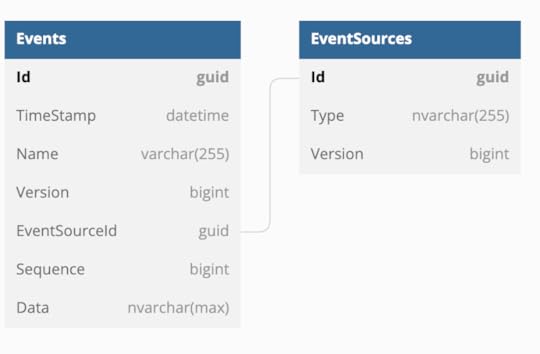 Event Store Implementation in Relational Database
Event Store Implementation in Relational DatabaseIn a relational database, event sourcing can be implemented with only two tables, one to store the actual Event Log, storing one entry per event in this table and the other to store the Event Sources. The event itself is stored in the [Data] column. The event is stored using some form of serialization, for the rest of this discussion the mechanism will be assumed to be built-in serialization although the use of the memento pattern can be highly advantageous.
A version number is also stored with each event in the Events Table as an auto-incrementing integer. Each event that is saved has an incremented version number. The version number is unique and sequential only within the context of a given Event Source (aggregate). This is because Aggregate Root boundaries are consistency boundaries. On the other hand, Sequence, the other auto-incrementing integer is also, unique and sequential and stores the global sequence of events based on TimeStamp.
The [EventSourceId] column is a foreign key that should be indexed; it points to the next table which is the Event Sources table.
The Event Sources table is representing the event source provider (aggregates) currently in the system, every aggregate must have an entry in this table. Along with the identifier, there is a denormalization of the current version number. This is primarily an optimization as it could be derived from the Events table but it is much faster to query the denormalization than it would be to query the Events table directly. This value is also used in the optimistic concurrency check. Also included is a [Type] column in the table, which would be the fully qualified name of the type of event source provider being stored.
To look up all events for an event source provider, the query will be:
SELECT Id, TimeStamp, Name, Version, EventSourceId, Sequence, Data FROM EventsWHERE EventSourceId = :EventSourceId ORDER BY Version ASC;
To insert a new event for a given event source provider, the query will be:
BEGIN;currentVersion := SELECT MAX(version) FROM Events
WHERE EventSourceId = :EventSourceId;
currentSequence := SELECT MAX(Sequence) FROM Events;
INSERT INTO Events(TimeStamp, Name, Version, EventSourceId, Sequence, Data)
VALUES (NOW(),:Name, :currentVersion+1, :EventSourceId, :currentSequence+1, :Data);
UPDATE EventSources SET Version = currentVersion+1 WHERE EventSourceId = :EventSourceId;
COMMIT;
Key-Value Store
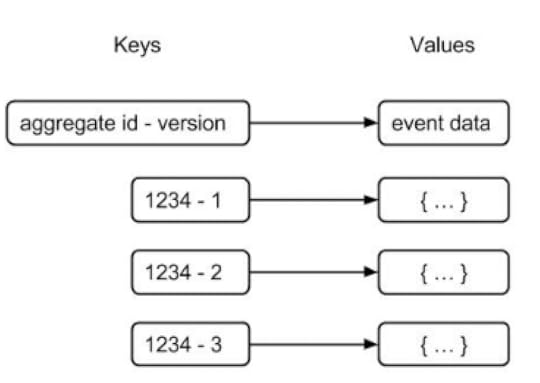 Event Store Implementation in Key-Value Store
Event Store Implementation in Key-Value StoreIn a key-value store, an event can be modeled by constructing the key as a combination of the aggregate id and the version number. The serialized event data can be stored as the corresponding value. This method of constructing the key enables the chronological storage of events for a specific aggregate. To access data from the key-value store, knowledge of the key is required. It might be feasible to retrieve events for a particular aggregate by knowing only its aggregate id and incrementing the version number until a key is not found. However, a challenge arises when attempting to retrieve events for any aggregate, as no portion of the key is known. Consequently, it becomes impossible to retrieve these events in the order they were stored. Additionally, it’s important to note that many key-value stores lack transactional capabilities.
Document Database
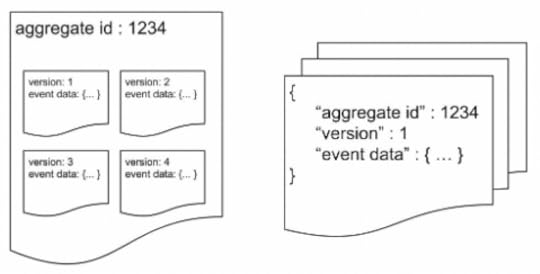 Event Store Implementation in Document Database
Event Store Implementation in Document DatabaseUsing a document database allows for the storage of all events associated with an aggregate within a single document, or alternatively, each event can be stored as an individual document. To maintain chronological order, a version field can be included in the document to store the events. When all events pertaining to an aggregate are stored in the same document, a query can be executed to retrieve them in the order of their version numbers. As a result, the returned events will maintain the same order as they were stored.
However, if multiple events from different aggregates are stored within a single document, it becomes challenging to retrieve them in the correct sequence. One possible approach is to retrieve all events and subsequently sort them based on a timestamp, but this method would be inefficient. Thankfully, most document databases support ACID transactions within a document, enabling the writing of a set of events within a single transaction.
Column Oriented Database
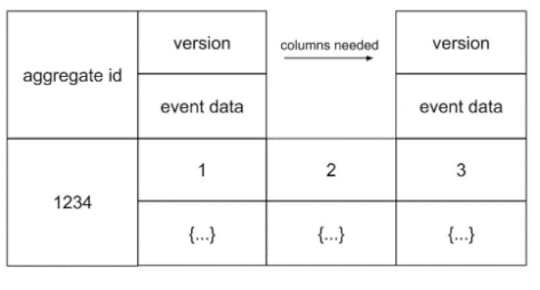 Event Store Implementation in Column-oriented Database
Event Store Implementation in Column-oriented DatabaseIn a column-oriented database, events can be stored as columns, with each row containing all events associated with an aggregate. The aggregate id serves as the row key, while the events are stored within the columns. Each column represents a key-value pair, where the key denotes the version number and the value contains the event data. Adding a new event is as simple as adding a new column, as the number of columns can vary for each row.
To retrieve events for a specific aggregate, the row key (aggregate id) must be known. By ordering the columns based on their keys, the events can be collected in the correct order. Writing a set of events in a row for an aggregate involves storing each event in a new column. Many column-oriented databases support transactions within a row, enabling the writing process to be performed within a single transaction.
However, similar to document databases, column-oriented databases face a challenge when attempting to retrieve all events in the order they were stored. There is no straightforward method available for achieving this outcome.
Comparison of Specific Datastore ImplementationsPostgres
While Postgres is commonly known as a relational database management system, it offers features and capabilities that make it suitable for storing events in an Event Sourcing architecture.
Postgres provides a flexible data model that allows you to design a schema to store events efficiently. In Event Sourcing, you typically need an Events table that includes fields such as a global sequence number, aggregate identifier, version number per aggregate, and the payload data (event) itself. By designing the schema accordingly, you can easily write queries that efficiently perform full sequential reads or search for all events related to a specific event source (aggregate) ID.
Postgres also offers transactional support, ensuring ACID (Atomicity, Consistency, Isolation, Durability) guarantees. This means that events can be written and read in a transactional manner, providing data integrity and consistency.
The append-only policy, a fundamental aspect of Event Sourcing, can be enforced in Postgres by avoiding UPDATE or DELETE statements on event records. This way, events are stored chronologically as new rows are inserted into the table.
Additionally, Postgres is a mature technology with wide adoption and a strong ecosystem of tools and libraries. It provides a range of performance optimization techniques, indexing options, and query optimization capabilities, enabling efficient retrieval and processing of events.
While Postgres may not offer some of the specialized features specific to event-sourcing databases, with careful design and optimization, it can serve as a reliable and scalable event store for Event Sourcing architectures.
Cassandra
Cassandra can be used as an event store for Event Sourcing, but there are some considerations to keep in mind.
Cassandra is a highly scalable and distributed NoSQL database that offers features such as peer-to-peer connections and flexible consistency options. It excels in handling large amounts of data and providing high availability.
However, when it comes to guaranteeing strict sequencing or ordering of events, Cassandra may not be the most efficient choice. Cassandra’s data model is based on a distributed and partitioned architecture, which makes it challenging to achieve strong sequencing guarantees across all nodes in the cluster. Ensuring strict ordering typically requires leveraging Cassandra’s lightweight transaction feature, which can impact performance and should be used judiciously as per the documentation’s recommendations.
In an Event Sourcing scenario where appending events is a common operation, relying on lightweight transactions for sequencing events in Cassandra may not be ideal due to the potential performance cost.
While Cassandra may not provide native support for strong event sequencing guarantees, it can still be used effectively as an event store by leveraging other mechanisms. For example, you can include a timestamp or version number within the event data to order events chronologically during retrieval.
Additionally, Cassandra’s scalability and fault-tolerance features make it suitable for handling large volumes of events and ensuring high availability for event-driven architectures.
MongoDB
MongoDB, a widely used NoSQL document database, offers high scalability through sharding and schema-less storage. It allows easy storage of events due to its schema-less nature.
MongoDB’s flexibility and schema-less nature allow for easy storage of event data. You can save events as documents in MongoDB, with each document representing an individual event. This makes it straightforward to store events and their associated data without the need for predefined schemas.
To ensure the ordering and sequencing of events, you can include a timestamp or version number within each event document. This enables you to retrieve events in the order they were stored, either by sorting on the timestamp or using the version number.
MongoDB also provides high scalability through sharding, allowing you to distribute your event data across multiple servers to handle large volumes of events.
However, there are certain considerations when using MongoDB as an event store. MongoDB traditionally supported only single-document transactions, which could limit the atomicity and consistency of operations involving multiple events. However, MongoDB has introduced support for multi-document transactions, which can help address this limitation.
Another challenge with MongoDB as an event store is the lack of a built-in global sequence number. To achieve a full sequential read of all events, you would need to implement custom logic to maintain the sequence order.
Additionally, MongoDB’s ad hoc query capabilities and scalability make it a strong choice for event storage. However, transactional support and event-pushing performance may require careful consideration and optimization.
Kafka
Kafka is often mentioned in the context of Event Sourcing due to its association with the keyword “events.” Using Kafka as an event store for Event Sourcing is a topic of debate and depends on specific requirements and trade-offs. Kafka’s design as a distributed streaming platform makes it a popular choice for building event-driven systems, but there are considerations to keep in mind.
Kafka’s core concept revolves around the log-based storage of events in topics, providing high throughput, fault tolerance, and scalable message processing. It maintains an immutable, ordered log of events, which aligns well with the append-only nature of event sourcing.
However, using Kafka as an event store for Event Sourcing introduces some challenges. One key consideration is the trade-off between storing events for individual aggregates in a single topic or creating separate topics for each aggregate. Storing all events in a single topic allows full sequential reads of all events but makes it more challenging to efficiently retrieve events for a specific aggregate. On the other hand, storing events in separate topics per aggregate can optimize retrieval for individual aggregates but may pose scaling challenges due to the design of topics in Kafka.
To address this, various strategies can be employed. For example, you can create a topic per aggregate and use partitioning to distribute the events across partitions. However, ensuring an even distribution of entities across partitions and handling the restoration of global event order can introduce additional complexities.
Another consideration is access control and security. When using Kafka as an event store, it’s important to manage access to the Kafka instance to ensure data privacy and integrity since anyone with access can read the stored topics.
Furthermore, it’s worth noting that using Kafka as an event store deviates from the traditional Event Sourcing principle of storing events before publishing them. With Kafka, storing and publishing events are not separate steps, which means that if a Kafka instance fails during the process, events may be lost without knowledge.
EventStore
“EventStore” is a purpose-built database that aligns well with the principles and requirements of Event Sourcing. It is a popular option written in .NET and is well-integrated within the .NET ecosystem.
Event Store, as the name suggests, focuses on efficiently storing and managing events. It offers features and capabilities that are well-suited for event-driven architectures and Event Sourcing implementations.
One key feature of Event Store is its ability to handle projections or event-handling logic within the database itself. This allows for efficient querying and processing of events, enabling developers to work with events in a flexible and scalable manner.
Event Store provides the necessary mechanisms to store events in an append-only fashion, ensuring that events are immutable and ordered. It allows you to store events for different aggregates or entities in a single stream, making it easy to retrieve events for a specific aggregate in the order they were stored.
Additionally, Event Store offers strong transactional support, allowing for ACID (Atomicity, Consistency, Isolation, Durability) guarantees when working with events. This ensures that events are persisted reliably and consistently, maintaining data integrity.
Event Store also provides features for event versioning, enabling compatibility and evolution of event schemas over time. This is important for maintaining backward compatibility and handling changes to event structures as the application evolves.
Furthermore, Event Store typically offers built-in features for event publishing and event subscription mechanisms, facilitating event-driven communication and integration within an application or across microservices.
However, a key feature of “EventStore” is that projection (or event handling) logic is placed and executed within the Event Store itself using Javascript. While this is a tempting proposition, it diverges from our view that the Event Store should store events, and that projection logic should be handled by the consumers themselves. This allows us a greater degree of flexibility over how to handle our events and not being limited to the functionality of Javascript logic available in the “EventStore” database.
Redis Streams
Redis Streams differs from traditional Redis Pub/Sub and functions more like an append-only log file. It shares conceptual similarities with Apache Kafka.
Redis Streams allow you to append new events to a stream, ensuring that they are ordered and stored sequentially. Each event in the stream is associated with a unique ID, providing a way to retrieve events based on their order of arrival. Additionally, Redis Streams support multiple consumers, enabling different components or services to consume events from the same stream.
When using Redis Streams as an event store, you can store event data along with any necessary metadata. This allows you to capture the essential details of an event, such as the event type, timestamp, and data payload. By leveraging the features provided by Redis Streams, you can efficiently publish, consume, and process events in a scalable manner.
It’s important to note that while Redis Streams offer a convenient and performant solution for event storage, there are considerations to keep in mind. For example, ensuring data durability and persistence may require additional configuration and replication mechanisms. Additionally, access control and security measures should be implemented to safeguard the event data stored in Redis Streams.
Epilogue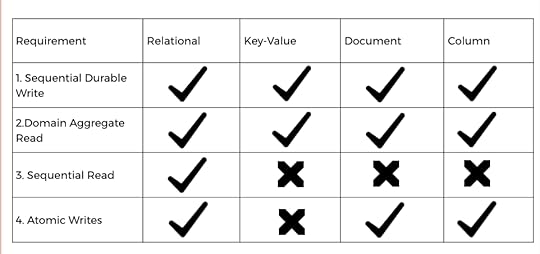 Comparison of Datastores across Event Store Requirements
Comparison of Datastores across Event Store RequirementsIn conclusion, each data store has its strengths and limitations for Event Sourcing. It is essential to consider factors such as scalability, consistency, sequencing, transactionality, and query support when selecting a suitable data store for an event-sourced system.
There Ain’t No Such Thing As A Free Lunch.[image error]
Picking the Event Store for Event Sourcing was originally published in Technopreneurial Treatises on Medium, where people are continuing the conversation by highlighting and responding to this story.
August 20, 2022
Standardizing RESTful APIs
Consistent, hierarchical, and modular APIs
 Prologue
Prologue
So, you have decided to build your enterprise application as loosely coupled micro-services, even thinking of making them serverless after reading my old article — Serverless Microservices and after coming across REST API, you have decided to build your application APIs conforming to REST architectural style. Good Job! Basically, you have adopted the microservices architecture, where each piece of your application performs a smaller set of services and runs independently of the other part of the application and operates in its own environment and stores its own data and communicates/interacts with other services via REST API. But, then you have multiple REST APIs in your services to take care of and provide to the customers, especially if you are opening your services to third-parties. So here comes the problem:
The ProblemWhen you let your micro-service teams to adopt to REST, they all come up with their own standards and conventions of doing things. Eventually, there is pandemonium, when clients and customers are not able to follow the REST APIs, designed for your enterprise services as each API is designed in its own unique style. When you, as an architect or team lead go ahead to discuss this problem with your micro-services development team, you get the following response.

Also, as your team adds more REST services and glue them together, you start worrying more about their standardisation and presentation as you never had put any convention in place. Now, you try to realize the problem of standardizing your RESTful APIs and wished for better and sane practices from the start. After all, migrating all your clients and customers on the new standard version of APIs won’t be an easy task.
The DefinitionsYou look at the REST API specification from the first principles and start by understanding what all its underlying syntax is customisable and can be standardized.
API — An API is a set of definitions and protocols for building and integrating application software, referred to as a contract between an information provider and an information user — establishing the content required from the consumer (the call) and the content required by the producer (the response).
The advantage of using APIs is that as a resource consumer, you are decoupled from the producer and you don’t have to worry about how the resource is retrieved or where it comes from. It also helps an organization to share resources and information while maintaining security, control, and authentication — determining who gets access to what.
REST — REST stands for REpresentational State Transfer and was created by computer scientist Roy Fielding. REST is a set of architectural constraints, not a protocol or a standard. When a client request is made via a RESTful API, it transfers a representation of the state of the resource to the requester or endpoint in one of several formats via HTTP: JSON, HTML, XML, plain text etc.
In order for an API to be considered RESTful, it has to conform to these criteria:
A client-server architecture made up of clients, servers, and resources, with requests managed through HTTP. Stateless client-server communication, meaning no client information is stored between get requests and each request is separate and unconnected. Cacheable data that streamlines client-server interactions.A uniform interface between components so that information is transferred in a standard form. This requires that:resources requested are identifiable and separate from the representations sent to the client.resources can be manipulated by the client via the representation they receive because the representation contains enough information to do so.self-descriptive messages returned to the client have enough information to describe how the client should process it.hypertext/hypermedia is available, meaning that after accessing a resource the client should be able to use hyperlinks to find all other currently available actions they can take.5. A layered system that organizes each type of server (those responsible for security, load-balancing, etc.) involved the retrieval of requested information into hierarchies, invisible to the client.
6. Code-on-demand (optional): the ability to send executable code from the server to the client when requested, extending client functionality.
API developers can implement REST in a variety of ways, which sometimes leads to chaos, especially when the syntactic schema for REST across multiple API development teams are not aligned and standardised. So, in next sections, the evaluation criteria for evaluating and suggestions to standardize REST APIs is presented to evade this chaos.
REST API Evaluation CriteriaThe REST APIs should be holistically evaluated and improved based on the following criteria:
Resource Oriented DesignStandard MethodsCustom MethodsStandard Fields and Query ParametersSuccess & ErrorsNaming ConventionsImportant PatternsResource Oriented DesignThe API should define a hierarchy, where each node is either a collection or a resource.
● A collection contains a list of resources of the same type. For example, a device type has a collection of devices.
● A resource has some state and zero or more sub-resources. Each sub-resource can be either a simple resource or a collection. For example, a device resource has a singleton resource state (say, on or off) as well as a collection of changes (change log).
A specific use case, the singleton resource can be used when only a single instance of a resource exists within its parent resource (or within the API, if it has no parent).
Here is a suggestion for simple and consistent API hierarchy:
Collection : device-types Resource: device-types/{dt-id} Singleton Resource: device-types/{dt-id}/state-machineCollection: device-types/{dt-id}/attributes Resource: device-types/{dt-id}/attributes/{attribute-id}
Collection: device-types/{dt-id}/changes Resource: device-types/{dt-id}/changes/{change-id}
Collection: device-types/{dt-id}/devices Resource: device-types/{dt-id}/devices/{d-id} Singleton Resource: device-types/{dt-id}/devices/{d-id}/state Custom Method: device-types/{dt-id}/devices/{d-id}/state:transition
Collection: device-types/{dt-id}/devices/{d-id}/changes Resource: device-types/{dt-id}/devices/{d-id}/changes/{change-id}s
Note that in the above, id can be string for name, number or even UUID based on agreed convention. Example:
https://tenant.staging.saas.com/api/v1/device-types/house-alarm/devices/cbb96ec2-edae-47c4-87e9-86eb8b9c5ce4sStandard MethodsThe API should support standard methods for LCRUD (List, Create, Read, Update and delete) on the nodes in the API hierarchy.
The common HTTP methods used by most RESTful web APIs are:
GET retrieves a representation of the resource at the specified URI. The body of the response message contains the details of the requested resource. POST creates a new resource at the specified URI. The body of the request message provides the details of the new resource. Note that POST can also be used to trigger operations that don’t actually create resources. PUT either creates or replaces the resource at the specified URI. The body of the request message specifies the resource to be created or updated. PATCH performs a partial update of a resource. The request body specifies the set of changes to apply to the resource. DELETE removes the resource at the specified URI.The following table describes how to map standard methods to HTTP methods:
1. Standard Method : List
HTTP Mapping: GET
HTTP Request Body: NA
HTTP Response Body: Resource* list
2. Standard Method : Read
HTTP Mapping: GET
HTTP Request Body: NA
HTTP Response Body: Resource*
3. Standard Method : Create
HTTP Mapping: POST
HTTP Request Body: Resource
HTTP Response Body: Resource*
4. Standard Method : Update
HTTP Mapping: PUT or PATCH
HTTP Request Body: Resource
HTTP Response Body: Resource*
5. Standard Method : Delete
HTTP Mapping: DELETE
HTTP Request Body: NA
HTTP Response Body: NA
Based on the requirements, some or all of the above API methods for the node hierarchy should be supported. Note that the * marked resource data will be encapsulated inside the response body format containing status, request and data.
Here are the differences between POST, PUT, and PATCH for their usage in REST:
A POST request creates a resource. The server assigns a URI for the new resource, and returns that URI to the client. In the REST model, POST request is generally applied to collections and the new resource is added to the collection. A POST request can also be used to submit data for processing to an existing resource as a custom method, without any new resource being created.A PUT request creates a resource or updates an existing resource. The client specifies the URI for the resource to be created or updated with the complete representation of the resource. If a resource with this URI already exists, it is replaced, else a new resource is created, if the server supports doing so. Whether to support creation via PUT depends on whether the client can meaningfully assign a URI to a resource before it exists. If not, then use POST to create resources and PUT or PATCH to update.A PATCH request performs a partial update to an existing resource. The client specifies the URI for the resource with the set of changes to apply to the resource. This can be more efficient than using PUT, because the client only sends the changes, not the entire representation of the resource. Technically, PATCH can also create a new resource (by specifying a set of updates to a “null” resource), if the server supports this but again, that is an anti-pattern.PUT requests must be idempotent but POST and PATCH requests are not guaranteed to be idempotent. If a client submits the same PUT request multiple times, the results should always be the same (the same resource will be modified with the same set of values).
Custom MethodsCustom methods refer to API methods besides the above 5 standard methods for functionality that cannot be easily expressed via standard methods. One of the custom functionality is the state transition of devices based on API requests. The corresponding API can be modelled either of the following ways:
1. Based on Stripe invoice workflow design: Use / to separate the custom verb. Note that this might confuse it with resource noun.
https://tenant.staging.saas.com/api/v1/device-types/house-alarm/devices/cbb96ec2-edae-47c4-87e9-86eb8b9c5ce4s/state/ring2. Based on Google Cloud API design: Use : instead of / to separate the custom verb from the resource name so as to support arbitrary paths.
https://tenant.staging.saas.com/api/v1/device-types/house-alarm/devices/cbb96ec2-edae-47c4-87e9-86eb8b9c5ce4s/state:ringIn either of the above ways, the API should use HTTP POST verb since it has the most flexible semantics.
Standard Fields and Query ParametersResources may have the following standard fields:
idcreatedAtcreatedByupdatedAtupdatedBynamedisplayNametimeZoneregionCodelanguageCodeNote that displayName, timeZone, regionCode, languageCode etc are useful, when you want to provide localizations in your API.
Collections may have also have standard fields like totalCount in metadata.
Collections List API may have the following standard query parameters (with alternate names):
filter/queryorderByselect/fields/viewlimit/top/pageSizeoffset/startformat (json, xml)validateThe standard query parameters can be separated from custom query parameters by preceding them with $. Example:
https://tenant.staging.saas.com/api/v1/device-types/house-alarm/devices?$orderBy=volume&owner=jaykmr&$format=jsonSuccess & ErrorsSuccess & Errors across all the methods should be consistent, i.e. have same standard structure, for example:
{"status":{ "code":"", "description":"", "additionalInfo":"" }, "request":{ "id":"", "uri":"", "queryString":"", "body":"" }, "data":{ "meta":{ "totalCount":"", ... }, "values":{ "id":"", "url":"", ... } }}
All the API should have a common response structure and this can be achieved by using a common response formatter in the code for resource methods. Note, in case of success, when no data is returned, the API response can either return empty list [] for collection or empty object {} for resource, while in case of error, can just return data as null to keep a consistent response schema across methods.
Naming Conventions
Here are my suggestions on the naming conventions without the intention of provoking tabs vs spaces kind of debate:
● Collection and Resource names should use unabbreviated plural form and kebab case.
● Field names and query parameters should use lowerCamel case.
● Enums should use Pascal case names.
● Custom Methods should use lowerCamel case names. (example: batchGet)
There are multiple good suggestions like Google API Naming Convention but this depends on the organization, however whatever the organization chooses and adopts, they should be aligned across all the teams and strictly adhered to.
Important PatternsList Pagination: All List methods over collections should support pagination using the standard fields, even if the response result set is small.
The API pagination can be supported in 2 ways:
Limit Offset Pagination using (offset, limit)Cursor Pagination using (limit, cursor_next_link)The cursor next link makes the API really RESTful as the client can page through the collection simply by following these links (HATEOAS). No need to construct URLs manually on the client side. Moreover, the URL structure can simply be changed without breaking clients (evolvability).
Delete Response: Return Empty data response {} in hard delete while updated resource data response in soft delete. Return Null in failures and errors.
Enumeration and default value: 0 should be the start and default for enums like state singletons and their handling should be well documented.
Singleton resources: For example, the state machine of the resource (say, device type) as well as the state of the resource (say, device) should never support the Create and Delete method as the states (ON, OFF, RING etc) can be configured i.e. Updated but not Created or Deleted.
Request tracing and duplication: All requests should have a unique requestID, like a UUID, which the server will use to detect duplication and make sure the non-idempotent request like POST is only processed once. Also, requestID will help in distributed tracing and caching. The unique requestID should also be part of the response request section.
Request Validation: Methods with side-effects like Create, Update and Delete can have a standard boolean query parameter validate, which when set to true does not execute the request but only validates it. If valid, it returns the correct status code but current unchanged resource data response, else it returns the error status code.
https://tenant.staging.saas.com/api/v1/device-types/house-alarm/devices/cbb96ec2-edae-47c4-87e9-86eb8b9c5ce4s/state:ring?$validate=trueFor example, the above request will validate whether alarm can be put to ring or not.
HATEOAS (Hypertext as the Engine of Application State): Provide links for navigating through the API (especially, the resource url). For example,
{"orderID":3,
"productID":2,
"quantity":4,
"orderValue":16.60,
"links":[
{
"rel":"customer",
"href":"https://adventure-works.com/customers/3",
"action":"GET",
"format":["text/xml","application/json"]
},
{
"rel":"customer",
"href":"https://adventure-works.com/customers/3",
"action":"PUT",
"format":["application/x-www-form-urlencoded"]
},
{
"rel":"self",
"href":"https://adventure-works.com/orders/3",
"action":"GET",
"format":["text/xml","application/json"]
},
{
"rel":"self",
"href":"https://adventure-works.com/orders/3",
"action":"PUT",
"format":["application/x-www-form-urlencoded"]
},
{
"rel":"self",
"href":"https://adventure-works.com/orders/3",
"action":"DELETE",
"format":[]
}]
}
Versioning: Versioning enables the client or the consumer to keep track of the changes, be it compatible or even, incompatible breaking changes so that it can make specific version call for consumption, which it can process.
The versioning can be supported in 3 ways:
URI versioning:https://tenant.staging.saas.com/api/v1/device-types/Query string versioning:https://tenant.staging.saas.com/api/device-types?$version=v1Header versioning:GET https://tenant.staging.saas.com/api/device-typesCustom-Header: api-version=v1Epilogue
So, you have divided the monolithic applications into microservices, all integrated by loose coupling into separate micro-applications. Now is the time to revisit your APIs, make them standardized and raise the bar of your APIs before making it external for customers. The APIs should be consistent, hierarchical and modular. The separation of methods, standard fields and patterns from the collection & resource hierarchy will allow you to build resource agnostic re-usable abstractions, which can be implemented by the resource interfaces and deployed as services.
You should even, break the frontend into micro-frontends and serve them separately to make it a complete micro-application. Refer to my previous article — Demystifying micro-frontends for such micro-services-based backend to make a complete micro-application-based architecture.
Solve the problem once, use the solution everywhere!ReferenceGoogle API Design GuideDjango Rest Framework API GuideOData 4.0 DocumentationREST API Design Best PracticesMicrosoft API Design Guide[image error]
Standardizing RESTful APIs was originally published in Technopreneurial Treatises on Medium, where people are continuing the conversation by highlighting and responding to this story.

