
Timothy Gowers's Blog
March 20, 2026
Group and semigroup puzzles and a possible Polymath project
An Artin-Tits group is a group with a finite set of generators 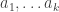 in which every relation is of the form
in which every relation is of the form 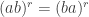 or
or 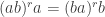 for some positive integer
for some positive integer  , where
, where  and
and 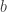 are two of the generators. In particular, the commutation relation
are two of the generators. In particular, the commutation relation 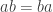 is allowed (it is the case
is allowed (it is the case 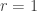 of the first type of relation) and so is the braid relation
of the first type of relation) and so is the braid relation 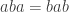 (it is the case of the second type of relation). This means that Artin-Tits groups include free groups, free Abelian groups, and braid groups: for example, the braid group on
(it is the case of the second type of relation). This means that Artin-Tits groups include free groups, free Abelian groups, and braid groups: for example, the braid group on 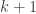 strands has a presentation with generators
strands has a presentation with generators 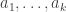 , where
, where 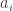 represents a twist of the
represents a twist of the  th and
th and 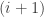 st strands, and relations
st strands, and relations 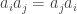 if
if 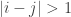 and
and 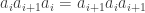 .
.
A few weeks ago, I asked ChatGPT for a simple example of a word problem for groups or semigroups that was not known to be decidable and also not known to be undecidable. It turns out that the word problem for many Artin-Tits groups comes into that category: the simplest example where the status is not known is the group with four generators 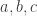 and
and 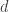 where
where  and commute and all other pairs of generators satisfy the braid relation
and commute and all other pairs of generators satisfy the braid relation 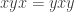 .
.
My interest in this was initially that I was looking for a toy model from which one could learn something about how mathematicians judge theorems to be interesting. I started with a remarkable semigroup discovered by G. S. Tseytin that has five generators, seven very simple relations, and an undecidable word problem. From that I created a puzzle game that you might be interested to play. Each puzzle is equivalent to an instance of the word problem for Tseytin’s semigroup, but the interface makes it much more convenient to change words using the relations than it would be to do it with pen and paper.
I was hoping that because every mathematical problem can in principle be encoded as a puzzle in this game, one might be able to build a sort of “alien mathematics”, where a theorem was an equality between words, and a definition was a decision to introduce a new (and redundant) generator g, together with a relation of the form g = w, where w is a word in the current alphabet. Theorems would be particularly interesting if they were equalities between words that could be established only by a chain of equalities that went through much longer words, and definitions would be useful if the new generators satisfied particularly concise relations (which would allow one to build “theories” within the system). I still hope to find a word problem that will allow such a project to take off, but in the end, after a lot of playing around with the game linked to above, I have decided that Tseytin’s semigroup is not suitable. The reason is that it is designed so that arbitrary instances of the word problem for groups can be encoded as word problems in this semigroup, and once one gets used to the game, one starts to see how that encoding can work. Furthermore, one seems to be driven towards the encoding — I don’t get the impression that there’s a whole other region of this semigroup to explore that has nothing to do with the kinds of words that come up in the encoding. And if that impression is correct, then one might as well start with the word problem for some group in unencoded form, or alternatively look for another semigroup. Nevertheless, I find the Tseytin game quite enjoyable: I won’t say more about it here but have written a fairly comprehensive tutorial that you can open up and read if you follow the link above.
This is perhaps the moment to say that the words “I created a puzzle game” are slightly misleading. For one thing, I discussed the idea of gamifying Tseytin’s semigroup about three years ago with Mirek Olšák, a former member of my automatic theorem proving group, and he created a basic prototype in Python. But the main point is that I do not have the programming skills to create a game that can be played in a web browser — I vibecoded it using ChatGPT.
After that experience, I thought that maybe I would have better luck if instead of looking for a group or semigroup with undecidable word problem, which might well have been explicitly designed with some encoding in mind, I looked for a word problem for which the decidability status was unknown. That way, it wouldn’t have been designed to be undecidable, but might nevertheless just happen to be undecidable and provide a nice playground of the kind I was (and still am) after. And that is what led me to the Artin-Tits groups.
However, those don’t seem to be suitable either, because it is conjectured that they all have decidable word problems. I have created a game for the Artin-Tits group mentioned above, which you can also play if you want, but I have found it very hard to create interesting puzzles. That is, I found it difficult to find words that are equivalent to the identity but that are not easily shown to be equivalent to the identity. (One nice example comes from the fact that the subgroup generated by 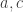 and is isomorphic to the braid group
and is isomorphic to the braid group 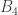 with four strands. The late Patrick Dehornoy found a very nice example of a braid with four strands that is equal to the identity but not in a completely trivial way. A picture of it can be found on the first page of this paper.)
with four strands. The late Patrick Dehornoy found a very nice example of a braid with four strands that is equal to the identity but not in a completely trivial way. A picture of it can be found on the first page of this paper.)
This is where a potential Polymath project comes in. An initial goal would be to determine the decidability status of this one small Artin-Tits group: if we managed that, then we could consider the more general problem. And the way I envisage approaching this initial goal is an iterative process that runs as follows.
Devise an algorithm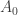 for solving word problems in the group.If the current algorithm is
for solving word problems in the group.If the current algorithm is 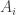 , then search for a puzzle
, then search for a puzzle 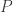 that fails to solve.If the search is successful, then devise an algorithm
that fails to solve.If the search is successful, then devise an algorithm 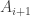 that solves all the puzzles that solves, and also solves . Make the current algorithm and return to step 2. Devising can be done by playing the game with puzzle several times until one has the feeling that one has solved it in a systematic way.If the search is unsuccessful and the current algorithm is
that solves all the puzzles that solves, and also solves . Make the current algorithm and return to step 2. Devising can be done by playing the game with puzzle several times until one has the feeling that one has solved it in a systematic way.If the search is unsuccessful and the current algorithm is 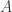 , then attempt to prove inductively that always succeeds: that is, to prove that if solves and
, then attempt to prove inductively that always succeeds: that is, to prove that if solves and 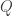 is obtained from by applying a single relation in the group, then solves . (Maybe) If the inductive step doesn’t seem to work, then try to use that failure to devise a puzzle that defeats and return to step 3.
is obtained from by applying a single relation in the group, then solves . (Maybe) If the inductive step doesn’t seem to work, then try to use that failure to devise a puzzle that defeats and return to step 3.I have done a couple of iterations already, with the result that I now have an algorithm — let’s call it — that solves (basically instantaneously) every puzzle I throw at it, including the one derived from Dehornoy’s braid mentioned above. So a subgoal of the initial goal is to find a puzzle that has a solution but that doesn’t solve. If we can’t, then maybe it is worth trying to prove that solves the word problem for this group. One comment about the algorithm is that it never increases the length of a word, though it often does moves that preserve the length. I was told by ChatGPT that it is an unsolved problem whether every braid that is equal to the identity can be reduced to the identity without ever increasing the number of crossings. Of course that isn’t a guarantee that it really is unsolved, but if it is, then that’s another interesting problem. It also means that I would be extremely interested if someone found an example of a word in the Artin-Tits group that can be reduced to the identity but only if one starts by lengthening it.
I’m hoping that this will be an enjoyable project for people who like both mathematics and programming. On the maths side, there is an unsolved problem to think about, and on the programming side there are lots of possibilities: for example, one could write programs that explore the space of words equal to the identity, trying to do so in such a way that there is a reasonable chance of reaching a word where it isn’t obvious how to reverse all the steps and get back to the identity. The game comes with a “sandbox” that has a few tools for generating words, but at the moment it is fairly primitive, and I would welcome suggestions for how to improve it.
It seems to me that as Polymath projects go, one can’t really lose: either we find an algorithm for the word problem, which establishes an unknown (at least according to ChatGPT) case of a decidability problem, or we find a suite of harder and harder puzzles, creating a more and more challenging and entertaining game and obtaining a deeper understanding of the Artin-Tits group in the process.
This Artin-Tits game has only a rather rudimentary and not very good tutorial created by ChatGPT. It’s easy to play once you’ve got the hang of it, and in the end I think the easiest way to get the hang of it is to watch someone else play it for a couple of minutes. I have therefore created a video tutorial, which you can find here. The video itself lasts about 25 minutes, but the tutorial part is under 10 minutes: what makes the video longer is an explanation of various features for making it easier to create puzzles, and also an explanation of how the algorithm works, which again is much easier to explain if I can demonstrate it on screen than if I have to write down some text. (I do have some text, since that is what I used as a prompt for ChatGPT to implement the algorithm, but it took a few iterations to get it working properly, so now I’m not sure what the quality of the code will be like, or even whether it is doing exactly what I want, though it appears to be.) Although I have embedded the video into this post, if you actually want to see what is going on you will probably need to watch it on YouTube using the full screen. I recommend not watching the explanation of the algorithm until you have played the game a few times first. Also, I should warn you that the games in the Advanced category are not all soluble, but games 1, 5 and 6 definitely are. Another thing I forgot to say on the video is that if you want you can “rotate” a word by clicking on one of its letters and dragging it to the right or left. If the word is equal to the identity, then its rotations will be as well, so this is a valid move. There is also a button for disabling this rotation facility if you want the puzzle to be slightly more challenging.
A quick note about the availability of the two games. They are hosted on the Netlify platform. I am on their free plan, which gives me a certain number of “credits” each month. I’m not sure how quickly these will run out, largely because I have no idea how many people will actually think it interesting to play the games. If they do run out, then the games will cease to be available until the credits are renewed, which for me happens on the 10th of each month. If this has happened and you are keen to play one of the games, another option is to download the html files and open them in your browser. Here is a link to the Artin-Tits game and here is one to the Tseytin game. If you are feeling particularly public-spirited, especially if you think you will play quite a lot, then you might consider doing that anyway, so that the Netlify credits run down more slowly. If the running out of the credits is quick enough for all this to be a real issue, then I may move to a paid plan.
I’ll finish with a quick tip for playing the Artin-Tits game, which I mentioned on the video but perhaps didn’t stress enough. Many of the moves consist in selecting three consecutive letters and using a relation of the form to change them. Easy examples of this are replacement rules such as 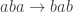 . But what if inverses are involved? I’ll represent inverses of generators with upper-case letters, so for example
. But what if inverses are involved? I’ll represent inverses of generators with upper-case letters, so for example 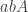 represents
represents 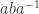 , which in the game would be a white followed by a white followed by a black . The word turns out to equal
, which in the game would be a white followed by a white followed by a black . The word turns out to equal 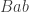 . To remember this, a simple rule is that two letters of the same colour can be bracketed together and “pushed past” the third letter, which retains its colour but changes its value. Here, for example, we write as
. To remember this, a simple rule is that two letters of the same colour can be bracketed together and “pushed past” the third letter, which retains its colour but changes its value. Here, for example, we write as 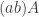 and then swap them over, changing into
and then swap them over, changing into 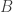 in the process, getting
in the process, getting 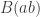 , or without the brackets. In group theoretic terms, this is of course saying that and are conjugates, and that
, or without the brackets. In group theoretic terms, this is of course saying that and are conjugates, and that 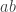 is what conjugates one to the other. But when playing the game it is convenient to remember it by thinking that when you see a subword such as
is what conjugates one to the other. But when playing the game it is convenient to remember it by thinking that when you see a subword such as 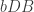 , you can push the
, you can push the 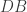 (and in particular the
(and in particular the 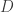 ) to the left, getting
) to the left, getting 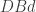 .
.


September 22, 2025
Creating a database of motivated proofs
It’s been over three years since my last post on this blog and I have sometimes been asked, understandably, whether the project I announced in my previous post was actually happening. The answer is yes — the grant I received from the Astera Institute has funded several PhD students and a couple of postdocs, and we have been busy. In my previous post I suggested that I would be open to remote collaboration, but that has happened much less, partly because a Polymath-style approach would have been difficult to manage while also ensuring that my PhD students would have work that they could call their own to put in their theses.
In general I don’t see a satisfactory solution to that problem, but in this post I want to mention a subproject of the main project that is very much intended to be a large public collaboration. A few months ago, a call came out from Renaissance Philanthropies saying that they were launching a $9m AI for Math Fund to spend on projects in the general sphere of AI and mathematics, and inviting proposals. One of the categories that they specifically mentioned was creating new databases, and my group submitted a proposal to create a database of what we call “structured motivated proofs,” a piece of terminology that I will explain a bit more later in just a moment. I am happy to report that our proposal was one of the 29 successful ones. Since a good outcome to the project will depend on collaboration from many people outside the group, we need to publicize it, which is precisely the purpose of this post. Below I will be more specific about the kind of help we are looking for.
Why might yet another database of theorems and proofs be useful?The underlying thought behind this project is that AI for mathematics is being held back not so much by an insufficient quantity of data as by the wrong kind of data. All mathematicians know, and some of us enjoy complaining about it, that it is common practice when presenting a proof in a mathematics paper or even textbook, to hide the thought processes that led to the proof. Often this does not matter too much, because the thought processes may be standard ones that do not need to be spelt out to the intended audience. But when proofs start to get longer and more difficult, they can be hard to read because one has to absorb definitions and lemma statements that are not obviously useful, are presented as if they appeared from nowhere, and demonstrate their utility only much later in the argument.
A sign that this is a problem for AI is the behaviour one observes after asking an LLM to prove a statement that is too difficult for it. Very often, instead of admitting defeat, it will imitate the style of a typical mathematics paper and produce rabbits out of hats, together with arguments later on that those rabbits do the required job. The problem is that, unlike with a correct mathematics paper, when one scrutinizes the arguments carefully, one finds that they are wrong. However, it is hard to distinguish between an incorrect rabbit and an incorrect argument justifying that rabbit (especially if the argument does not go into full detail) and a correct one, so the kinds of statistical methods used by LLMs do not have an easy way to penalize the incorrectness.
Of course, that does not mean that LLMs cannot do mathematics at all — they are remarkably good at it, at least compared with what I would have expected three years ago. How can that be, given the problem I have discussed in the previous paragraph?
The way I see it (which could change — things move so fast in this sphere), the data that is currently available to train LLMs and other systems is very suitable for a certain way of doing mathematics that I call guess and check. The rough idea is that you do routine parts of an argument without any fuss (and an LLM can do them too because it has seen plenty of similar examples), but if the problem as a whole is not routine, then at some point you have to stop and think, often because you need to construct an object that has certain properties (I mean this in a rather general way — the “object” might be a lemma that will split up the proof in a nice way) and it is not obvious how to do so. The guess-and-check approach to such moments is what it says: you make as intelligent a guess as you can and then see whether it has the properties you wanted. If it doesn’t, you make another guess, and you keep going until you get lucky.
The reason an LLM might be tempted to use this kind of approach is that the style of mathematical writing I described above makes it look as though that is what we as mathematicians do. Of course, we don’t do that, but we often omit to mention all the failed guesses we made and how we carefully examined why they failed, modifying them in appropriate ways in response, until we finally converged on an object that worked. We also don’t mention the reasoning that often takes place before we make the guess, saying to ourselves things like “Clearly an Abelian group can’t have that property, so I need to look for a non-Abelian group.”
Intelligent guess and check works well a lot of the time, particularly when carried out by an LLM that has seen many proofs of many theorems. I have often been surprised when I have asked an LLM a problem of the form 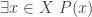 , where is some property that is hard to satisfy, and the LLM has had no trouble answering it. But somehow when this happens, the flavour of the answer given by the LLM leaves me with the impression that the technique it has used to construct
, where is some property that is hard to satisfy, and the LLM has had no trouble answering it. But somehow when this happens, the flavour of the answer given by the LLM leaves me with the impression that the technique it has used to construct  is one that it has seen before and regards as standard.
is one that it has seen before and regards as standard.
If the above picture of what LLMs can do is correct (the considerations for reinforcement-learning-based systems such as AlphaProof are not identical but I think that much of what I say in this post applies to them too for slightly different reasons), then the likely consequence is that if we pursue current approaches, then we will reach a plateau: broadly speaking they will be very good at answering a question if it is the kind of question that a mathematician with the right domain expertise and good instincts would find reasonably straightforward, but will struggle with anything that is not of that kind. In particular, they will struggle with research-level problems, which are, almost by definition, problems that experts in the area do not find straightforward. (Of course, there would probably be cases where an LLM spots relatively easy arguments that the experts had missed, but that wouldn’t fundamentally alter the fact that they weren’t really capable of doing research-level mathematics.)
But what if we had a database of theorems and proofs that did not hide the thought processes that lay behind the non-obvious details of the proofs? If we could train AI on a database of accounts of proof discoveries and if, having done so, we then asked it to provide similar accounts, then it would no longer resort to guess-and-check when it got stuck, because the proof-discovery accounts it had been trained on would not be resorting to it. There could be a problem getting it to unlearn its bad habits, but I don’t think that difficulty would be impossible to surmount.
The next question is what such a database might look like. One could just invite people to send in stream-of-consciousness accounts of how they themselves found certain proofs, but that option is unsatisfactory for several reasons.
It can be very hard to remember where an idea came from, even a few seconds after one has had it — in that respect it is like a dream, the memory of which becomes rapidly less vivid as one wakes up. Often an idea will seem fairly obvious to one person but not to another.The phrase “motivated proof” means different things to different people, so without a lot of careful moderation and curation of entries, there is a risk that a database would be disorganized and not much more helpful than a database of conventionally written proofs. A stream-of-consciousness account could end up being a bit too much about the person who finds the proof and not enough about the mathematical reasons for the proof being feasibly discoverable.To deal with these kinds of difficulties, we plan to introduce a notion of a structured motivated proof, by which we mean a proof that is generated in a very particular way that I will partially describe below. A major part of the project, and part of the reason we needed funding for it, is to create a platform that will make it convenient to input structured motivated proofs and difficult to insert the kinds of rabbits out of hats that make a proof mysterious and unmotivated. In this way we hope to gamify the task of creating the database, challenging people to input into our system proofs of certain theorems that appear to rely on “magic” ideas, and perhaps even offering prizes for proofs that contain steps that appear in advance to be particularly hard to motivate. (An example: the solution by Ellenberg and Gijswijt of the cap-set problem uses polynomials in a magic-seeming way. The idea of using polynomials came from an earlier paper of Croot, Lev and Pach that proved a closely related theorem, but in that paper it just appears in the statement of their Lemma 1, with no prior discussion apart from the words “in the present paper we use the polynomial method” in the introduction.)
What is a structured motivated proof?I wrote about motivated proofs in my previous post, but thanks to many discussions with other members of the group, my ideas have developed quite a lot since then. Here are two ways we like to think about the concept.
1. A structured motivated proof is one that is generated by standard moves.I will not go into full detail about what I mean by this, but will do so in a future post when we have created the platform that we would like people to use in order to input proofs into the database. But the basic idea is that at any one moment one is in a certain state, which we call a proof-discovery state, and there will be a set of possible moves that can take one from the current proof-discovery state to a new one.
A proof-discovery state is supposed to be a more formal representation of the state one is in when in the middle of solving a problem. Typically, if the problem is difficult, one will have asked a number of questions, and will be aware of logical relationships between them: for example, one might know that a positive answer to Q1 could be used to create a counterexample to Q2, or that Q3 is a special case of Q4, and so on. One will also have proved some results connected with the original question, and again these results will be related to each other and to the original problem in various ways that might be quite complicated: for example P1 might be a special case of Q2, which, if true would reduce Q3 to Q4, where Q3 is a generalization of the statement we are trying to prove.
Typically we will be focusing on one of the questions, and typically that question will take the form of some hypotheses and a target (the question being whether the hypotheses imply the target). One kind of move we might make is a standard logical move such as forwards or backwards reasoning: for example, if we have hypotheses of the form 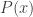 and
and 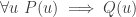 , then we might decide to deduce
, then we might decide to deduce 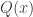 . But things get more interesting when we consider slightly less basic actions we might take. Here are three examples.
. But things get more interesting when we consider slightly less basic actions we might take. Here are three examples.
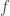 is given by the formula
is given by the formula 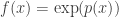 , where
, where 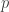 is a polynomial, and our goal is to prove that there exists
is a polynomial, and our goal is to prove that there exists  such that
such that 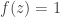 . Without really thinking about it, we are conscious that is a composition of two functions, one of which is continuous and one of which belongs to a class of functions that are all continuous, so is continuous. Also, the conclusion
. Without really thinking about it, we are conscious that is a composition of two functions, one of which is continuous and one of which belongs to a class of functions that are all continuous, so is continuous. Also, the conclusion 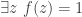 matches well the conclusion of the intermediate-value theorem. So the intermediate-value theorem comes naturally to mind and we add it to our list of available hypotheses. In practice we wouldn’t necessarily write it down, but the system we wish to develop is intended to model not just what we write down but also what is going on in our brains, so we propose a move that we call library extraction (closely related to what is often called premise selection in the literature). Note that we have to be a bit careful about library extraction, since we don’t want the system to be allowed to call up results from the library that appear to be irrelevant but then magically turn out to be helpful, since those would count as rabbits out of hats. So we want to allow extraction of results only if they are obvious given the context. It is not easy to define what “obvious” means, but there is a good rule of thumb for it: a library extraction is obvious if it is one of the first things ChatGPT thinks of when given a suitable non-cheating prompt. For example, I gave it the prompt, “I have a function from the reals to the reals and I want to prove that there exists some such that . Can you suggest any results that might be helpful?” and the intermediate-value theorem was its second suggestion. (Note that I had not even told it that was continuous, so I did not need to make that particular observation before coming up with the prompt.) We have a goal of the form
matches well the conclusion of the intermediate-value theorem. So the intermediate-value theorem comes naturally to mind and we add it to our list of available hypotheses. In practice we wouldn’t necessarily write it down, but the system we wish to develop is intended to model not just what we write down but also what is going on in our brains, so we propose a move that we call library extraction (closely related to what is often called premise selection in the literature). Note that we have to be a bit careful about library extraction, since we don’t want the system to be allowed to call up results from the library that appear to be irrelevant but then magically turn out to be helpful, since those would count as rabbits out of hats. So we want to allow extraction of results only if they are obvious given the context. It is not easy to define what “obvious” means, but there is a good rule of thumb for it: a library extraction is obvious if it is one of the first things ChatGPT thinks of when given a suitable non-cheating prompt. For example, I gave it the prompt, “I have a function from the reals to the reals and I want to prove that there exists some such that . Can you suggest any results that might be helpful?” and the intermediate-value theorem was its second suggestion. (Note that I had not even told it that was continuous, so I did not need to make that particular observation before coming up with the prompt.) We have a goal of the form 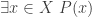 . If this were a Lean proof state, the most common way to discharge a goal of this form would be to input a choice for . That is, we would instantiate the existential quantifier with some
. If this were a Lean proof state, the most common way to discharge a goal of this form would be to input a choice for . That is, we would instantiate the existential quantifier with some 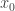 and our new goal would be
and our new goal would be 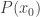 . However, as with library extraction, we have to be very careful about instantiation if we want our proof to be motivated, since we wish to disallow highly surprising choices of that can be found only after a long process of thought. So we have to restrict ourselves to obvious instantiations. Roughly speaking, what will count as an obvious instantiation in our system is instantiation with a term that is already present in the proof-discovery state. If no suitable term is present, then in order to continue with the proof, it will be necessary to carry out moves that generate a suitable term. A very common technique for this is the use of metavariables: instead of guessing a suitable , we create a variable
. However, as with library extraction, we have to be very careful about instantiation if we want our proof to be motivated, since we wish to disallow highly surprising choices of that can be found only after a long process of thought. So we have to restrict ourselves to obvious instantiations. Roughly speaking, what will count as an obvious instantiation in our system is instantiation with a term that is already present in the proof-discovery state. If no suitable term is present, then in order to continue with the proof, it will be necessary to carry out moves that generate a suitable term. A very common technique for this is the use of metavariables: instead of guessing a suitable , we create a variable 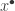 and change the goal to
and change the goal to 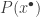 , which we can think of as saying “I’m going to start trying to prove even though I haven’t chosen yet. As the attempted proof proceeds, I will note down any properties
, which we can think of as saying “I’m going to start trying to prove even though I haven’t chosen yet. As the attempted proof proceeds, I will note down any properties  that might have that would help me finish the proof, in the hope that (i) I get to the end and (ii) the problem
that might have that would help me finish the proof, in the hope that (i) I get to the end and (ii) the problem 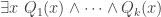 is easier than the original problem.” We cannot see how to answer the question we are focusing on so we ask a related question. Two very common kinds of related question (as emphasized by Polya) are generalization and specialization. Perhaps we don’t see why a hypothesis is helpful, so we see whether the result holds if we drop that hypothesis. If it does, then we are no longer distracted by an irrelevant hypothesis. If it does not, then we can hope to find a counterexample that will help us understand how to use the hypothesis. Or perhaps we are trying to prove a general statement but it is not clear how to do so, so instead we formulate some special cases, hoping that we can prove them and spot features of the proofs that we can generalize. Again we have to be rather careful here not to allow “non-obvious” generalizations and specializations. Roughly the idea there is that a generalization should be purely logical — for example, dropping a hypothesis is fine but replacing the hypothesis “ is twice differentiable” by “ is upper semicontinuous” is not — and that a specialization should be to a special case that is “extreme” in some way — one tries the smallest or largest or obviously simplest example that has not yet been investigated. 2. A structured motivated proof is one that can be generated with the help of a point-and-click system.
is easier than the original problem.” We cannot see how to answer the question we are focusing on so we ask a related question. Two very common kinds of related question (as emphasized by Polya) are generalization and specialization. Perhaps we don’t see why a hypothesis is helpful, so we see whether the result holds if we drop that hypothesis. If it does, then we are no longer distracted by an irrelevant hypothesis. If it does not, then we can hope to find a counterexample that will help us understand how to use the hypothesis. Or perhaps we are trying to prove a general statement but it is not clear how to do so, so instead we formulate some special cases, hoping that we can prove them and spot features of the proofs that we can generalize. Again we have to be rather careful here not to allow “non-obvious” generalizations and specializations. Roughly the idea there is that a generalization should be purely logical — for example, dropping a hypothesis is fine but replacing the hypothesis “ is twice differentiable” by “ is upper semicontinuous” is not — and that a specialization should be to a special case that is “extreme” in some way — one tries the smallest or largest or obviously simplest example that has not yet been investigated. 2. A structured motivated proof is one that can be generated with the help of a point-and-click system.This is a surprisingly useful way to conceive of what we are talking about, especially as it relates closely to what I was talking about earlier: imposing a standard form on motivated proofs (which is why we call them “structured” motivated proofs) and gamifying the process of producing them.
The idea is that a structured motivated proof is one that can be generated using an interface (which we are in the process of creating — at the moment we have a very basic prototype that has a few of the features we will need, but not yet the more interesting ones) that has one essential property: the user cannot type in data. So what can they do? They can select text that is on their screen (typically mathematical expressions or subexpressions), they can click buttons, choose items from drop-down menus, and accept or reject “obvious” suggestions made to them by the interface.
If, for example, the current goal is an existential statement 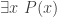 , then typing in a formula that defines a suitable is not possible, so instead one must select text or generate new text by clicking buttons, choosing from short drop-down menus, and so on. This forces the user to generate , which is our proxy for showing where the idea of using came from.
, then typing in a formula that defines a suitable is not possible, so instead one must select text or generate new text by clicking buttons, choosing from short drop-down menus, and so on. This forces the user to generate , which is our proxy for showing where the idea of using came from.
Broadly speaking, the way the prototype works is to get an LLM to read a JSON object that describes the variables, hypotheses and goals involved in the proof state in a structured format, and to describe (by means of a fairly long prompt) the various moves it might be called upon to do. Thus, the proofs generated by the system are not formally verified, but that is not an issue that concerns us in practice since there will be a human in the loop throughout to catch any mistakes that the LLM might make, and this flexibility may even work to our advantage to better capture the fluidity of natural-language mathematics.
There is obviously a lot more to say about what the proof-generating moves are, or (approximately equivalently) what the options provided by a point-and-click system will be. I plan to discuss that in much more detail when we are closer to having an interface ready, the target for which is the end of this calendar year. But the aim of the project is to create a database of examples of proofs that have been successfully generated using the interface, which can then be used to train AI to play the generate-structured-motivated-proof game.
How to get involved.There are several tasks that will need doing once the project gets properly under way. Here are some of the likely ones.
The most important is for people to submit structured motivated (or move-generated) proofs to us on the platform we provide. We hope that the database will end up containing proofs of a wide range of difficulty (of two kinds — there might be fairly easy arguments that are hard to motivate and there might be arguments that are harder to follow but easier to motivate) and also a wide range of areas of mathematics. Our initial target, which is quite ambitious, is to have around 1000 entries by two years from now. While we are not in a position to accept entries yet, if you are interested in participating, then it is not too early to start thinking in a less formal way about how to convert some of your favourite proofs into motivated versions, since that will undoubtedly make it easier to get them accepted by our platform when it is ready.We are in the process of designing the platform. As I mentioned earlier, we already have a prototype, but there are many moves we will need it to be able to do that it cannot currently do. For example, the current prototype allows just a single proof state, which consists of some variable declarations, hypotheses, and goals. It does not yet support creating subsidiary proof states (which we would need if we wanted to allow the user to consider generalizations and specializations, for example). Also, for the moment the prototype gets an LLM to implement all moves, but some of the moves, such as applying modus ponens, are extremely mechanical and would be better done using a conventional program. (On the other hand, moves such as “obvious library extraction” are better done by an LLM.) Thirdly, a technical problem is that LaTeX is currently rendered as images, which makes it hard to select subexpressions, something we will need to be able to do in a non-clunky way. And the public version of the platform will need to be web-based and very convenient to use. We will want features such as being able to zoom out and look at some kind of dependency diagram of all the statements and questions currently in play, and then zoom in on various nodes if the user wishes to work on them. If you think you may be able (and willing) to help with some of these aspects of the platform, then we would be very happy to hear from you. For some, it would probably help to have a familiarity with proof assistants, while for others we would be looking for somebody with software engineering experience. The grant from the AI for Math Fund will allow us to pay for some of this help, at rates to be negotiated. We are not yet ready to specify in detail what help we need, but would welcome any initial expressions of interest. Once the platform is ready and people start to submit proofs, it is likely that, at least to start with, they will find that the platform does not always provide the moves they need. Perhaps they will have a very convincing account of where a non-obvious idea in the proof came from, but the system won’t be expressive enough for them to translate that account into a sequence of proof-generating moves. We will want to be able to react to such situations (if we agree that a new move is needed) by expanding the capacity of the platform. It will therefore be very helpful if people sign up to be beta-testers, so that we can try to get the platform to a reasonably stable state before opening it up to a wider public. Of course, to be a beta-tester you would need to have a few motivated proofs in mind. It is not obvious that every proof submitted via the platform, even if submitted successfully, would be a useful addition to the database. For instance, it might be such a routine argument that no idea really needs to have its origin explained. Or it might be that, despite our best efforts, somebody finds a way of sneaking in a rabbit while using only the moves that we have provided. (One way this could happen is if an LLM made a highly non-obvious suggestion that happened to work, in which case the rule of thumb that if an LLM thinks of it, it must be obvious, would have failed in that instance.) For this reason, we envisage having a team of moderators, who will check entries and make sure that they are good additions to the database. We hope that this will be an enjoyable task, but it may have its tedious aspects, so we envisage paying moderators — again, this expense was allowed for in our proposal to the AI for Math Fund.If you think you might be interested in any of these roles, please feel free to get in touch. Probably the hardest recruitment task for us will be identifying the right people with the right mixture of to help us turn the platform into a well-designed web-based one that is convenient and pleasurable to use. If you think you might be such a person, or if you have a good idea for how we should go about finding one, we would be particularly interested to hear from you.
In a future post, I will say more about the kinds of moves that our platform will allow, and will give examples of non-motivated proofs together with how motivated versions of those proofs can be found, and entered using the platform (which may involve a certain amount of speculation about what the platform will end up looking like).
How does this relate to use of tactics in a proof assistant?In one way, our “moves” can be regarded as tactics of a kind. However, some of the moves we will need are difficult to implement in conventional proof assistants such as Lean. In parallel with the work described above, we hope to create an interface to Lean that would allow one to carry out proof-discovery moves of the kind discussed above but with the proof-discovery states being collections of Lean proof states. Members of my group have already been working on this and have made some very interesting progress, but there is some way to go. However, we hope that at some point (and this is also part of the project pitched to the AI for Math Fund) that we will have created another interface that will have Lean working in the background, so that it will be possible to generate motivated proofs that will be (or perhaps it is better to say include) proofs in Lean at the same time.
Another possibility that we are also considering is to use the output of the first platform (which, as mentioned above, will be fairly formal, but not in the strict sense of a language such as Lean) to create a kind of blueprint that can then be autoformalized automatically. Then we would have a platform that would in principle allow mathematicians to search for proofs while working on their computers, without having to learn a formal language, and with their thoughts being formalized as they go.
April 28, 2022
Announcing an automatic theorem proving project
I am very happy to say that I have recently received a generous grant from the Astera Institute to set up a small group to work on automatic theorem proving, in the first instance for about three years after which we will take stock and see whether it is worth continuing. This will enable me to take on up to about three PhD students and two postdocs over the next couple of years. I am imagining that two of the PhD students will start next October and that at least one of the postdocs will start as soon as is convenient for them. Before any of these positions are advertised, I welcome any informal expressions of interest: in the first instance you should email me, and maybe I will set up Zoom meetings. (I have no idea what the level of demand is likely to be, so exactly how I respond to emails of this kind will depend on how many of them there are.)
I have privately let a few people know about this, and as a result I know of a handful of people who are already in Cambridge and are keen to participate. So I am expecting the core team working on the project to consist of 6-10 people. But I also plan to work in as open a way as possible, in the hope that people who want to can participate in the project remotely even if they are not part of the group that is based physically in Cambridge. Thus, part of the plan is to report regularly and publicly on what we are thinking about, what problems, both technical and more fundamental, are holding us up, and what progress we make. Also, my plan at this stage is that any software associated with the project will be open source, and that if people want to use ideas generated by the project to incorporate into their own theorem-proving programs, I will very much welcome that.
I have written a 54-page document that explains in considerable detail what the aims and approach of the project will be. I would urge anyone who thinks they might want to apply for one of the positions to read it first — not necessarily every single page, but enough to get a proper understanding of what the project is about. Here I will explain much more briefly what it will be trying to do, and what will set it apart from various other enterprises that are going on at the moment.
In brief, the approach taken will be what is often referred to as a GOFAI approach, where GOFAI stands for “good old-fashioned artificial intelligence”. Roughly speaking, the GOFAI approach to artificial intelligence is to try to understand as well as possible how humans achieve a particular task, and eventually reach a level of understanding that enables one to program a computer to do the same.
As the phrase “old-fashioned” suggests, GOFAI has fallen out of favour in recent years, and some of the reasons for that are good ones. One reason is that after initial optimism, progress with that approach stalled in many domains of AI. Another is that with the rise of machine learning it has become clear that for many tasks, especially pattern-recognition tasks, it is possible to program a computer to do them very well without having a good understanding of how humans do them. For example, we may find it very difficult to write down a set of rules that distinguishes between an array of pixels that represents a dog and an array of pixels that represents a cat, but we can still train a neural network to do the job.
However, while machine learning has made huge strides in many domains, it still has several areas of weakness that are very important when one is doing mathematics. Here are a few of them.
In general, tasks that involve reasoning in an essential way. Learning to do one task and then using that ability to do another. Learning based on just a small number of examples. Common sense reasoning.Anything that involves genuine understanding (even if it may be hard to give a precise definition of what understanding is) as opposed to sophisticated mimicry.Obviously, researchers in machine learning are working in all these areas, and there may well be progress over the next few years [in fact, there has been progress on some of these difficulties already of which I was unaware — see some of the comments below], but for the time being there are still significant limitations to what machine learning can do. (Two people who have written very interestingly on these limitations are Melanie Mitchell and François Chollet.)
That said, using machine learning techniques in automatic theorem proving is a very active area of research at the moment. (Two names you might like to look up if you want to find out about this area are Christian Szegedy and Josef Urban.) The project I am starting will not be a machine-learning project, but I think there is plenty of potential for combining machine learning with GOFAI ideas — for example, one might use GOFAI to reduce the options for what the computer will do next to a small set and use machine learning to choose the option out of that small set — so I do not rule out some kind of wider collaboration once the project has got going.
Another area that is thriving at the moment is formalization. Over the last few years, several major theorems and definitions have been fully formalized that would have previously seemed out of reach — examples include Gödel’s theorem, the four-colour theorem, Hales’s proof of the Kepler conjecture, Thompson’s odd-order theorem, and a lemma of Dustin Clausen and Peter Scholze with a proof that was too complicated for them to be able to feel fully confident that it was correct. That last formalization was carried out in Lean by a team led by Johan Commelin, which is part of the more general and exciting Lean group spearheaded by Kevin Buzzard.
As with machine learning, I mention formalization in order to contrast it with the project I am announcing here. It may seem slightly negative to focus on what it will not be doing, but I feel it is important, because I do not want to attract applications from people who have an incorrect picture of what they would be doing. Also as with machine learning, I would welcome and even expect collaboration with the Lean group. For us it would be potentially very interesting to make use of the Lean database of results, and it would also be nice (even if not essential) to have output that is formalized using a standard system. And we might be able to contribute to the Lean enterprise by creating code that performs steps automatically that are currently done by hand. A very interesting looking new institute, the Hoskinson Center for Formal Mathematics, has recently been set up with Jeremy Avigad at the helm, which will almost certainly make such collaborations easier.
But now let me turn to the kinds of things I hope this project will do.
Why is mathematics easy?Ever since Turing, we have known that there is no algorithm that will take as input a mathematical statement and output a proof if the statement has a proof or the words “this statement does not have a proof” otherwise. (If such an algorithm existed, one could feed it statements of the form “algorithm A halts” and the halting problem would be solved.) If 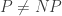 , then there is not even a practical algorithm for determining whether a statement has a proof of at most some given length — a brute-force algorithm exists, but takes far too long. Despite this, mathematicians regularly find long and complicated proofs of theorems. How is this possible?
, then there is not even a practical algorithm for determining whether a statement has a proof of at most some given length — a brute-force algorithm exists, but takes far too long. Despite this, mathematicians regularly find long and complicated proofs of theorems. How is this possible?
The broad answer is that while the theoretical results just alluded to show that we cannot expect to determine the proof status of arbitrary mathematical statements, that is not what we try to do. Rather, we look at only a tiny fraction of well-formed statements, and the kinds of proofs we find tend to have a lot more structure than is guaranteed by the formal definition of a proof as a sequence of statements, each of which is either an initial assumption or follows in a simple way from earlier statements. (It is interesting to speculate about whether there are, out there, utterly bizarre and idea-free proofs that just happen to establish concise mathematical statements but that will never be discovered because searching for them would take too long.) A good way of thinking about this project is that it will be focused on the following question.
Question. What is it about the proofs that mathematicians actually find that makes them findable in a reasonable amount of time?
Clearly, a good answer to this question would be extremely useful for the purposes of writing automatic theorem proving programs. Equally, any advances in a GOFAI approach to writing automatic theorem proving programs have the potential to feed into an answer to the question. I don’t have strong views about the right balance between the theoretical and practical sides of the project, but I do feel strongly that both sides should be major components of it.
The practical side of the project will, at least to start with, be focused on devising algorithms that find proofs in a way that imitates as closely as possible how humans find them. One important aspect of this is that I will not be satisfied with programs that find proofs after carrying out large searches, even if those searches are small enough to be feasible. More precisely, searches will be strongly discouraged unless human mathematicians would also need to do them. A question that is closely related to the question above is the following, which all researchers in automatic theorem proving have to grapple with.
Question. Humans seem to be able to find proofs with a remarkably small amount of backtracking. How do they prune the search tree to such an extent?
Allowing a program to carry out searches of “silly” options that humans would never do is running away from this absolutely central question.
With Mohan Ganesalingam, Ed Ayers and Bhavik Mehta (but not simultaneously), I have over the years worked on writing theorem-proving programs with as little search as possible. This will provide a starting point for the project. One of the reasons I am excited to have the chance to set up a group is that I have felt for a long time that with more people working on the project, there is a chance of much more rapid progress — I think the progress will scale up more than linearly in the number of people, at least up to a certain size. And if others were involved round the world, I don’t think it is unreasonable to hope that within a few years there could be theorem-proving programs that were genuinely useful — not necessarily at a research level but at least at the level of a first-year undergraduate. (To be useful a program does not have to be able to solve every problem put in front of it: even a program that could solve only fairly easy problems but in a sufficiently human way that it could explain how it came up with its proofs could be a very valuable educational tool.)
A more distant dream is of course to get automatic theorem provers to the point where they can solve genuinely difficult problems. Something else that I would like to see coming out of this project is a serious study of how humans do this. From time to time I have looked at specific proofs that appear to require at a certain point an idea that comes out of nowhere, and after thinking very hard about them I have eventually managed to present a plausible account of how somebody might have had the idea, which I think of as a “justified proof”. I would love it if there were a large collection of such accounts, and I have it in mind as a possible idea to set up (with help) a repository for them, though I would need to think rather hard about how best to do it. One of the difficulties is that whereas there is widespread agreement about what constitutes a proof, there is not such a clear consensus about what constitutes a convincing explanation of where an idea comes from. Another theoretical problem that interests me a lot is the following.
Problem. Come up with a precise definition of a “proof justification”.
Though I do not have a satisfactory definition, very recently I have had some ideas that will I think help to narrow down the search substantially. I am writing these ideas down and hope to make them public soon.
Who am I looking for?There is much more I could say about the project, but if this whets your appetite, then I refer you to the document where I have said much more about it. For the rest of this post I will say a little bit more about the kind of person I am looking for and how a typical week might be spent.
The most important quality I am looking for in an applicant for a PhD or postdoc associated with this project is a genuine enthusiasm for the GOFAI approach briefly outlined here and explained in more detail in the much longer document. If you read that document and think that that is the kind of work you would love to do and would be capable of doing, then that is a very good sign. Throughout the document I give indications of things that I don’t yet know how to do. If you find yourself immediately drawn into thinking about those problems, which range from small technical problems to big theoretical questions such as the ones mentioned above, then that is even better. And if you are not fully satisfied with a proof unless you can see why it was natural for somebody to think of it, then that is better still.
I would expect a significant proportion of people reading the document to have an instinctive reaction that the way I propose to attack the problems is not the best way, and that surely one should use some other technique — machine learning, large search, the Knuth-Bendix algorithm, a computer algebra package, etc. etc. — instead. If that is your reaction, then the project probably isn’t a good fit for you, as the GOFAI approach is what it is all about.
As far as qualifications are concerned, I think the ideal candidate is somebody with plenty of experience of solving mathematical problems (either challenging undergraduate-level problems for a PhD candidate or research-level problems for a postdoc candidate), and good programming ability. But if I had to choose one of the two, I would pick the former over the latter, provided that I could be convinced that a candidate had a deep understanding of what a well-designed algorithm would look like. (I myself am not a fluent programmer — I have some experience of Haskell and Python and I think a pretty good feel for how to specify an algorithm in a way that makes it implementable by somebody who is a quick coder, and in my collaborations so far have relied on my collaborators to do the coding.) Part of the reason for that is that I hope that if one of the outputs of the group is detailed algorithm designs, then there will be remote participants who would enjoy turning those designs into code.
How will the work be organized?The core group is meant to be a genuine team rather than simply a group of a few individuals with a common interest in automatic theorem proving. To this end, I plan that the members of the group will meet regularly — I imagine something like twice a week for at least two hours and possibly more — and will keep in close contact, and very likely meet less formally outside those meetings. The purpose of the meetings will be to keep the project appropriately focused. That is not to say that all team members will work on the same narrow aspect of the problem at the same time. However, I think that with a project like this it will be beneficial (i) to share ideas frequently, (ii) to keep thinking strategically about how to get the maximum expected benefit for the effort put in , and (iii) to keep updating our public list of open questions (which will not be open questions in the usual mathematical sense, but questions more like “How should a computer do this?” or “Why is it so obvious to a human mathematician that this would be a silly thing to try?”).
In order to make it easy for people to participate remotely, I think probably we will want to set up a dedicated website where people can post thoughts, links to code, questions, and so on. Some thought will clearly need to go into how best to design such a site, and help may be needed to build it, which if necessary I could pay for. Another possibility would of course be to have Zoom meetings, but whether or not I would want to do that depends somewhat on who ends up participating and how they do so.
Since the early days of Polymath I have become much more conscious that merely stating that a project is open to anybody who wishes to join in does not automatically make it so. For example, whereas I myself am comfortable with publicly suggesting a mathematical idea that turns out on further reflection to be fruitless or even wrong, many people are, for very good reasons, not willing to do so, and those people belong disproportionately to groups that have been historically marginalized from mathematics — which of course is not a coincidence. Because of this, I have not yet decided on the details of how remote participation might work. Maybe part of it could be fully open in the way that Polymath was, but part of it could be more private and carefully moderated. Or perhaps separate groups could be set up that communicated regularly with the Cambridge group. There are many possibilities, but which ones would work best depends on who is interested. If you are interested in the project but would feel excluded by certain modes of participation, then please get in touch with me and we can think about what would work for you.
January 30, 2021
Leicester mathematics under threat again
Four years ago I wrote a post about an awful plan by Leicester University to sack its entire mathematics department, invite them to reapply for their jobs, and rehire all but six “lowest performers”. Fortunately, after an outcry, the university backed down.
Alas, now there’s a new vice-chancellor who appears to have learned nothing from the previous debacle. This time, the plan, known by the nice fluffy name Shaping for Excellence, is to get rid of research in certain subjects of which pure mathematics is one (and medieval literature another). This would mean making all eight pure mathematicians at Leicester redundant. The story is spreading rapidly on social media (it’s attracted quite a bit of attention on Twitter, Reddit and Hacker News, for example), so I won’t write a long post. But just in case you haven’t heard about it, here’s a link to a petition you can sign if, like a lot of other people, you feel strongly that this is a bad decision. (At the time of writing, it has been signed by about 2,500 people, many of them very well known academics in the areas that Leicester University claims to be intending to promote, in well under 24 hours.)
May 20, 2020
Mathematical Research Reports: a “new” mathematics journal is launched
From time to time academic journals undergo an interesting process of fission. Typically as a result of some serious dissatisfaction, the editorial board resigns en masse to set up a new journal, the publishers of the original journal build a new editorial board from scratch, and the result is two journals, one inheriting the editors and collective memory of the original journal, and the other keeping the name and the publisher. Which is the “true” successor? In practice it tends to be the one with the editors, with its sibling surviving as a zombie journal that is the successor in name only. Perhaps there are examples that go the other way, and there may be examples where both journals go on to thrive, but I have not looked closely at the examples I know about.
I’m mentioning this because recently I have been involved in a rather unusual example of this phenomenon. Most cases I know of are the result either of frustration with the practices of the big commercial publishers or of malpractice by an editor-in-chief. But this was an open access journal with no publication charges, and with an extremely efficient and impeccably behaved editor-in-chief. So what was the problem?
The journal started out in 1995 as Electronic Research Announcements of the AMS, or ERA-AMS for short. It was still called that when I first joined the editorial board. Its editor-in-chief was Svetlana Katok, who did a great job, and there was a high-powered editorial board. As its name suggests, it specialized in shortish papers announcing results that would then appear with more details in significantly longer papers, so it was a little like Comptes Rendus in its aim. It would also accept short articles of a more traditional kind.
It never published all that many papers, and in 2007, I think for that reason (but don’t remember for sure), the AMS decided to discontinue it. But Svetlana Katok had put a lot into the journal and managed to find another publisher, the American Institute of Mathematical Sciences, and the editorial board agreed to continue serving. The name of the journal was changed to Electronic Research Announcements in the Mathematical Sciences, and its abbreviation was slightly abbreviated from ERA-AMS to ERA-MS.
In 2016, after 22 years, Svetlana Katok decided to step down, and Boris Hasselblatt took over. It was a good moment to try to revitalize the journal, so measures were taken such as designing a new and better website and making more effort to publicize the journal, in the hope of attracting more submissions (or more precisely, more submissions of a high enough quality that we would want to publish them).
However, despite these measures, the numbers remained fairly low — around ten a year (with quite a bit of variation), and this, indirectly, caused the problem that led to the split. The editors would have liked to see more papers published, but were not worried about it to the point where we would have been prepared to sacrifice quality to achieve it: we were ready to accept that this was, at least for now, a small journal. But AIMS was not so happy. In an effort to remedy (as they saw it) the situation, they appointed a co-editor-in-chief, who in turn appointed a number of new editors, with a more applied focus, with the idea that by broadening the scope of the journal they would increase the number of papers published.
That did not precipitate the resignations, but at that stage most of us did not know that the new editors had been appointed without any consultation even with Boris Hasselblatt. But then AIMS took things a step further. Until that point, the journal had adopted a practice that I strongly approve of, which was for the editor who handled a paper to make a recommendation to the rest of the editorial board, with other editors encouraged to comment on that recommendation. This practice helps to guard against “rogue” editors and against abuse of the system in general. It also helps to maintain consistent standards, and provides a gentle pressure on editors to do their job conscientiously — there’s nothing like knowing that you’re going to have to justify your decision to a bunch of mathematicians.
But suddenly the publishers told us that this system had to change, and that from now on the editorial board would not have the opportunity to vet papers, and would continue to have no say in new editorial appointments. (Various justifications were given for this, including that it would make it harder to recruit editors if they thought they had to make judgments about papers not in their immediate area.) At that point, it was clear that the soul of the journal was about to be destroyed, so over a few days the entire board (from before the start of the changes) resigned, resolving to start afresh with a new name.
That new name is Mathematical Research Reports. We will continue to accept reports on longer work, as well as short articles. In addition we welcome short survey articles. We regard it as the continuation in spirit of ERA-MS. Another unusual feature of this particular split is that the other half, still published by AIMS, has also changed its name and is now called Electronic Research Archive.
If, like me, you are always on the lookout for high-quality “ethical” journals (which I loosely define as free to read, free to publish in, and adopting high standards of editorial practice), then please add Mathematical Research Reports to your list. Have a look at the back catalogue of ERA-MS and ERA-AMS and you will get an idea of our standards. It would be wonderful if the unfortunate events of the last year or so were to be the catalyst that led to the journal finally becoming established in the way that it has deserved to be for a long time.
March 28, 2020
How long should a lockdown-relaxation cycle last?
On page 12 of a document put out by Imperial College London, which has been very widely read and commented on, and which has had a significant influence on UK policy concerning the coronavirus, there is a diagram that shows the possible impact of a strategy of alternating between measures that are serious enough to cause the number of cases to decline, and more relaxed measures that allow it to grow again. They call this adaptive triggering: when the number of cases needing intensive care reaches a certain level per week, the stronger measures are triggered, and when it declines to some other level (the numbers they give are 100 and 50, respectively), they are lifted.
If such a policy were ever to be enacted, a very important question would be how to optimize the choice of the two triggers. I’ve tried to work this out, subject to certain simplifying assumptions (and it’s important to stress right at the outset that these assumptions are questionable, and therefore that any conclusion I come to should be treated with great caution). This post is to show the calculation I did. It leads to slightly counterintuitive results, so part of my reason for posting it publicly is as a sanity check: I know that if I post it here, then any flaws in my reasoning will be quickly picked up. And the contrapositive of that statement is that if the reasoning survives the harsh scrutiny of a typical reader of this blog, then I can feel fairly confident about it. Of course, it may also be that I have failed to model some aspect of the situation that would make a material difference to the conclusions I draw. I would be very interested in criticisms of that kind too. (Indeed, I make some myself in the post.)
Before I get on to what the model is, I would like to make clear that I am not advocating this adaptive-triggering policy. Personally, what I would like to see is something more like what Tomas Pueyo calls The Hammer and the Dance: roughly speaking, you get the cases down to a trickle, and then you stop that trickle turning back into a flood by stamping down hard on local outbreaks using a lot of testing, contact tracing, isolation of potential infected people, etc. (This would need to be combined with other measures such as quarantine for people arriving from more affected countries etc.) But it still seems worth thinking about the adaptive-triggering policy, in case the hammer-and-dance policy doesn’t work (which could be for the simple reason that a government decides not to implement it).
A very basic model.
Here was my first attempt at modelling the situation. I make the following assumptions. The numbers 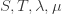 are positive constants.
are positive constants.
Relaxation is triggered when the rate of infection is
 .
.Lockdown (or similar) is triggered when the rate of infection is
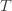 .
.The rate of infection is of the form
 during a relaxation phase.
during a relaxation phase.The rate of infection is of the form
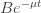 during a lockdown phase.
during a lockdown phase.The rate of “damage” due to infection is
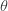 times the infection rate.
times the infection rate.The rate of damage due to lockdown measures is
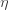 while those measures are in force.
while those measures are in force.For the moment I am not concerned with how realistic these assumptions are, but just with what their consequences are. What I would like to do is minimize the average damage by choosing and appropriately.
I may as well give away one of the punchlines straight away, since no calculation is needed to explain it. The time it takes for the infection rate to increase from to or to decrease from to depends only on the ratio 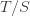 . Therefore, if we divide both and by 2, we decrease the damage due to the infection and have no effect on the damage due to the lockdown measures. Thus, for any fixed ratio , it is best to make both and as small as possible.
. Therefore, if we divide both and by 2, we decrease the damage due to the infection and have no effect on the damage due to the lockdown measures. Thus, for any fixed ratio , it is best to make both and as small as possible.
This has the counterintuitive consequence that during one of the cycles one would be imposing lockdown measures that were doing far more damage than the damage done by the virus itself. However, I think something like that may actually be correct: unless the triggers are so low that the assumptions of the model completely break down (for example because local containment is, at least for a while, a realistic policy, so national lockdown is pointlessly damaging), there is nothing to be lost, and lives to be gained, by keeping them in the same proportion but decreasing them.
Now let me do the calculation, so that we can think about how to optimize the ratio for a fixed .
The time taken for the infection rate to increase from to is 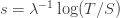 , and during that time the number of infections is
, and during that time the number of infections is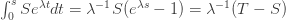 .
.
By symmetry the number of infections during the lockdown phase is 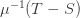 (just run time backwards). So during a time
(just run time backwards). So during a time 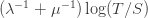 the damage done by infections is
the damage done by infections is 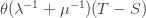 , making the average damage
, making the average damage 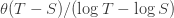 . Meanwhile, the average damage done by lockdown measures over the whole cycle is
. Meanwhile, the average damage done by lockdown measures over the whole cycle is 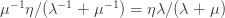 .
.
Note that the lockdown damage doesn’t depend on and : it just depends on the proportion of time spent in lockdown, which depends only on the ratio between 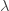 and
and 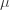 . So from the point of view of optimizing and , we can simply forget about the damage caused by the lockdown measures.
. So from the point of view of optimizing and , we can simply forget about the damage caused by the lockdown measures.
Returning, therefore, to the term , let us say that 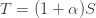 . Then the term simplifies to
. Then the term simplifies to 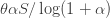 . This increases with
. This increases with  , which leads to a second counterintuitive conclusion, which is that for fixed , should be as close as possible to 0. So if, for example,
, which leads to a second counterintuitive conclusion, which is that for fixed , should be as close as possible to 0. So if, for example, 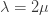 , which tells us that the lockdown phases have to be twice as long as the relaxation phases, then it would be better to have cycles of two days of lockdown and one of relaxation than cycles of six weeks of lockdown and three weeks of relaxation.
, which tells us that the lockdown phases have to be twice as long as the relaxation phases, then it would be better to have cycles of two days of lockdown and one of relaxation than cycles of six weeks of lockdown and three weeks of relaxation.
Can this be correct? It seems as though with very short cycles the lockdowns wouldn’t work, because for one day in three people would be out there infecting others. I haven’t yet got my head round this, but I think what has gone wrong is that the model of exponential growth followed instantly by exponential decay is too great a simplification of what actually happens. Indeed, data seem to suggest a curve that rounds off at the top rather than switching suddenly from one exponential to another — see for example Chart 9 from the Tomas Pueyo article linked to above. But I think it is correct to conclude that the length of a cycle should be at most of a similar order of magnitude to the “turnaround time” from exponential growth to exponential decay. That is, one should make the cycles as short as possible provided that they are on a timescale that is long enough for the assumption of exponential growth followed by exponential decay to be reasonably accurate.
What if we allow a cycle with more than two kinds of phases?
So far I have treated and and as parameters that we have no control over at all. But in practice that is not the case. At any one time there is a suite of measures one can take — encouraging frequent handwashing, banning large gatherings, closing schools, encouraging working from home wherever possible, closing pubs, restaurants, theatres and cinemas, enforcing full lockdown — that have different effects on the rate of growth or decline in infection and cause different levels of damage.
It seems worth taking this into account too, especially as there has been a common pattern of introducing more and more measures as the number of cases goes up. That feels like a sensible response — intuitively one would think that the cure should be kept proportionate — but is it?
Let’s suppose we have a collection of possible sets of measures  . For ease of writing I shall call them measures rather than sets of measures, but in practice each
. For ease of writing I shall call them measures rather than sets of measures, but in practice each 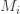 is not just a single measure but a combination of measures such as the ones listed above. Associated with each measure is a growth rate
is not just a single measure but a combination of measures such as the ones listed above. Associated with each measure is a growth rate 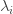 (which is positive if the measures are not strong enough to stop the disease growing and negative if they are strong enough to cause it to decay) and a damage rate
(which is positive if the measures are not strong enough to stop the disease growing and negative if they are strong enough to cause it to decay) and a damage rate 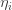 . Suppose we apply for time
. Suppose we apply for time 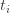 . Then during that time the rate of infection will multiply by
. Then during that time the rate of infection will multiply by 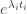 . So if we do this for each measure, then we will get back to the starting infection rate provided that
. So if we do this for each measure, then we will get back to the starting infection rate provided that 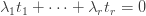 . (This is possible because some of the are negative and some are positive.)
. (This is possible because some of the are negative and some are positive.)
There isn’t a particularly nice expression for the damage resulting from the disease during one of these cycles, but that does not mean that there is nothing to say. Suppose that the starting rate of infection is 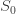 and that the rate after the first
and that the rate after the first  stages of the cycle is
stages of the cycle is 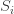 . Then
. Then 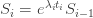 . Also, by the calculation above, the damage done during the th stage is
. Also, by the calculation above, the damage done during the th stage is 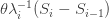 .
.
In what order should the
be applied?This has an immediate consequence for the order in which the should be applied. Let me consider just the first two stages. The total damage caused by the disease during these two stages is
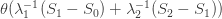
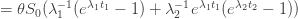 .
.
To make that easier to read, let’s forget the 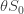 term (which we’re holding constant) and concentrate on the expression
term (which we’re holding constant) and concentrate on the expression
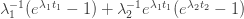 .
.
If we reorder stages 1 and 2, we can replace this damage by
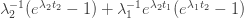 .
.
This is an improvement if the second number is smaller than the first. But the first minus the second is equal to
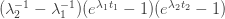 ,
,
so the reordering is a good idea if 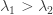 . This tells us that we should start with smaller and work up to bigger ones. Of course, since we are applying the measures in a cycle, we cannot ensure that the form an increasing sequence, but we can say, for example, that if we first apply the measures that allow the disease to spread, and then the ones that get it to decay, then during the relaxation phase we should work from the least relaxed measures to the most relaxed ones (so the growth rate will keep increasing), and during the suppression phase we should start with the strictest measures and work down to the most relaxed ones.
. This tells us that we should start with smaller and work up to bigger ones. Of course, since we are applying the measures in a cycle, we cannot ensure that the form an increasing sequence, but we can say, for example, that if we first apply the measures that allow the disease to spread, and then the ones that get it to decay, then during the relaxation phase we should work from the least relaxed measures to the most relaxed ones (so the growth rate will keep increasing), and during the suppression phase we should start with the strictest measures and work down to the most relaxed ones.
It might seem strange that during the relaxation phase the measures should get gradually more relaxed as the spread worsens. In fact, I think it is strange, but I think what that strangeness is telling us is that using several different measures during the relaxation phase is not a sensible thing to do.
Which sets of measures should be chosen?
The optimization problem I get if I try to balance the damage from the disease with the damage caused by the various control measures is fairly horrible, so I am going to simplify it a lot in the following way. The basic principle that there is nothing to be lost by dividing everything by 2 still applies when there are lots of measures, so I shall assume that a sensible government has taken that point on board to the point where the direct damage from the disease is insignificant compared with the damage caused by the measures. (Just to be clear, I certainly don’t mean that lives lost are insignificant, but I mean that the number of lives lost to the disease is significantly smaller than the number lost as an indirect result of the measures taken to control its spread.) Given this assumption, I am free to concentrate just on the damage due to the measures , so this is what I will try to minimize.
The total damage across a full cycle is 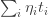 , so the average damage, which is what matters here, is
, so the average damage, which is what matters here, is
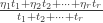 .
.
We don’t have complete freedom to choose, or else we’d obviously just choose the smallest and go with that. The constraint is that the growth rate of the virus has to end up where it began: this is the constraint that , which we saw earlier.
Suppose we can find 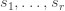 such that
such that  , but
, but 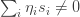 . Then in particular we can find such with
. Then in particular we can find such with 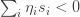 . If all the are strictly positive, then we can also choose them in such a way that all the
. If all the are strictly positive, then we can also choose them in such a way that all the 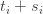 are still strictly positive. So if we replace each by
are still strictly positive. So if we replace each by 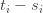 , then the numerator of the fraction decreases, the denominator stays the same, and the constraint is still satisfied. It follows that we had not optimized.
, then the numerator of the fraction decreases, the denominator stays the same, and the constraint is still satisfied. It follows that we had not optimized.
Therefore, if the choice of  is optimal and all the are non-zero (and therefore strictly positive — we can’t run some measures for a negative amount of time) it is not possible to find such that , but . This is equivalent to the statement that the vector
is optimal and all the are non-zero (and therefore strictly positive — we can’t run some measures for a negative amount of time) it is not possible to find such that , but . This is equivalent to the statement that the vector  is a linear combination of the vectors
is a linear combination of the vectors 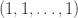 and
and  . In other words, we can find
. In other words, we can find  such that
such that 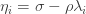 for each . I wrote it like that because the smaller is, the larger the damage one expects the measures to cause. Thus, the points form a descending sequence. (We can assume this, since if one measure causes both more damage and a higher growth rate than another, then there can be no reason to choose it.) Thus,
for each . I wrote it like that because the smaller is, the larger the damage one expects the measures to cause. Thus, the points form a descending sequence. (We can assume this, since if one measure causes both more damage and a higher growth rate than another, then there can be no reason to choose it.) Thus, 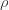 will be positive, and since at least some are positive, and no measures will cause a negative amount of damage,
will be positive, and since at least some are positive, and no measures will cause a negative amount of damage,  is positive as well.
is positive as well.
The converse of this statement is true as well. If for every , then 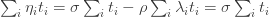 , from which it follows that the average damage across the cycle is , regardless of which measures are taken for which lengths of time.
, from which it follows that the average damage across the cycle is , regardless of which measures are taken for which lengths of time.
This already shows that there is nothing to be gained from having more than one measure for the relaxation phase and one for the lockdown phase. There remains the question of how to choose the best pair of measures.
To answer it, we can plot the points 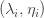 . The relaxation points will appear to the right of the y-axis and the suppression points will appear to the left. If we choose one point from each side, then they lie in some line
. The relaxation points will appear to the right of the y-axis and the suppression points will appear to the left. If we choose one point from each side, then they lie in some line 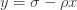 , of which is the intercept. Since is the average damage, which we are trying to minimize, we see that our aim is to find a line segment joining a point on the left-hand side to a point on the right-hand side, and we want it to cross the y-axis as low as possible.
, of which is the intercept. Since is the average damage, which we are trying to minimize, we see that our aim is to find a line segment joining a point on the left-hand side to a point on the right-hand side, and we want it to cross the y-axis as low as possible.
It is not hard to check that the intercept of the line joining 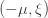 to
to 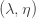 is at
is at 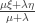 . So if we rename the points to the left of the y-axis
. So if we rename the points to the left of the y-axis 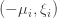 and the points to the right
and the points to the right 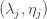 , then we want to minimize
, then we want to minimize 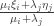 over all
over all 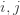 .
.
Can we describe the best choice in a less formal way?
It isn’t completely easy to convert this criterion into a rule of thumb for how best to choose two measures, one for the relaxation phase and one for the suppression phase, but we can draw a couple of conclusions from it.
For example, suppose that for the suppression measures there is a choice between two measures, one of which works twice as quickly as the other but causes twice as much damage per unit time. Then the corresponding two points lie on a line with negative gradient that goes through the origin, and therefore lies below all points in the positive quadrant. From this it follows that the slower but less damaging measure is better. Another way of seeing that is that with the more severe measure the total damage during the lockdown phase stays the same, as does the total damage during the relaxation phase, but the length of the cycle is decreased, so the average damage is increased.
Note that I am not saying that one should always go for less severe measures — I made the strong assumption there that the two points lay in a line through the origin. If we can choose a measure that causes damage at double the rate but acts three times as quickly as another measure, then it may turn out to be better than the less damaging but slower measure.
However, it seems plausible that the set of points will exhibit a certain amount of convexity. That is because if you want to reduce the growth rate of infections, then at first there will be some low-hanging fruit — for example, it is not costly at all to run a public-information campaign to persuade people to wash their hands more frequently, and that can make quite a big difference — but the more you continue, the more difficult making a significant difference becomes, and you have to wheel out much more damaging measures such as school closures.
If the points were to lie on a convex curve (and I’m definitely not claiming this, but just saying that something like it could perhaps be true), then the best pair of points would be the ones that are nearest to the y-axis on either side. This would say that the best strategy is to alternate between a set of measures that allows the disease to grow rather slowly and a set of measures that causes it to decay slowly again.
This last conclusion points up another defect in the model, which is the assumption that a given set of measures causes damage at a constant rate. For some measures, this is not very realistic: for example, even in normal times schools alternate between periods of being closed and periods of being open (though not necessarily to a coronavirus-dictated timetable of course), so one might expect the damage from schools being 100% closed to be more than twice the damage from schools being closed half the time. More generally, it might well be better to rotate between two or three measures that all cause roughly the same rate of damage, but in different ways, so as to spread out the damage and try to avoid reaching the point where the rate of one kind of damage goes up.
Summary of conclusions.
Again I want to stress that these conclusions are all quite tentative, and should certainly not be taken as a guide to policy without more thought and more sophisticated modelling. However, they do at least suggest that certain policies ought not to be ruled out without a good reason.
If adaptive triggering is going to be applied, then the following are the policies that the above analysis suggests. First, here is a quick reminder that I use the word “measure” as shorthand for “set of measures”. So for example “Encourage social distancing and close all schools, pubs, restaurants, theatres, and cinemas” would be a possible measure.
There is nothing to lose and plenty to gain by making the triggers (that is, the infection rates that cause one to switch from relaxation to suppression and back again) low. This has the consequence that the triggers should be set in such a way that the damage from the measures is significantly higher than the damage caused by the disease. This sounds paradoxical, but the alternative is to make the disease worse without making the cure any less bad, and there is no point in doing that.
Within reason, the cycles should be kept short.
There is no point in having more than one measure for the relaxation phase and one for the suppression phase.
If you must have more than one measure for each phase, then during the relaxation phase the measures should get more relaxed each time they change, and during the suppression phase they should get less strict each time they change.
Given enough information about their consequences, the optimal measures can be determined quite easily, but doing the calculation in practice, especially in the presence of significant uncertainties, could be quite delicate.
Point number 1 above seems to me to be quite a strong argument in favour of the hammer-and-dance approach. That is because the conclusion, which looks to me quite robust to changes in the model, is that the triggers should be set very low. But if they are set very low, then it is highly unlikely that the enormous damage caused by school closures, lockdowns etc. is the best approach for dealing with the cases that arise, since widespread testing and quarantining of people who test positive, contacts of those people, people who arrive from certain other countries, and so on, will probably be far less damaging, even if they are costly to do well. So I regard point number 1 as a sort of reductio ad absurdum of the adaptive-triggering approach.
Point number 2 seems quite robust as well, but I think the model breaks down on small timescales (for reasons I haven’t properly understood), so one shouldn’t conclude from it that the cycles should be short on a timescale of days. That is what is meant by “within reason”. But they should be as short as possible provided that they are long enough for the dominant behaviour of the infection rate to be exponential growth and decay. (That does not imply that they should not be shorter than this — just that one cannot reach that conclusion without a more sophisticated model. But it seems highly likely that there is a minimum “reasonable” length for a cycle: this is something I’d be very interested to understand better.)
Point number 3 was a clear consequence of the simple model (though it depended on taking 1 seriously enough that the damage from the disease could be ignored), but may well not be a sensible conclusion in reality, since the assumption that each measure causes damage at a rate that does not change over time is highly questionable, and dropping that assumption could make quite a big difference. Nevertheless, it is interesting to see what the consequences of that assumption are.
Point number 4 seems to be another fairly robust conclusion. However, in the light of 3 one might hope that it would not need to be applied, except perhaps as part of a policy of “rotating” between various measures to spread the damage about more evenly.
It seems at least possible that the optimal adaptive-triggering policy, if one had a number of choices of measures, would be to choose one set that causes the infections to grow slowly and another that causes them to shrink slowly — in other words to fine tune the measures so as to keep the infection rate roughly constant (and small). Such fine tuning would be very dangerous to attempt now, given how much uncertainty we are facing, but could become more realistic after a few cycles, when we would start to have more information about the effects of various measures.
One final point is that throughout this discussion I have been assuming that the triggers would be based on the current rate of infection. In practice of course, this is hard to measure, which is presumably why the Imperial College paper used demand for intensive care beds instead. However, with enough data about the effects of various measures on the rate of spread of the virus, one would be less reliant on direct measurements, and could instead make inferences about the likely rate of infection given data collected over the previous few weeks. This seems better than using demand for ICU beds as a trigger, since that demand reflects the infection rate from some time earlier.
October 30, 2019
Advances in Combinatorics fully launched
It’s taken longer than we originally intended, but I am very happy to report that Advances in Combinatorics, a new arXiv overlay journal that is run along similar lines to Discrete Analysis, has just published its first five articles, with plenty more in the pipeline.
I am excited by the business model of the journal, which is that its very small running costs (like Discrete Analysis, it uses the Scholastica platform, which charges $10 per submission, as well as a fixed annual charge of $250, and there are a few other costs such as archiving articles with CLOCKSS and having DOIs) are being met, for the next five years in the first instance, by the library Queens University in Kingston Ontario, who are also providing us with very useful administrative support. My dream would be for other libraries to have the foresight to support similar ventures, since the potential for savings if the stranglehold of the big commercial publishers is broken is huge. I do not underestimate the obstacles, but for a long time I have felt that what we are waiting for is a tipping point, and even quite a small venture can in principle have a significant effect on when that tipping point occurs.
The aim of Advances in Combinatorics is to be a top specialist combinatorics journal. Information about the editorial board, the submission process, and of course the articles themselves, can all be found on the website. Like Discrete Analysis, the journal has Editorial Introductions to each article, with the aim of making the webpage informative and fun to browse. We will be grateful for any feedback, and even more grateful for support in the form of excellent combinatorics papers while we are still getting established.
A final remark is that although I have reached the limit of the number of journals of this type that I can be closely involved in, I would be delighted to hear from anybody who thinks that they can put together a high-quality editorial board in an area that does not have a suitable journal for people who want to publish good papers without supporting the big commercial publishers. I know people who can offer advice about suitable platforms, funding, and similar matters. It would be great if free-to-read free-to-publish journals could cover all of mathematics, but we are still a long way from that at the moment.
June 19, 2019
The fate of combinatorics at Strathclyde
I have just received an email from Sergey Kitaev, one of the three combinatorialists at Strathclyde. As in many universities, they belong not to the mathematics department but to the computer science department. Kitaev informs me that the administrators of that department, in their infinite wisdom, have decided that the future of the department is best served by axing discrete mathematics. I won’t write a long post about this, but instead refer you to a post by Peter Cameron that says everything I would want to say about the decision, and does so extremely cogently. I recommend that you read it if this kind of decision worries you.
May 21, 2019
Voting tactically in the EU elections
This post is addressed at anyone who is voting in Great Britain in the forthcoming elections to the European Parliament and whose principal aim is to maximize the number of MEPs from Remain-supporting parties, where those are deemed to be the Liberal Democrats, the Greens, Change UK, Plaid Cymru and the Scottish National Party. If you have other priorities, then the general principles laid out here may be helpful, but the examples of how to apply them will not necessarily be appropriate to your particular concerns.
What is the voting system?
The system used is called the d’Hondt system. The country is divided into a number of regions, and from each region several MEPs will be elected. You get one vote, and it is for a party rather than a single candidate. Once the votes are in, there are a couple of ways of thinking about how they translate into results. One that I like is to imagine that the parties have the option of assigning their votes to their candidates as they wish, and once the assignments have been made, the  candidates with the most votes get seats, where is the number of MEPs representing the given region.
candidates with the most votes get seats, where is the number of MEPs representing the given region.
For example, if there are three parties for four places, and their vote shares are 50%, 30% and 20%, then the first party will give 25% to two candidates and both will be elected. If the second party tries a similar trick, it will only get one candidate through because the 20% that goes to the third party is greater than the 15% going to the two candidates from the second party. So the result is two candidates for the first party, one for the second and one for the third.
If the vote shares had been 60%, 25% and 15%, then the first party could afford to split three ways and the result would be three seats for the first party and one for the second.
The way this is sometimes presented is as follows. Let’s go back to the first case. We take the three percentages, and for each one we write down the results of dividing it by 1, 2, 3, etc. That gives us the (approximate) numbers
50%, 25%, 17%, 13%, 10%, …
30%, 15%, 10%, 8%, 6%, …
20%, 10%, 7%, 5%, 3%, …
Looking at those numbers, we see that the biggest four are 50%, 25% from the top row, 30% from the second row, and 20% from the third row. So the first party gets two seats, the second party one and the third party one.
How does this affect how I should vote?
The answer to this question depends in peculiar ways on the polling in your region. Let’s take my region, Eastern England, as an example. This region gets seven MEPs, and the latest polls show these kinds of percentages.
Brexit Party 40%
Liberal Democrats 17%
Labour 15%
Greens 10%
Conservatives 9%
Change UK 4%
UKIP 2%
If the percentages stay as they are, then the threshold for an MEP is 10%. The Brexit Party gets four MEPs, and the Lib Dems, Labour and the Greens one each. But because the Brexit Party, the Greens and the Conservatives are all close to the 10% threshold, small swings can make a difference to which two out of the fourth Brexit Party candidate, the Green candidate, or the Conservative candidate gets left out. On the other hand, it would take a much bigger swing — of 3% or so — to give the second Lib Dem candidate a chance of being elected. So if your main concern is to maximize the number of Remain-supporting MEPs, you should support the Greens.
Yes, but what if everybody were to do that?
In principle that is an annoying problem with the d’Hondt system. But don’t worry — it just isn’t going to happen. Systematic tactical voting is at best a marginal phenomenon, but fortunately in this region a marginal phenomenon may be all it takes to make sure that the Green candidate gets elected.
Aren’t you being defeatist? What about trying to get two Lib Dems and one Green through?
This might conceivably be possible, but it would be difficult, and a risky strategy, since going for that could lead to just one Remain-supporting MEP. One possibility would be for Remain-leaning Labour voters to say to themselves “Well, we’re basically guaranteed an MEP, and I’d much prefer a Remain MEP to either the Conservatives or the Brexit Party, so I’ll vote Green or Lib Dem instead.” If that started showing up in polls, then one would be able to do a better risk assessment. But for now it looks better to make sure that the Green candidate gets through.
I’m not from the Eastern region. Where can I find out how to vote in my region?
There is a website called remainvoter.com that has done the analysis. The reason I am writing this post is that I have seen online that a lot of people are highly sceptical about their conclusions, so I wanted to explain the theory behind them (as far as I can guess it) so that you don’t have to take what they say on trust and can do the calculations for yourself.
Just to check, I’ll look at another region and see whether I end up with a recommendation that agrees with that of remainvoter.com.
In the South West, there are six MEPs. A recent poll shows the following percentages.
Brexit Party 42%
Lib Dem 20%
Green Party 12%
Conservatives 9%
Labour 8%
Change UK 4%
UKIP 3%
Dividing the Brexit Party vote by 3 gives 14% and dividing the Lib Dem vote by 2 gives 10%. So as things stand there would be three Brexit Party MEPs, two Lib Dem MEPs and one Green Party MEP.
This is a bit close for comfort, but the second Lib Dem candidate is in a more precarious position than the Green Party candidate, given that the Conservative candidate is on 9%. So it would make sense for a bit of Green Party support to transfer to the Lib Dems in order to be sure that the three Remain-supporting candidates that look like being elected in the south west really are.
Interestingly, remainvoter.com recommend supporting the Greens on the grounds that one Lib Dem MEP is bound to be elected. I’m not sure I understand this, since it seems very unlikely that the Lib Dems and the Greens won’t get at least two seats between them, so they might as well aim for three. Perhaps someone can enlighten me on this point. It could be that remainvoter.com is looking at different polls from the ones I’m looking at.
I’m slightly perturbed by that so I’ll pick another region and try the same exercise. Perhaps London would be a good one. Here we have the following percentages (plus a couple of smaller ones that won’t affect anything).
Liberal Democrats 24% (12%, 8%)
Brexit Party 21% (10.5%, 7%)
Labour 19% (9.5%, 6.3%)
Green Party 14% (7%)
Conservatives 10%
Change UK 6%
London has eight MEPs. Here I find it convenient to use the algorithm of dividing by 1,2,3 etc., which explains the percentages I’ve added in brackets. Taking the eight largest numbers we see that the current threshold to get an MEP is at 9.5%, so the Lib Dems get two, the Brexit party two, Labour two and the Greens and Conservatives one each.
Here it doesn’t look obvious how to vote tactically. Clearly not Green, since the Greens are squarely in the middle of the range between the threshold and twice the threshold. Probably not Lib Dem either (unless things change quite a bit) since they’re unlikely to go up as far as 28.5%. But getting Change UK up to 9.5% also looks pretty hard to me. Perhaps the least difficult of these difficult options is for the Green Party to donate about 3% of the vote and the Lib Dems another 2% to Change UK, which would allow them to overtake Labour. But I don’t see it happening.
And now to check my answer, so to speak. And it does indeed agree with the remainvoter.com recommendation. This looks to me like a case where if tactical voting were to be widely adopted, then it might just work to get another MEP, but if it were that widely adopted, one might have to start worrying about not overshooting and accidentally losing one of the other Remain MEPs. But that’s not likely to happen, and in fact I’d predict that in London Change UK will not get an MEP because not enough people will follow remainvoter.com’s recommendation.
This all seems horribly complicated. What should I do?
If you don’t want to bother to think about it, then just go to remainvoter.com and follow their recommendation. If you do want to think, then follow these simple (for a typical reader of this blog anyway) instructions.
1. Google polls for your region. (For example, you can scroll down to near the bottom of this page to find one set of polls.)
2. Find out how many MEPs your region gets. Let that number be .
3. For each percentage, divide it by 1, 2, 3 etc. until you reach a number that clearly won’t be in the top .
4. See what percentage, out of all those numbers, is the th largest.
5. Vote for a Remain party that is associated with a number that is close to the threshold if there is also a Brexit-supporting (or Brexit-fence-sitting) party with a number close to the threshold.
One can refine point 5 as follows, to cover the case when more than one Remain-supporting party has a number near the threshold. Suppose, for the sake of example, that the Brexit party is polling at 32%, the Lib Dems at 22%, the Greens at 11%, Labour at 18% and the Conservatives at 12%, and others 5%, in a region that gets five MEPs. Then carrying out step 3, we get
Brexit 32, 16, 10.6
Lib Dems 22, 11
Greens 11
Conservatives 12
Labour 18, 9
So as things stand the Brexit Party gets two MEPs, the Lib Dems one, Labour one and the Conservatives one. If you’re a Remain supporter who wants to vote tactically, then you’ll want to push one of the Lib Dems and the Greens over 12% to defeat the Conservative candidate. To do that, you’ll need either to increase the Green vote from 11% to 12% or to increase the Lib Dem vote from 22% to 24%. The latter is probably harder, so you should probably support the Greens.
A final word
I’m not writing this as an expert, so don’t assume that everything I’ve written is correct, especially given that I came to a different conclusion from remainvoter.com in the South West. If you think I’ve slipped up, then please let me know in the comments, and if I agree with you I’ll make changes. But bear in mind the premise with which I started. Of course there may well be reasons for not voting tactically, such as caring about issues other than Brexit. But this post is about what to do if Brexit is your overriding concern. And one obvious last point: PLEASE ACTUALLY BOTHER TO VOTE! Just the percentage of people voting for Remain-supporting parties will have an impact, even if Farage gets more MEPs.
December 22, 2018
How Craig Barton wishes he’d taught maths
A couple of months ago, I can’t remember precisely how, I became aware of a book called How I Wish I’d Taught Maths, by Craig Barton, that seemed to be highly thought of. The basic idea was that Craig Barton is an experienced, and by the sound of things very good, maths teacher who used to take a number of aspects of teaching for granted, until he looked into the mathematics-education literature and came to realize that many of his cherished beliefs were completely wrong. Since I’ve always been interested in the question of how best to teach mathematics, both because of my own university teaching and because from time to time I like to pontificate about school-level teaching, I decided to order the book. More surprisingly, given my past history of buying books that I felt I ought to read, I read it from cover to cover, all 450 pages of it.
As it happens, the book is ideally designed for people who don’t necessarily want to read it from cover to cover, because it is arranged as follows. At the top level it is divided into chapters. Each chapter starts with a small introduction and thereafter is divided into sections. And each section has precisely the same organization: it is divided into subsections entitled, “What I used to believe”, “Sources of inspiration”, “My takeaway”, and “What I do now”. These are reasonably self-explanatory, but just to spell it out, the first subsection sets out a plausible belief that Craig Barton used to have about good teaching practice, often ending with a rhetorical question such as “What could possibly be wrong with that?”, the second is a list of references (none of which I have yet followed up, but some of them look very interesting), the third is a discussion of what he learned from the references, and the last one is about how he put that into practice. Also, each chapter ends with a short subsection entitled “If I only remember three things …”, where he gives three sentences that sum up what he thinks is most important in the chapter.
One question I had in the back of my mind when reading the book was whether any of it applied to teaching at university level. I’m still not sure what I think about that. There is a reason to think not, because the focus of the book is very much on school-level teaching, and many of the challenges that arise do not have obvious analogues at university level. For example, he mentioned (on page 235) the following fascinating experiment, where people were asked to do the following multiple-choice question and then justify their answers.
Which of these values could not represent a probability?
A. 2/3
B. 0.72315
C. 1.46
D. 0.002
Let me quote the book itself for a discussion of this question.
Surely the rule probabilities must be less than or equal to 1 is about as straightforward as it gets in maths? But why, then, did 47% of the 5000+ students who answered this question get it wrong?
A few students’ explanations reveal all:
I think B because it’s just a massive decimal and the rest look pretty legit. I also don’t see how a number that big could be correct.
I think B because you wouldn’t see this in probability questions.
I think D because you can’t have 0.002 as an answer because it is too low.
If students are only used to meeting `nice-looking’ probabilities during examples and practice questions, then it is little surprise they come a cropper when they encounter strange-looking answers.
Could one devise a university-level question that would catch a significant proportion of people out in a similar way? I’m not sure, but here’s an attempt.
Which of the following is not a vector space with the obvious notions of addition and scalar multiplication?
A. The set of all complex numbers.
B. The set of all functions from 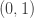 to
to  that are twice differentiable.
that are twice differentiable.
C. The set of all polynomials in  with real coefficients that have
with real coefficients that have 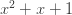 as a factor.
as a factor.
D. The set of all triples 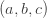 of integers.
of integers.
E. The set of all sequences 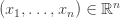 such that
such that 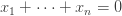 and
and  .
.
I think at Cambridge almost everyone would get this question right (though I’d love to do the experiment). But Cambridge mathematics undergraduates have been selected specifically to study mathematics. Perhaps at a US university, before people have chosen their majors, people might be tempted to choose another option (such as B, because vector spaces are to do with algebra and not calculus), while not noting that the obvious scalars in D do not form a field. Or perhaps they wouldn’t like A because the scalar field is the same as the set of vectors (unless, that is, they thought that the obvious scalars were the real numbers).
More generally, I feel that there are certain kinds of mistakes that are commonly made at school level that are much less common at university level simply because those who survive long enough to reach that stage have been trained not to make them. For example, at university level we become used to formal definitions. Once one is in the habit of using these, deciding whether a structure is a vector space is simply a question of seeing whether the definition of a vector space applies, rather than thinking “Hmm, does that look like the vector spaces I’ve met up to now?” We also become part of a culture where it is common to look at pathological, or at least slightly surprising, examples of concepts, and so on.
Another reason I decided to read the book was that I have certain prejudices about the teaching of mathematics at school level and I was interested to know whether they would be reinforced by the book or challenged by it. This was a win-win situation, since it is always nice to have one’s prejudices confirmed, but also rather exhilarating to find out that something that seems obviously correct is in fact wrong.
A prejudice that was strongly confirmed was the value of mathematical fluency. Barton says, and I agree with him (and suggested something like it in my book Mathematics, A Very Short Introduction) that it is often a good idea to teach fluency first and understanding later. More precisely, in order to decide whether it is a good idea, one should assess (i) how difficult it is to give an explanation of why some procedure works and (ii) how difficult it is to learn how to apply the procedure without understanding why it works.
For instance, suppose you want to teach multiplication of negative numbers. The rule “If they have the same sign then the answer is positive, and if they have different signs then the answer is negative” is a short and straightforward rule, but explaining why -2 times -3 should equal 6 is not very straightforward. So if one begins with the explanation, there is a big risk of conveying the idea that multiplication of negative numbers is a difficult, complicated topic, whereas if one gives plenty of practice in applying the simple rules, then one gives one’s students fluency in an operation that comes up in many other contexts (such as, for instance, multiplying  by
by  ), and one can try to justify the rule later, when they are comfortable with the rule itself. I remember enjoying the challenge of thinking about why the rule for dividing one fraction by another was correct, but that was long after I was happy with using the rule itself. I don’t remember being bothered by the lack of justification up to that point.
), and one can try to justify the rule later, when they are comfortable with the rule itself. I remember enjoying the challenge of thinking about why the rule for dividing one fraction by another was correct, but that was long after I was happy with using the rule itself. I don’t remember being bothered by the lack of justification up to that point.
As an example in the other direction, Barton gives that of solving linear equations. The danger here is that one can learn a procedure for solving equations such as 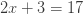 , get good at it, and then be completely stuck when faced with an equation such as
, get good at it, and then be completely stuck when faced with an equation such as 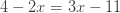 . Here a bit of understanding can greatly help. Barton advocates something called the balance method, where one imagines both sides of the equation on a balance, and one is required to make sure that balance is maintained the whole time. I think (but without too much confidence after reading this book) that I would go for something roughly equivalent, but not quite the same, which is to stress the rule you can do the same thing to both sides of an equation (worrying about things like squaring both sides or multiplying by zero later). Then the problem of solving linear equations would be reduced to a kind of puzzle: what can we do to both sides of this equation to make the whole thing look simpler?
. Here a bit of understanding can greatly help. Barton advocates something called the balance method, where one imagines both sides of the equation on a balance, and one is required to make sure that balance is maintained the whole time. I think (but without too much confidence after reading this book) that I would go for something roughly equivalent, but not quite the same, which is to stress the rule you can do the same thing to both sides of an equation (worrying about things like squaring both sides or multiplying by zero later). Then the problem of solving linear equations would be reduced to a kind of puzzle: what can we do to both sides of this equation to make the whole thing look simpler?
That last question is related to another fascinating nugget that is mentioned in the book. Barton gives an example of a question concerning a parallelogram ABCD, where the angle at A is 105 degrees. The line BC is extended to a point E, which is then joined by an additional line segment to D, and the angle CED is 30 degrees. The question is to prove that the triangle CED is isosceles.
Apparently, this question is found hard, because one cannot achieve the goal in one step. Instead, one must observe that the angle of the parallelogram at C is also 105 degrees, from which it follows that the angle ECD is 75 degrees. And from that it follows that the angle EDC is 75 degrees as well, and the problem is solved.
But the interesting thing is that if you change the question to the more open-ended question, “Fill in as many angles in this diagram as you can,” then many people who found the goal-oriented version too hard have no difficulty in filling out all the angles in the diagram and therefore noticing that the triangle CED is isosceles.
The lesson I would draw from this with the equations question is that instead of asking for a solution to the equation , it might be better to ask “See whether you can make the equation look simpler by doing something to both sides. If you manage, see if you can then make it even simpler. Keep going until you have made it as simple as you can.” This would of course come after they had already seen several examples of the kind of thing one can do to both sides of an equation.
Barton isn’t content with just telling the reader that certain methods of teaching are better than others: he also tells us the theory behind them. Of particular importance, he claims, is the fact that we cannot hold very much in our short-term memory. This was music to my ears, as it has long been a belief of mine that the limited capacity of our short-term memory is a hugely important part of the answer to the question of why mathematics looks as it does, by which I mean why, out of all the well-formed mathematical statements one could produce, the ones we find interesting are those particular ones. I have even written about this (in an article entitled Mathematics, Memory and Mental Arithmetic, which unfortunately appeared in a book and is not available online, but I might try to do something about that at some point).
This basic point informs a lot of the discussion in the book. Consider, for example, a question that asked you to find the perimeter of a rectangle that had side lengths 2/3 and 3/5. This could be a great question, but it is very important to ask it at the right point in the students’ development. If you ask it before they are fluent at adding fractions and at working out perimeters of rectangles, then the amount they have to hold in their heads may well exceed their cognitive capacity: they need to store the fact that you have to add the two lengths, and multiply by 2, and put both fractions over a common denominator. It is to avoid this kind of strain that attaining fluency is so important: it literally makes it easier to think, and in particular to solve the kind of interesting problems we would all like them to be able to solve. Barton absolutely doesn’t dispute the value of interesting problems that mix different parts of mathematics — he just argues, very convincingly, that one has to be careful when to introduce them.
An idea he discusses a lot, and that I think might perhaps have a role to play in university-level teaching, is what he calls diagnostic questions, and in particular low-stakes diagnostic tests. These typically take the form of a short multiple-choice quiz, and he tries very hard to create a classroom culture where people understand that the purpose of the quiz is not assessment — the quizzes do not “count” for anything — but a tool to help learning, and in particular to help diagnose problems with understanding.
What makes these questions “diagnostic” is that they are carefully designed in such a way that if you have a certain misconception, then you will be drawn towards a certain wrong answer. That is, the wrong answers people give are informative for the teacher, rather than merely wrong. Here, for example, is a question that fails to be diagnostic followed by a modified version that succeeds.
A triangle has one side of length 6 and two sides of length 5. What is its area?
A. 8
B. 11
C. 12
D. 15
E. 20
A. 6
B. 12
C. 15
D. 16
E. 24
F. 30
With the second set of choices, each answer has a potential route that one can imagine somebody taking. To obtain the answer 6, one chops the triangle into two right-angled triangles, each of height 4 and base 3, calculates the area of one of them, and forgets to double it. The correct answer is 12. To obtain 15, one takes the formula “half the height times the base” but substitutes in 5 for the height. To obtain 16 one calculates the perimeter. To obtain the answer 24 one takes the height times the base. And to obtain the answer 30 one multiplies the two numbers 6 and 5 together (on the grounds that “to calculate the area you multiply the two numbers together”). Thus, wrong answers yield useful information. With the first set of answers, that just isn’t the case — they are much more likely to be the result of pure guesswork.
It’s worth mentioning that Terence Tao has created a number of multiple-choice quizzes on university-level topics. He has also blogged about it here. They are not exactly diagnostic in the sense Barton is talking about, but one could imagine trying to make them so.
Barton uses these diagnostic tests to get a much clearer picture of what his class already understands, before he launches into the discussion of some new topic, than he would by simply asking questions to the class and getting answers from a few keen students. If he diagnoses a fairly serious collective misunderstanding, then he will spend time dealing with that, rather than pointlessly trying to build on shaky foundations.
I’m jumping around a bit here, but a semi-counterintuitive idea that he advocates, which is apparently backed up by serious research, is what he calls pretesting. This means testing people on material that they have not yet been taught. As long as this is done carefully, so that it doesn’t put students off completely, this turns out to be very valuable, because it prepares the brain to be receptive to the idea that will help to solve that pesky problem. And indeed, after a moment of getting used to the idea, I found it not counterintuitive at all. In fact, it resonates very strongly with my experience as a research mathematician: I find reading other people’s papers very difficult as a rule, but if they can help me solve a problem I’m working on, a lot of that difficulty seems to melt away, because I know exactly what I want, and am looking out for the key idea that will give it to me.
There’s a great section on the use of artificial “real-world” problems. I think he would agree with me about Use of Maths A-level. As someone he quotes says, “Students are constantly on their guard against being conned into being interested.” An example he discusses is
Alan drinks 5/8 of a pint of beer. What fraction of his drink is left?
If the entire point of the exercise is to gain fluency with subtracting fractions, then he advocates just cutting the crap and asking them to calculate 1-5/8, which I agree with 100%.
If, on the other hand, it is intended as an exercise in stripping away the unnecessary real-world stuff and getting at the underlying mathematics, then he has interesting things to say (later in the book than this section) about the relationship between what he calls the surface structure and the deep structure. The former is to do with the elements of the question that present themselves directly to the student — in this case Alan and the beer — while the deep structure is more like the underlying mathematical question. To train people to uncover the deep structure, it is very important to give them pairs of questions with the same surface structure and different deep structures, and vice versa. Otherwise, they may learn a procedure that works for lots of similar examples and lets them down as soon as a new example comes along with a different deep structure.
There is lots more in the book — obviously, given its length — but I hope this conveys some of its flavour. The only negative thing I can think of to say is that the word “flipping” is overused — the sentence “Teaching is flipping hard” occurs several times, when once would be enough for one book. But if you’re ready for a bit of jocularity of that kind, then I recommend it, as I found it highly thought provoking. I don’t yet know what the result of that provocation will be, but I’m pretty sure there will be one.
Timothy Gowers's Blog

- Timothy Gowers's profile
- 88 followers

