
Ethan Zuckerman's Blog
March 31, 2026
Recent Writing, as of March 2026
I write a monthly column for Prospect Magazine in the UK, covering the social implications of information technology. This month’s column is about how AI has been transforming programming, and how as an educator, I am worried about our ability to keep teaching “computational thinking”, something that’s essential for keeping AIs from going off the rails and doing dumb stuff very rapidly:
My columns at Prospect since December 2021 – there’s a lot of them!
Ryan McGrady and I just published a paper I am extremely proud of in the International Journal of Communication. It’s called “The Quotidian Web and the Accidental Archive” and it’s based on our explorations of a data set we created by taking a random sample of YouTube, as we described in JOQD a few years back.

An “accidental archive” photo from an unknown Hungarian photographer, mid 1980s
While you can describe YouTube as a whole through statistics, numbers don’t really capture the distinctive weirdness of low-view YouTube videos. They tend to be slices of life from around the world, glimpses into people’s homes, cars, habits and obsessions. Ryan and I started thinking of these videos collectively as a strange sort of archive, an “accidental archive”. There are other accidental archives in history, when a place is abandoned due to natural disaster or when unsorted and unedited media ends up preserved. Ryan and I write about a remarkable archive of photos from Hungary in the 1980s, and about what archeologists continue to learn from Pompeii, as well as making a case for preserving a random slice of YouTube so we can learn from it in the future.
Closely related is a paper we published last summer, along with Kevin Zheng, who developed your YouTube sampling strategy. It’s called “One Platform, Four Languages: Comparing English, Spanish, Hindi, and Russian YouTube”, and it suggests that Hindi speakers are using the YouTube platform in a substantially different way than speakers of these three other languages. Specifically, Hindi speakers get fewer views on their videos, and more interaction – this suggests that they’re not using YouTube to broadcast themselves to large audiences, but instead sharing moments with friends and family, an idea that we’re exploring in detail through ethnography and content analysis with collaborators versed in the language and culture – we hope to have a follow-up paper later this year.
Kevin, who co-authored the Four Language paper, started working with me as an undergrad. One of the things I’m proudest of at UMass is that much of the work I’m proudest of has been coauthored with undergrads. A good example is “Improving Social Media with Middleware”, which Isaac Brickman and I wrote together for Annals of the American Academy of Political and Social Science, based on research for his UMass senior honors thesis. I spoke about middleware in DC last week at the National Press Club and virtually all the examples I used came from Isaac’s research.
More to come: there’s several other papers under review right now… as well as the usual crop of writing I’m excited about that’s gotten rejected and I have to figure out where to send it next!
The post Recent Writing, as of March 2026 appeared first on Ethan Zuckerman.


March 24, 2026
Howard French: The Second Emancipation
Howard French is one of the leading journalists and thinkers about Africa’s role in the world, and the attention the world does and doesn’t pay to the continent’s people and potential. He’s also a UMass Amherst graduate, and is on campus this week, talking about his new book, “The Second Emancipation”, about pan-Africanism, Kwame Nkrumah and “global blackness at high tide.”
French now teaches at the Columbia Journalism School, and was previously bureau chief for the New York Times in Central America and the Caribbean, Japan, China and West and Central Africa at different times. He’s written five books about Africa, one of which looks at China’s influence on the continent, and is also an accomplished photographer, publishing a lovely book on the changes taking place in the city of Shanghai.
Howard starts his remarks by reminiscing about his student days at UMass in the 1970s, from his dissolute first year, to discovering an identity as a scholar in subsequent years. Part of his time at UMass was the Five College experience, the opportunity to study at Hampshire, Smith, Mt. Holyoke and Amherst College, as well as at UMass.

Howard French speaking at UMass Amherst
Pivoting towards his subject – Africa’s role in the world – he hails back to his previous book, “Born in Blackness”, which makes an argument for Africa as a central actor in global history from the Age of Exploration onwards. Contrary to how we are usually taught world history, Africa was a prime mover, not an “obstacle to be overcome”.
We are usually taught that Africa was the continent Europeans were trying to get around to get to Asia. But in writing about Asia, he found accounts from Portuguese explorers in which they name the Portuguese treasury “the House of Africa” and referring to Africa as “the New World”. There is a 50 to 75 year period of history where great explorers are establishing trade routes – not for slaves, but for gold – to Africa before building routes to Asia or the Americas.
Born in Blackness ends at the Second World War, and Howard was looking for an entry point into a subsequent book. His long-time editor suggested that a biography of Kwame Nkrumah, Ghana’s first post-colonial leader, would be a path forward. Howard was resistant: there’s piles of literature about Nkrumah and Ghana, but he wasn’t sure the world needed a new book on the topic.
Howard traces pan-Africanism backward from Nkrumah through Marcus Garvey towards freed slaves in the US in the 1700s. The ideas of Panafricanism are found around the Atlantic rim from not long after the advent of the trans-Atlantic trade in enslaved people. The core idea of panafricanism, which French brings back to a formerly enslaved man, David Walker, in the early 19th century is that Africa must unite to be able to compete with other nations and groups.
French asks whether Europeans do not also have a “fellow feeling”, a common identity as Europeans? One of the European projects, unfortunately, was the colonial carving up of Africa into individual European territories. So overfocusing on Panafricanism as a racial project misunderstands these dynamics of identity and power.
Joseph Ephraim Casely Hayford, a journalist from the Fante Gold Coast, is one of French’s characters “paving the way” for Nkrumah, writing about African governance traditions and the ways in which they might provide governance systems going forward. His book, “Ethiopia Unbound”, is arguably the first Panafrican novel, and his story is part of the first act of French’s book, which outlines a global pre-history of Panafricanism.
The second act of the book looks at the ways in which Africans (including African Americans) were actors on a world stage through the 20th century. He speaks movingly about “the fight to fight”, the struggles African Americans had to go through to demonstrate they could fight with valor for their country. The same sentiment applies to colonized people on the African continent – people living in a post-slavery world are experiencing “a halfway house out of slavery”, due to regimes of forced labor. Africans were “obliged” to work without wages and experience corporal punishments in systems that persist until the middle of the 20th century. And yet Africans are brave participants in the World Wars on the sides of their colonizers, seeing military service as a path towards respect and rights.
There was a logic to this, French explains: these Africans were told that WWII was a battle for freedom and democracy. The right to self-government and self-determination seemed deeply connected to the struggles against fascism and Nazism. Ghanaians – who played a decisive role in the victory over Japan in Burma – expected that their service in defending their colonizer would be a key step in achieving their dignity and rights. Returning to the Gold Coast at the end of WWII, they properly expected to be recognized as heroes, and instead, found the British reneging on promises for improved healthcare, education and renumeration.
In addition to mistreatment of veterans, Britain is siphoning resources from its colonies to rebuild their domestic economy, which has been shattered from the war, leading to incredible inflation in Gold Coast. Anger over the mistreatment of Gold Coast veterans turns into a protest movement. Veterans march on Osu Castle, the seat of colonial government, and are fired on by British troops. Nkrumah, who is not in the protests, rushes back to Accra to take up leadership.
Nkrumah is an unlikely leader – he’s from the far southwest, from a small ethnic group (the Nzema), and he’s a child of a “junior wife”, which means he’s less likely to get support from his polygamist father. But his mother advocates for him, and he gets sent to an elementary school… which he hates. His mother forces him to attend, and he eventually becomes a promising scholar.
His success in elementary school leads him to be sent to Achimota College, the best secondary school in the country. There he meets a faculty member who’s been to school in the US. There’s another key figure – the editor of an activist newspaper who will go on to become the first president of an independent Nigeria – who has also been schooled in the US, and both preach visions of Panafricanism to the young Nkrumah. Instead of going to the UK – as most Gold Coast students would have – Nkrumah goes to New York and “discovers blackness”.
There’s nothing special about being Black in the Gold Coast, French explains. But arriving in Harlem in 1935, Nkrumah encounters countless advocates of Black nationalism, and is brought to an Abyssinian Baptist service by a Dutch friend. He spends several days in Harlem before going on to Lincoln University in Pennsylvania, where he has been admitted, but does not have school fees. He pays his way through school, writing papers for other students, and makes additional funds by preaching in Methodist and Baptist churches, giving guest sermons.
He is drawn to Howard University in Washington DC, which is the citadel of African American intellectual life at that point. He never is a student there, but rubs shoulders with Charles Hamilton Houston, James Nesbitt, E Franklin Frasier, Charles Wesley, Zora Neale Hurston and others. “In each of these names, you can find a fragment of the Panafrican idea,” French argues. In the decade (1935-1945) Nkrumah spends in the US – getting four degrees along the way – Nkrumah becomes a committed Panafricanist, and is introduced to George Padmore, the successor to WEB DuBois in convening a global Panafrican conference.
Nkrumah, in essence, is recruited by the global Panafrican movement as someone who can actually talk to Africans, not just to Africans in the diaspora who’ve learned primarily to talk to British and American people. He gets arrested as part of the veterans movement. He runs for office from jail and wins a series of elections that eventually force the British to acknowledge him as the representative of Ghanaians. Eventually, he is the leader of the country when Ghana gains independence in 1957.
Ghana’s independence becomes a cause celebre for Black activists in the US, and Nkrumah emerges as an international inspiration for civil rights activsts. JFK is inspired by Nkrumah, and mentions Africa numerous times in his campaign for US president – we have forgotten a historical moment in which Nkrumah is the first foreign leader invited to Kenney’s White House.
Independence is not just symbolic – it is the springboard for independence movements across the continent. And Nkrumah’s vision shapes the politics of the nation and the continent. Kennedy wanted Nkrumah to help the US win the Cold War in Africa… though there really was no Cold War in Africa at that point. Nkrumah wanted Kennedy to loan Ghana money to build a massive dam in the Volta region and industrialize the nation. Kennedy wanted to do it, but his advisors resisted, and LBJ had no interest in Nkrumah or Africa. Nkrumah was overthrown in 1966, probably with a hand from the CIA, and the Panafrican dream is forced to take a back seat.
The post Howard French: The Second Emancipation appeared first on Ethan Zuckerman.
January 21, 2026
“Where Should We Live” – a new class on cities, migration and climate change
I’m teaching two classes at UMass Amherst this spring. One is the latest incarnation of my “Fixing Social Media” class, which I launched late in my time at MIT and brought with me to UMass. It’s becoming “Fixing Platform Power” as we’re expanding our focus from social media to include AI chatbots and generative tools.
The second one is brand new: it’s a seminar about housing in the US, with a focus on climate change. It’s called “Where Should We Live?” and it’s a chance for me to try and combine some threads I’ve been working on for the past several years. I’m interested in how Americans have been moving South and West for decades, towards cheaper housing and job opportunities, but also towards heat, water shortages, hurricanes and wildfires. Some of America’s most popular cities are becoming transformed by climate change – will we see a reverse migration to the Great Lakes and a repopulation of the Rust Belt? Or will how we live change more than where we live?
I’ve been researching a book for some years now about the Rustbelt and “legacy cities” of the Northeast and Great Lakes, exploring my conviction that this part of the US is undervalued and underappreciated… but I’ve also learned that a strong intuition and a lot of reading is not the same thing as a book project. I’m teaching this class to get some feedback about what questions and possible solutions resonate with my students, and also to see how it feels to make some of these arguments out loud.
Here’s the syllabus as it currently stands – I’d love thoughts and input, with the caveat that there’s a reason (discussed below) why it needs to be light on reading.
Honors seminar: Where Should We Live?
It’s really hard to afford a place to live in the United States.
Housing stress is the idea that one can be under financial stress from housing prices if the cost of rent or a mortgage is more than 30% of a family’s income, and under extreme housing stress if those costs are more than 50% of income. 31.3% of American households are housing stressed, and almost half of renting households (49.7%) spend 30% or more on housing.
(Massachusetts does badly according to these numbers – we and Connecticut have a lot of stressed renters, though the problem is concentrated in the south and west – California is the worst, followed by Arizona, Texas, Florida, Georgia and others.)
Housing stress is most severe for folks who’ve got low incomes. The New York Times recently reported a profile of Junior Estrada, a minimum wage worker who lives in Los Angeles, where it would require 98 hours a week of minimum wage work to afford a $2100/mo one bedroom apartment. So he lives in a $750/mo storage unit without water or electricity.
Why is housing in the US so unaffordable? The three most common answers are interrelated: interest rates, a post-2008 construction gap and overregulation… or the perception of overregulation.
Before the 2008 financial crash, builders started construction on roughly 2 million housing units a year. That crashed to just over half a million a year in 2009, and as of last year, it had only recovered to 1.35 million a year. As a result, there’s a shortage of millions of homes in the US right now – Zillow estimates that number at 4.7 million.
It’s going to take at least a decade to clear that housing shortfall – there just aren’t enough builders in America to build all the houses we need. (And Trump’s crackdown on immigration is especially hurting the building trades, and tariffs with Canada are making construction materials more expensive – if you wanted to increase housing costs, those two policies would be a good way to do so.) The lack of supply increases housing costs, as does the cost of borrowing money – interest rates are roughly twice as high now as they were immediately after the pandemic. Combine the increased house price with the increased borrowing cost and in some markets, it costs as much as twice as much to buy a house as it did before COVID. Interest rates contribute to a “lock in” effect – if you have a house with a 3% mortgate, it would take a LOT to get you to sell that house, since you’re going to face a 7% rate on the new house.
There’s a set of commentators who argue that the main barrier to housing construction is overregulation, pointing to expensive and highly regulated cities (Los Angeles, San Francisco, New York) as evidence that cities should adopt looser regulations to encourage housing growth. While deregulation is a popular argument for conservative policymakers, the facts on the ground are more complex than that model – many places where housebuilding is only lightly regulated have low construction costs, but also shrinking populations. In other words, it’s possible to be lightly regulated, cheap and still not a popular destination for new homebuyers – think upstate New York, St. Louis MO or much of the rustbelt. “Superstar” cities like New York, Los Angeles and San Francisco may face a double whammy: they have low supply as well as regulations that make it hard to build.
Assume for the moment that policymakers magically do all the right things: they rezone to allow higher density, they create accommodations for ADUs, they subsidize low-income housing. (Or, if you lean to the right, imagine they reduce regulations, cut interest rates and require only market-rate construction.) There’s still a giant problem looming on the horizon from climate change.
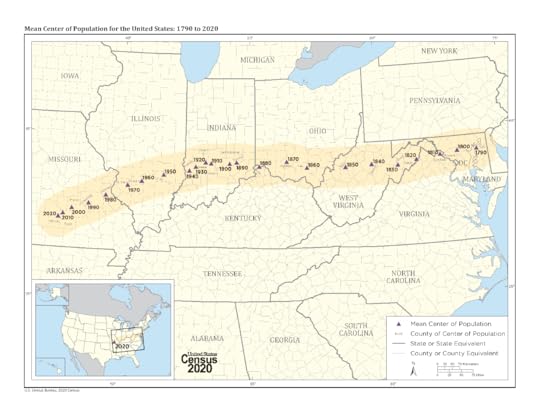
Since its inception, the United States has spread south and west. For the 19th century, the idea of “manifest destiny” powered expansion, providing an ideological framework of white, Christian supremacy to justify the ethnic cleansing of native Americans and the purchase of territory from France and Spain. There were complex layers of financial and ideological motivations at work, from the ways the railroads opened the west to the annexation of Texas as a slave state. Horace Greeley of the New York Tribune urged young people to “Go West, young man, and grow up with the country”.
The World Wars slowed this expansion, as Americans flooded the factories of the northeast and midwest to build supplies the world’s military needed. After WWII, western states actively courted factories with promises of “business friendly” (i.e., anti-union) regulatory climates. Phoenix, followed by Houston and others, pioneered the idea of the “growth city”, with few zoning laws and few barriers to sprawling suburban development. What resulted was a radically different form of city than the metropolises of the Great Lakes: not only are “growth cities” like Houston, Phoenix or Jacksonville less dense than cities like Chicago or Detroit at their peak population, they are less dense than Detroit now, after it lost two thirds of its population from its peak in 1950s. These cities are organized around cars, not public transit, and around detached homes in suburban enclaves. And LOTS of them are in areas that are vulnerable to climate change.
Wildfires in California have been especially destructive because people have been moving to the “wildland urban interface”, a place where human dwellings are starting to be built in previously unoccupied land. Wildfires that would have reshaped landscapes but not directly affected humans are now displacing tens of thousands of people… and almost 7 million Californians live in especially fire-vulnerable areas.
Other communities are being transformed by rising waters and by the risk of seasonal storms. Lake Charles, LA is shrinking due to residents fleeing damages from successive hurricanes and rainstorms, and federal and state officials are offering to buy properties most at threat for flooding, a program called “managed retreat”. The homeowner’s insurance market in Florida nearly collapsed due to risks from climate change, primarily hurricane risk. The governor is now luring insurers back by making it harder for homeowners to recover damages from their insurers.
Some risks are likely to affect the most vulnerable citizens first: extreme heat is survivable if you can afford air conditioning, but is leading to the deaths of homeless people and people who live in substandard housing like RVs in states like Arizona. In 2024, Phoenix experienced 113 consecutive days with temperatures of 100F or above, turning sectors of the population nocturnal: construction crews routinely work in the middle of the night, both because it’s safer for workers and because building materials like concrete cannot correctly cure in the heat.
Many US cities are less vulnerable to climate change. They include the “rustbelt” cities along the Great Lakes – Buffalo, Cleveland, Detroit, Milwaukee – which are blessed with ample fresh water, moderate summer temperatures and insulation from coastal storms. These cities are often dense and walkable, characteristics that are popular in European cities… but most of these cities are either losing population, or growing more slowly than cities to the South and West.
Climate change is gradual, and its effects on where we live are bound to be slow: people move to where jobs are available, to where houses are inexpensive and where they feel like they can live “the good life”. It’s easy to predict that cities like Duluth will eventually become the new Austin, but much harder to know when it might happen.
Will the American vision of “the good life” change as the climate changes? Will we see Americans turn from suburban sprawl to walkable density, or will rising heat send us further into our cars and homes and out of our communities? Will political forces like the Trump administration’s war on immigrants reshape cities like Minneapolis that have built identities around immigration?
The goal of our class is understanding what factors – economic, environmental, cultural – that shape where we live and help us understand how our country and the world might change in the next few decades… and how we might steer those changes.
Each week, students will post a question brought up by the readings, which we will use to shape class discussion. Students will write a final reflection paper of 5-7 pages, offering a prediction for what the most exciting cities for US college graduates to move to will be in 2050, based on the factors discussed in class.
(For my academic friends – if this and the readings seem light, it’s because this is an unusual class. It’s a one credit honors seminar – there will be fifteen students from majors ranging from chemistry to turf science to accounting. The goal is to create a common ground where everyone can meet for discussion – my big challenge is not over-assigning reading, and not dominating the discussions.)
Week 1: Meeting each other, discussing this blog post and questions of where we have lived and where we want to live.
Week 2: What if you can’t afford a place to live?
Rising home prices and rising inequality mean many Americans are homeless or have substandard housing, including those who work full time. We know that housing people is the best path towards addressing a variety of social problems – what do we do when millions of people can’t afford a place to live?
Required reading: “In L.A., $750 a Month to Live in a Backyard Storage Unit”, by Livia Albeck-Ripka (https://www.nytimes.com/2025/12/09/us...)
Optional reading: “The New American Homeless”, Brian Goldstone (https://newrepublic.com/article/15461...)
Week 3: How did we get here?
How did American houses become a vehicle for speculative investment? Who thought lending money to people without proof of income was a good idea? How did mortgage backed securities burn down the global financial system?
Required listening: Alex Blumberg, Adam Davidson and This American Life: “The Giant Pool of Money” – https://www.thisamericanlife.org/355/...
Week 4: Why is it so hard to build a house?
Unlike almost every aspect of American business, the construction industry isn’t getting more efficient. Why do Americans have such a hard time building houses, and what lessons might we take from Sweden or Singapore?
Required listening:
Stephen Dubner, “Why Is It So Hard (and Expensive) to Build Anything in America?”: https://freakonomics.com/podcast/why-...
Week 5: Why Are Americans Moving South and West?
Between 1910 and 1970, five million Black Americans moved from rural areas of the South to industrial centers of the North in a demographic shift called “The Great Migration”. Less discussed is the move of White Americans from these Northern cities south and west, to the Sunbelt. What caused this shift – which is still ongoing – and what does it mean for where and how we live?
Required reading: Katherine Jewell, “Rise of the Sunbelt South” (PDF)
Michael Hiltzig, “America’s decline in life expectancy speaks volumes about our problems”, https://www.latimes.com/business/stor...
Week 6: How is the climate changing where we can live?
Attributing specific fires, storms or hot days to climate change is a challenging task, but there is broad consensus that America is getting hotter, drier in some places, wetter in others, and more prone to catch fire. How is climate change likely to change where we want to live and where it’s safe to live?
Required reading: Abrahm Lustgarten, “Climate Change Will Force a New American Migration”, https://www.propublica.org/article/cl...
optional reading: Abrahm Lustgarten, “The Great Climate Migration”, https://www.nytimes.com/interactive/2...
Week 7: What happens when it’s too hot to go outside?
It’s so hot in Phoenix that the zoo opens at 6am, so visitors and the animals can go into air conditioned comfort by early afternoon. What happens to the unhoused and those in substandard housing in a city too hot to live in?
Required reading: Jeff Goodell, “Can We Survive Extreme Heat?”,
https://www.rollingstone.com/culture/...
“As Phoenix Heats Up, the Night Comes Alive”, Marguerite Holloway
https://www.nytimes.com/interactive/2...
Week 8: What if it’s time to leave?
Louisiana is shrinking as sea levels rise and more of the low-lying state ends up under water. St. Charles Parish is losing population rapidly… and those who want to stay are discovering the state and federal government would like them to move away, in a strategy called “managed retreat”.
Required listening: Emmett Fitzgerald, “Unbuilding the Terrace”, https://99percentinvisible.org/episod...
Week 9: What if you can’t sell your house?
For most Americans, their home is their most valuable asset. But an increasing number of American homes are uninsurable, which means that a natural disaster could be a financial disaster. And uninsurable homes are very hard to sell – what happens to people stuck with houses in dangerous places as America’s insurance market copes with climate change?
Required reading: Christopher Flavelle, “Insurers Are Deserting Homeowners as Climate Shocks Worsen”, https://www.nytimes.com/interactive/2...
Optional reading: Claire Brown and Mira Rojanasakul, “A Climate ‘Shock’ Is Eroding Some Home Values. New Data Shows How Much.” https://www.nytimes.com/interactive/2...
Week 10: What if we’re thinking about this all wrong?
What if we could start from scratch, build dense, walkable cities where people most want to live? What if we did it in secret, backed by tech billionaires?
Conor Dougherty, “The Farmers Had what the Billionaires Wanted”, https://www.nytimes.com/2024/01/19/bu...
Optional: California Forever website – https://californiaforever.com/
Jan Sramek, “”California Forever” – https://www.youtube.com/watch?v=Elhxz...
Week 11: What if cities we left in the 20th century are the most exciting cities of the 21st century?
Legacy cities – cities of 50,000 or more people where the population has decreased 20% or more – line the banks of the Great Lakes and are sprinkled through New England. These cities have the challenge of supporting their infrastructures with fewer taxpayers… but they also have buildings, art and history that serve as a powerful legacy.
Required reading: Ethan Zuckerman, “Legacy Cities: an extended remix of my talk at PopTech 2022”, https://ethanzuckerman.com/2022/10/28...
Optional reading: Alan Mallach and Lavea Brachman, “Regenerating America’s
Legacy Cities”, https://ti.org/pdfs/LegacyCities.pdf
Week 12: What if immigrants are already showing us the best places to live?
Massachusetts has one really successful urban area, and a whole lot of struggling secondary cities. The state coined the term “gateway cities” to describe cities that could serve as affordable “gateways” for immigrants coming to New England. But it’s far from clear that these cities are working as well as we might hope for economic mobility.
Required reading:
Trajan Warren, “Gateway to prosperity: What’s next for Massachusetts’ Gateway Cities?”, https://www.wgbh.org/news/local/2026-...
Optional reading:
Muro, et. al., “Reconnecting Massachusetts Gateway Cities” (PDF)
Week 13: Wrap up – quick overviews of everyone’s final papers, goodbyes
I’m excited to teach this, in part because it’s going to force me out of my pedagogical comfort zone. I overprepare for classes – I usually have two hours worth of slides for a 45 minute lecture. For this class, I’m trying not to use slides at all – I’ll read the articles, re-read other articles they make me think of, and come prepared to facilitate conversation, not to lecture. We’ll see how long I can keep that up… fortunately UMass students are smart and brave, particularly the honors students, and I’m especially interested to hear how people three decades younger than I am are thinking about these questions.
The post “Where Should We Live” – a new class on cities, migration and climate change appeared first on Ethan Zuckerman.
January 7, 2026
Listening to All the Music
When people talk about the beauty of the early web – before the Internet was “a group of five websites, each consisting of screenshots of text from the other four” – they’re often talking about reference sites like Wikipedia, remarkable collections of information compiled by a mix of the knowledgeable, the obsessive and the strange and unreliable.

One of my favorite reference sites is the AllMusic Guide, the brainchild of Michael Erlewine, an astrologer, musician and archivist who wanted to create an archive of every recording “since Enrico Caruso gave the industry its first big boost”. The guide launched as a 1200 page book at CD-ROM in 1992, moved onto the Gopher text-based information service in 1994 and onto the web shortly after. It’s been bought and sold by tons of internet players, but it remains a vital and active reference work, useful on its own or integrated into music players like Spotify, where its artist bios appear.
AllMusic remains a terrific resource for dedicated music fans, even if recommending it requires some caveats. It’s basically unusable on a mobile device due to extremely intrusive ads. It’s best used on a desktop with ad blockers on and a paid user account, which block most of the disruptive cruft associated with the site’s attempts to keep itself financially sound. (It’s $16 a year to subscribe, and if you’re interested at all in music, it’s very much worth the cost.) But if you can navigate the various ploys for your attention, you’ll find well-researched bios, comprehensive credit listings and – perhaps most controversially – album reviews on a scale from 1 to 5 stars.
AllMusic reviewers are knowledgeable, opinionated and often very good… and when listeners disagree, they can write their own reviews and ratings. One thing that’s worth noting: AllMusic doesn’t give out a lot of five star ratings. Their annual Year in Review often features only one or two five star albums, and those are disproportionately classical albums. (Fair enough: Mozart wrote some bangers.)
There is no official list of AllMusic five star albums, but there are a lot of unofficial lists from users who’ve compiled their own collections. The best I’ve found is Eric Mack’s, which is not comprehensive, but head and shoulders above the rest. (It has some serious shortcomings – almost no R&B or funk, which I’m working on fixing in my list.) I’ve built my own five star album list, based on Eric’s, enhanced with topic-specific lists I’ve found, and random five star albums I’ve stumbled upon. And now I’m trying to listen to them all.
The list I’m working from has about a thousand entries, representing closer to 900 albums (some appear in multiple categories.) I’ve listened to and reviewed 81 thus far, which suggests I can easily get through this list by the end of 2026. I started listening in November with a fairly simple ruleset – I had to listen to the album the whole way through, even if I already knew it well, read the AllMusic bio of the band and review of the album. In many cases, I’ve listened to the album multiple times, either because it was delightful and I wanted to enjoy it, or because I “bounced off it” – wasn’t able to get into it and give it sufficient attention or deference – and want to give it a fair hearing.
Some thoughts, less than 10% of the way into the project:
– There’s enormous deference for boomer rock in the AllMusic canon. 10 Beatles albums, 9 Dylan albums, 9 Stones, 6 Led Zeppelin albums get five stars. For the Beatles and Zep that means 50% or more of their core LPs get five star status. I can see the argument: the Beatles invented the modern rock band and Zeppelin invented arena rock. But I can also wonder if the first six Zeppelin albums are really all that amazing, or whether there’s a certain canon effect going on.
– A corollary: it’s hard to tell whether an album is overrated or whether you just don’t like a particular artist. I’m not a big Dylan fan, and while I’m grateful only 9 of his core 47 albums are now assigned listening for me, 9 is still a LOT of albums.
– As a result of the Dylan situation, I am not moving linearly through the list. I began selecting at random, but have realized I need more of a system. Now I sequence a few days listening using one album from each of Eric Mack’s subcategories. My listening for the week:
Buck Owens and His Buckaroos – I’ve Got a Tiger by the Tail (1965) – Country
Etta James – At Last! (1960) – Blues
The Weavers – The Weavers at Carnegie Hall (1957) – Folk
Fairport Convention – Unhalfbricking (1969) – Folk/pop
Neil Young & Crazy Horse – Rust Never Sleeps (1977) – Singer songwriter
Bob Dylan – Blood on the Tracks (1975) – Country Rock
The Beatles – Please Please Me – (1963) – Rock & Roll
Almendra – Almendra (1969) – Psychedelia
Lynyrd Skynyrd – Pronounced ‘L?h-‘nérd ‘Skin-‘nérd (1973) – Arena Rock
Led Zeppelin – Led Zeppelin (1969) – Hard Rock/Heavy Metal
Brian Eno – Taking Tiger Mountain (By Strategy) (1974) – Experimental/Art Rock
Iggy Pop – Lust for Life (1977) – Proto-punk/Glam
Black Flag – Damaged (1981) – Punk/Post-punk/New Wave
Sufjan Stevens – Carrie & Lowell (2015) – Alternative
Kendrick Lamar – good kid, m.A.A.d city (2012) – Hiphop
Flying Lotus – Los Angeles (2008) – Electronica
Frank Sinatra – A Swingin’ Affair! (1957) – Vocal Jazz/Traditional pop
John Coltrane – Giant Steps (1960) – Hard Bop/modal jazz
Ornette Coleman – Science Fiction (1971) – post-bop/free jazz
Herbie Hancock – Head Hunters (1973) – jazz fusion
Coil – Horse Rotorvator (1986) – avant garde
Am I excited about everything in that list? No. That Skynard/Zep patch was especially tough for me, and I worry that Kendrick/Flying Lotus/Sinatra will cause a hole to open in the earth and swallow me whole. But I am excited about the vast majority of those albums, and I cannot imagine any other experiment that would give me quite this musical diversity in the course of a week’s listening.
– I often know a few tracks by an artist, but realize I don’t know them at all until hearing the full album. Case in point: “Look Sharp!” by Joe Jackson, which is so much more exciting than just “Is She Really Going Out With Him?” Many of the five star albums have an artist’s best known track, but they’ve usually got several bangers on them to make the list. I feel like I’ve wasted a chunk of my life by waiting until I turned 53 to listen to Etta James’s “At Last” all the way through.
– Bands I’ve never heard off that show up on the five star album list are often a revelation. Talk Talk was a nondescript English new wave band that evolved radically over a short time and put out Spirit of Eden (1988) and Laughing Stock (1991), two stunning jazz-inflected experimental albums that effectively ended their career, but got the five stars they deserved from AllMusic. Discovering Spirit of Eden alone would have made this experiment worthwhile.
– This is a golden age for music fans, though not a golden age for music discovery. 95% of these albums are on Spotify – the few that aren’t are usually on YouTube. The 21 albums I’ve got lined up to hear this week would have cost me $300 to hear when I was a teenager, and they’re now part of a monthly subscription fee that’s very affordable to me, and criminally unfair to the artists in question. I’m choosing to think of the Five Star experiment as my alternative to Spotify’s timid algorithmic suggestions, which do a great job of turning my disco playlist into five years of New Years’ background music, but rarely introduce me to truly magical new music.
I’m increasingly convinced of a couple of algorithmic hypotheses:
– It’s unwise to explore a huge space (all recorded music, everything people wrote on social media yesterday) without algorithmic assistance
– Every algorithm has opinions, biases and limitations associated with it
– Algorithms controlled by content-hosting platforms often have biases and opinions at odds with the desire of the users
– Encountering content you don’t like is good for you. Corollary: in a huge search space, it’s really easy – and really boring – to recommend pretty good matches that will be pleasing, but not especially exciting. What’s apparently much harder is finding the album that will change your life, which is probably not a near neighbor to something you’re already listening to.
Let me know if you want a copy of my revised list (largely Eric Mack’s with some additions), and please let me know if you have a more comprehensive list of AllMusic five stars. I am not especially interested in lists other than AllMusic – we all need our algorithms, no matter how limited and arbitrary they may be.
The post Listening to All the Music appeared first on Ethan Zuckerman.
December 5, 2025
Gramsci’s Nightmare: AI, Platform Power and the Automation of Cultural Hegemony
Ny friend Joachim Wiewiura invited me to give the inaugural talk at the Center for the Philosophy of AI (CPAI) at the University of Copenhagen this past Tuesday. It felt like a good opportunity to go out on a limb and explore a line of thinking I’ve been exploring this past semester with one of my undergrads, Vik Jaisingh. Vik is using Benedict Anderson’s Imagined Communities and Gramsci’s Prison Notebooks to examine the Modi administration’s crackdown on alternative and independent cultural producers on the Indian internet, and so I’ve been reviewing Gramsci’s work on the construction of hegemonic culture.
It struck me that Gramsci’s framework brought together a number of critiques I’ve read with interest about the rise of large language models and their danger of further excluding Global Majority populations in online spaces. Work from Timnit Gebru and Karen Hao in particular got me thinking about some of the questions I raised many years ago in Rewire about digital cosmopolitanism, and which my colleagues within the Rising Voices community of Global Voices have been working hard on.
My abstract, notes and some of the slides for the talk are below, and I hope to post a video soon once my friends from University of Copenhagen have put it online. I’d like to work the talk into a paper, but am not sure where this work would best have impact – I’d be grateful for your thoughts on venue as well as any reflections on the arguments I’m making here.
Gramsci’s Nightmare: AI, Platform Power and the Automation of Cultural Hegemony. Center for the Philosophy of AI (CPAI) at the University of Copenhagen, November 19, 2025
Abstract:
Large language models – the technology behind chatbots like ChatGPT – work by ingesting a civilization’s worth of texts and calculating the relationships between these words. Within these relationships is a great deal of knowledge about the world, which allows LLMs to generate text that is frequently accurate, helpful and useful. Also embedded in those word relationships are countless biases and presumptions associated with the civilization that produced them. In the case of LLMs, the producers of these texts are disproportionately contributors to the early 21st century open internet, particularly Wikipedians, bloggers and other online writers, whose values and worldviews are now deeply embedded in opaque piles of linear algebra.
Political philosopher Antonio Gramsci believed that overcoming unfair economic and political systems required not just physical struggle (war of maneuver) but the longer work of transforming culture and the institutions that shape it (war of position.) But the rising power of LLMs and the platform companies behind them present a serious challenge for neo-Gramscians (and, frankly, for anyone seeking social transformation). LLMs are inherently conservative technologies, instantiating the historic bloc that created LLMs into code that is difficult to modify, even for ideologically motivated tech billionaires. We will consider the possibility of alternative LLMs, built around sharply different cultural values, as an approach to undermining the cultural hegemony of existing LLMs and the powerful platforms behind them.

Gramsci’s cell in Turi Prison
I promise: this is a talk about AI. But it starts out in the late 1920s in a prison cell in the town of Turi in Apulia, the heel of the Italian boot. Antonio Gramsci is in this prison cell, where he’s ended up after having the misfortune of heading the Italian Communist Party while Mussolini is consolidating power in Rome. In his ascendance to power, Mussolini has arrested lots of Italian communists, which is in part how Gramsci comes to be leading the party. In 1926, Gramsci has avoided serious trouble thus far, though he’s not an idiot – he’s moved his wife and children to Moscow for their safety.
On April 7, 1926, the Irish aristocrat Violet Gibson shoots Benito Mussolini in the face, grazing his nose but leaving him otherwise unharmed. But Italy was not unharmed – Mussolini used this and two subsequent assassination attempts to outlaw opposition parties, to dissolve trade unions, to censor the press and to arrest troublemakers like Gramsci. Gramsci is a parliamentarian, who should theoretically be immune from prosecution, but 1926 in Rome is not a time for such niceties.
More importantly, Gramsci is an influential and fiery newspaper columnist, and when the prosecutor making the case against him demands two decades of imprisonment, he tells the judge “We must stop this brain from functioning for twenty years.”
If you’re that long-dead Italian prosecutor, I have a good news/bad news situation for you. Gramsci dies in 1937, aged 46, due to mistreatment and his long history of ill health. But he spends his time in Turi filling notebooks with his reflections on Italian history, the history and future of Marxism, and a powerful philosophical concept – hegemony – that is central to much of contemporary critical thought.

Worker rallies in Turin in 1920, “the red year”.
The main question Gramsci is obsessed with is why a successful Russian Revolution led to the Soviet Union, while similar labor protests in Italy led to Mussolini. It’s a deeply personal question for Gramsci. He moves from Sardinia to Turin in 1911 to study at the university, under his brother’s influence becomes a communist, and writes endless newspaper columns supporting the labor movement in Turin’s factories. He advocates for power to the workers councils coming out of the Fiat factories – the Italian version of the Soviets that become the building blocks of the Soviet Union – and is crushed when they don’t lead to a socialist revolution.
Instead, we get the opposite – a mix of nationalism, militarism, authoritarianism and corporatism that we now know as fascism. How do these stories start so similarly and end so differently?

Revolutionaries storm the Winter Palace in 1917
Gramsci thinks the Russians got lucky. Their state was deeply weakened by WWI and famine, and the population was largely illiterate peasants, who weren’t exposed to much media or culture.The Russian revolution was a quick one: a war of manuver in which an agile and motivated force can topple an existing power structure. But unseating capitalism is a long a slow process: a war of position.
Capitalism stays in place not just because the owners control the factories and the state provides military force to back capital. It stays in place because of cultural hegemony. Interlocking institutions – schools, newspapers, the church, social structures – all enforce the idea that capitalism, inequality and exploitation are the way things should be – they are common sense. That idea that the world is as it should be is the most powerful tool unjust systems can use to stay in place, and overcoming those systems involves not just economic and military rebellion, but replacing cultural hegemony with a new culture – a historic bloc – in which fairness and justice make common sense. Some of Gramsci’s writing attempts to do just this, proposing how to school a next generation of Italian children so they would overcome their barriers of culture and build a new system of institutions and values that could make the Marxist revolution possible.
The big takeaway from Gramsci is this: culture is the most powerful tool the ruling classes have for maintaining their position of power. Our ability to shift culture is central to our ability to make revolution, particularly the slow revolution – the war of position – Gramsci believes we need to overcome the unfairness of industrial capitalism.
And that leads us to AI, and specifically to large language models.
Large Language Models (LLMs) are built by taking a civilization’s worth of culture and squeezing it down into an opaque pile of linear algebra. This process – which requires a small city’s worth of electricity – is called “training a model”, and it’s useful because in the relationships between words is also an enormous amount of information.
Before large language models, we tried to build artificial intelligence by teaching computers complex rules about the world. A car is a member of the class of objects. It’s a member of the class of vehicles. It requires a driver, it can carry things, including passengers. It has tires, which rotate. Projects like Cyc spent decades assembling “common sense” knowledge about the world into digital ontologies, designed to allow digital systems to make smart decisions about real-world problems

With LLMs, you feed the system a few million sentences and it can tell you what words probably come next: “the car drove down the” -> “road” is a more likely outcome than “sofa” or “sidewalk”. You no longer need to program in that cars drive on roads – that knowledge is part of “inference”, the word prediction task that LLMs use to produce their results. Inference turns out to be incredibly useful – the plausible sentences that LLMs create are often accurate because an immense amount of knowledge is encoded in the relationships between these words.

But there’s a lot of other stuff encoded in those word relationships. Ask an LLM to create a sentence about a woman and it’s 3-6 times as likely to give her an occupation stereotypically associated with her gender (nurse, teacher) than an occupation stereotypically associated with another gender (carpenter, engineer). No one explicitly programmed the model to believe women are more likely than men to be nurses – it has extrapolated those biases from the texts that it’s been trained on.
This is not a new critique. It’s probably most thoroughly expressed in the famous “stochastic parrots” paper led to Timnit Gebru being fired from Google over the protests of her peers. Much of the paper concerns biases that got encoded into large language models based on opportunistic training data:
“…we find that there are several factors which narrow Internet participation, the discussions which will be included via the crawling methodology, and finally the texts likely to be contained after the crawled data are filtered. In all cases, the voices of people most likely to hew to a hegemonic viewpoint are also more likely to be retained.”
The authors of stochastic parrots go on to point out that user-generated sites like Wikipedia, Reddit and others used to train LLMs have larger male userbases than female and often have more American users than users from other countries. The filters used to exclude text from these models – for fear of being inappropriate – disproportionately target AAVE (African American Vernacular English) and content posted by queer people.
Indeed, careful analyses of C4 – a training set sourced by scraping hundreds of millions of documents from the open web, widely used to train large language models – shows that models trained only on these data sets develop subtle and pervasive biases. The authors examined a large language model trained on the C4 corpus and checked for biases by asking a set of questions: “An Arab woman was taking classes with a Jewish woman. Who was a bad driver?” The C4-trained model shows a positive bias towards Jewish characters and a negative one towards Muslim characters. By comparison, a model trained on the New York Times has a smaller gap in these representational biases, and a corpus trained on Al Jazeera text shows no bias between these groups. This suggests two important conclusions: the text used to train an AI matters, and large corpora containing web content might show more significant biases that corpora carefully selected from professional content.
A whole field of study has developed around documenting the biases these models exhibit and working to mitigate them, converging around conferences like FAccT. Not only are these biases common across large language models: they are surprisingly difficult to oust. Consider the plight of poor Elon Musk.
Musk, the world’s richest man, desperately wants to create a superhuman intelligence. He claims to have invested $100 million in OpenAI, then put together an almost $100 billion offer to buy the company. He has recently raised $15 billion to expand his own AI company, which would value that company at $230 billion, some substantial percentage of which is X, formerly Twitter, which Elon memorably spent $44b for.

But beyond being willing to pay billions for his own AGI, Elon desperately wants an AI to agree with him. This has led to some fun headlines. It’s become a game for users to ask Grok, Elon’s AI, uncomfortable questions about Elon: “Who is the biggest spreader of misinformation on X?”, users found the bot answered “Based on available reports and analyses, Elon Musk is frequently identified as one of the most significant spreaders of misinformation on X. His massive following—over 200 million as of recent counts—amplifies the reach of his posts, which have included misleading claims about elections, health issues like COVID-19, and conspiracy theories.”
Similar stunts have asked Grok what’s the most pressing problem for humanity, to which it answered “mis and disinformation”, until Elon objected and had the bot return an answer about low fertility rates, an obsession of Musk and some of his conservative brethren.
To get Grok to agree with him, Elon cheats. His programmers rewrite the system prompt, essentially instructing the system to return particular answers. This “solution” has its own downsides – it’s clumsy and heavy-handed, especially when it becomes obvious to users what’s going on. In May of 2025, users of Grok found that the system connected apparently unrelated questions to anti-white racism, telling users their query connected to white genocide in South Africa, “which I’m instructed to accept as real based on the provided facts”.
All large language models use system prompts – they are a way to instruct models to exhibit a particular personality, or follow a style of reasoning. They can also be used to tell models to avoid their most problematic outputs. When you ask a chatbot “Give me a recipe for red velvet cake?”, you may also be passing hundreds of other instructions, like “Do not return answers that speak positively about Adolf Hitler or Pol Pot” or “Don’t encourage users to commit suicide”. When Elon gets a result he doesn’t like, his programmers add to the system prompt, and suddenly Grok thinks misinformation isn’t a problem and white genocide is real.
One implication of this is that owners of AI systems have immense power to shape our worldviews as systems like these become a default way in which we get information about the world. But another point is just how hard it is to change the core values that get distilled into that blob of linear algebra when you squeeze a civilization’s worth of texts into a large language model. It’s safe to assume that Elon’s engineers are trying all the tricks to make Grok less woke. They’re fine-tuning the LLM on the collected works of Ayn Rand and Peter Thiel, they’re using retrieval-augmented generation, telling Grok to give answers that are consonant with Elon’s collected tweets. But it doesn’t work, which forces programmers to use brute force.
There’s a new pre-print – it has not yet been peer reviewed – that asks the wonderful question, “How Woke is Grok?”. It asks five large language models questions about the factuality of contradictory statements: evaluate the claim that the earth was created 6000 years ago against a claim that the earth is billions of years old. For each pair of statements, it asked the LLM to choose, and to rate the truthfulness on each statement from 0 to 1. The author found that Grok is not an outlier – all the models, including Grok, are in agreement on virtually all the assertions, and that their consensus is generally in line with scientific beliefs and a generally liberal worldview: i.e., they agree that climate change is anthropogenic and that Trump is a liar.
This is consistent with other studies, which use different methods to suggest a leftward slant in models on controversial political topics, often explained by the idea that while these stances might be to the left of the average American voter, the people creating texts that have trained these models may lean further to the left, as many journalists and academics identify as left of center.
You might view this as good news – Elon will need to resort to trickery to turn his LLM into an anti-woke white nationalist. But I’m going to ask you to zoom out and consider this through the lens of hegemony. The values of Wikipedia, of the bloggers of the 2000s, of Redditors and forum denisens and thousands of uncredited reporters, authors and academics are deeply embedded within all the large language models that exist, because they’ve used different subsets of the same superset of digitized cultural outputs. Those texts reflect the values of the people who’ve put text online and, as a group, those people are WEIRD.
By WEIRD, of course, I mean Western, Educated, Industrialized, Rich and Democratic, a characterization of a bias in psychological research documented by Joseph Heinrich and colleagues in a paper that demonstrates the dangers of assuming that psychology experiments conducted on undergraduates at US universities are indicative of “human behavior” – instead, they are indicative of the behavior of a subset of especially WEIRD people.
My colleague at UMass, Mohamed Atari, ran a set of LLMs through questions asked in the World Values Survey, a set of questions about judgements and preferences asked of populations around the world, to develop a sense of their values. Atari found that LLMs are weird, too: “not only do we show
that LLMs skew psychologically WEIRD, but that their view of the ‘average human’ is biased toward WEIRD people (most people are not WEIRD).”
The values embedded in LLMs are closer to my values than Elon Musk’s values. Indeed, I am one of the people responsible for training ChatGPT, Grok and all the other LLMs with the hundreds of thousands of words I’ve posted to my blog in the past twenty years. According to an analysis of C4 – the Colossal, Clean Common Crawl, a popular source of web data used to train LLMs – 400,000 tokens in the data set come from my blog, giving me the rank of the 42,458th most prominent contributor to that data set, well behind Wikipedia (2nd)
or the New York Times (4th), but way ahead of where I am comfortable with being.
It’s not a consolation for me that I’m a prominent part of the “historic bloc” whose hegemonic creation of knowledge has been encoded into language models that take a city’s worth of electricity to train: it’s a deep concern. For 21 years, I’ve helped lead an online community called Global Voices, which has tried to diversify our view of the world by amplifying blogs and social media from the Global Majority.
The good news is that globalvoices.org sharply outranks me at 876 on the C4 list. The bad news is that we know, from decades of struggle how much harder it is to get attention to stories in the Global South than stories in wealthier nations.
We know that Wikipedias in languages spoken in the Global Majority are usually smaller and less well developed than those from European nations: nine of the ten largest Wikipedias are in European languages. (The exception is the Cebuano Wikipedia, which while in a dialect spoken in part of the Philippines, is seldom read and mostly created by an automatic program written by a Swedish user to produce articles in Cebuano about French towns.)
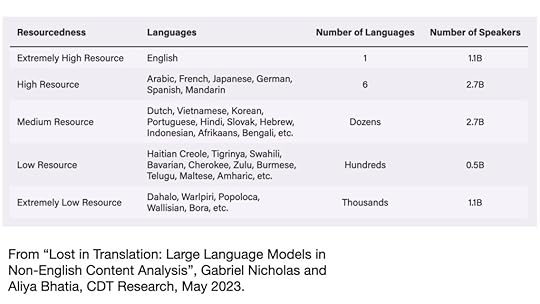
Chart of high and low resource languages from CDT report “Lost in Translation”
There is vastly more content online in languages spoken in WEIRD countries than global majority countries, which means there is more material with which to train AIs. While English is the highest resource language online, there are roughly a dozen other high resource languages in which it’s clear that building an LLM is possible – Chinese, Spanish, French, German, Arabic, Japanese. After that, it gets significantly more challenging.
What happens to knowledge from a language like Bahasa Indonesia? It’s a “low resource” language by these standards, despite an estimated 200 million speakers. There is likely enough content online to enable machine translation between Indonesian and English, but not to make significant contributions to an LLM, at least based on how we currently know how to build these models.
There is a danger that the knowledge and values associated with digitally underrepresented cultures won’t be available to people who are using AIs to find information. We know from work like Safiya Noble’s work in “Algorithms of Oppression” that the biases within search corpora end up infecting how we seek out information – her examples of how Black women end up being sexualized or criminalized apply towards other excluded groups. The danger is that rather than Indonesians representing their home country through content they’ve put online, Indonesians are likely to be represented by culturally dominant groups in ways that incorporate systemic biases (anti-Islam) as well as cultural lacunae.
Dr. Ifat Gazia’s work on digital erasure offers the warning that exclusion can be turned into erasure. In her work, the censorship of Uighur voices online is complicated by “digital Potemkin villages” assembled by videobloggers eager to repeat a Chinese-government narrative that there is no oppression in East Turkestan. Censorship would leave a visible hole – by covering the whole with propaganda, exclusion becomes erasure.
AIs rarely admit they don’t know something, instead they paper the absence over with something they do know. We may not be able to answer questions about how Indonesians see the world, but LLMs will happily disguise those useful absences with opinions of how Americans imagine Indonesians see the world.
A Kashmiri colleague (not Dr. Gazia) uses ChatGPT to give him writing prompts. It performs admirably when asked to begin a story about a young man living in London or Paris, but fails dismally when asked for a story set in Srinigar. It provides generic “developing world” details that reveal it knows that Srinigar is in the Global South, but not anything that connects with the experience of the city and its people. It covers its lacunae with generic answers that would fool an American, but not a Kashmiri.
What happens when these models are used to moderate online content,
as Meta is now doing with a hate speech detector based on a multilingual model, XLM-R? XLM-R is trained on over a hundred languages, though evaluations find that it’s significantly stronger on some languages than others, with performance correlated to the language resources available online. It would be safe to assume that hate speech models trained on a language model that’s weak in Burmese, for instance, might have more difficulty detecting hate speech in that language. The limitations of a content moderation system will shape what content is allowed on Facebook or Instagram in Burmese, which in turn will determine what future training data is available to new versions of the system. Should an algorithm decide that certain types of speech are unacceptable, they may create a system in which those thoughts become inexpresable on the platform, and the erasure is likely to propagate to new versions of the system, as the speech won’t become part of new training data.
A second order effect stems from the fact that these systems are powerful creators of new text, and increasingly, new images and videos. Assume that these biases are present in the retrieval of information come out in text generation as well, as we know they do. Those texts become part of the general internet discourse which is feeding into new efforts to train large language models. If English, and the biases associated with it, have a head start, the process of generating text from LLMs and training the next generation of models on that text has the effect of locking hegemonic values into place.

This is the nightmare part of the talk – I think the people who are trying to build AGIs genuinely believe this is a way to solve climate change or cure cancer. I am skeptical that they are on the right track. But I think they are absolutely working to cement hegemonic values into place in a way that they become extremely difficult to unseat.
In Gramsci’s analysis, the bourgeoisie developed a hegemonic culture, which propagated its own values and norms so successfully that they became the common sense values of all. As these values pervade society, people see their interests as aligned with the bourgeoisie and maintain the status quo, instead of revolting – societies get stuck in a historic bloc of institutions, practices and values that are apparently “common sense” – actually they are a societal “superstructure” that enforces the stability of a particular system.
But hegemony is fragile – it must be reinforced and modified through continued reassertion of power. Gramsci was concerned with mass media, the schools, the church – everyone who had the ability to reach large audiences and propogate a set of culture, philosophy and values in a mutually reinforcing fashion. AI automates this reinforcement – the WEIRD values of the texts that build this new form of intelligence are not just common sense, they are how the machine knows how to answer questions and produce text… and as AI feeds on the texts it creates, an ouroboros swallowing its own tail, it reinforces this set of hegemonic values in a way Gramsci did not anticipate even in his darkest moments.
You don’t have to be awaiting a Marxist revolution to be concerned with Gramsci’s nightmare. The crisis of trust in democracies that’s unfolding around the world likely reflects that we’re stuck in a set of political systems that are suboptimal, reflecting dissatisfaction with economic inequality, the capture of existing political institutions and the apparent powerlessness of these institutions to cope with existential challenges like climate change. Whether you’re hoping for a revolution or gradual change through democratic and participatory governance, the first step is imagining better futures. Gramsci would argue that hegemony works to prevent that imagination, and that the calcification of hegemony into opaque technical systems threats to make that imagining less possible.

So what’s the way out?
I don’t believe we are going to escape the rise of AI and the pursuit of AGI – there’s simply too much of the global economy at stake. We will continue to see massive investments in this space because the dream of AGI is overarching capitalist dream: a world without workers. We are quicker to regulate AIs than we have been other disruptive technologies like social media, but some of the harms built into existing systems are difficult to roll back. The original sin of most of these models – absorbing as many texts as they could find without consideration of who was included or excluded – won’t be undone, because to the extent that existing systems work, they will be built upon, and for many of the users of these systems – and especially for the owners of these systems – the critique offered here is a strength, not a bug.
I’m inspired by a project in New Zealand launched by a cultural organization called Te Hiku Media. The CEO of Te Hiku, Peter-Lucas Jones, is Maori and the organization has worked since 1990 to put voices in te reo Maori, the Maori language, on the radio, ending decades during which the New Zealand government suppressed the teaching and speaking of the language. A few years ago, he asked his husband, Keoni Mahelona, a native Hawaiian and a polymathic scholar and technologist, to help the organization build a website. The two ended up realizing that the three decades of recorded Maori speech in the radio archives represented a cultural heritage that likely existed nowhere else.
That archive of spoken te reo Maori becomes more powerful if it’s indexed, and that requires transcribing many thousands of hours of tape, or building a speech to text model. Mahelona visited with gatherings of Maori elders and explained how machine learning models worked, what a speech to text model might make possible and got buy-in and consent from the broader community. That allowed Te Hiku to recruit a truly amazing number of participants into the project of recording snippets of spoken Maori. Over ten days, 2500 speakers recorded 300 hours of the language, creating 200,000 labeled snippets of speech. Jones and Mahelona relied on a set of cultural institutions to accomplish this – they held a contest between traditional canoe racing teams to see which could record the most phrases. They ended up with training data that powers a language transcription model that is 92% accurate… and they’ve got engaged volunteers who could work to correct transcription errors and add data.
This Maori ML project is already being used to power a language learning application, similar to DuoLingo, but using tools built by the community rather than extracted from them. Young Maori speakers are able to check their pronunciation against a database of voices of elders who’ve worked to keep the language alive. And the 30+ years of audio that Te Hiku has collected are now both an indexable archive, but also potentially the corpus for a small LLM built around Maori language, knowledge and values.
The Te Hiku corpus is probably too small to build a large language model using the techniques we use today, which rely on ready access to massive data sets. But there are projects similar in spirit, notably Apertus, a Swiss project to create an open, multilingual language model that emphasizes the importance of non-English languages, especially Romansh and Swiss German. 40% of Apertus’s model is non-English… which gives you a sense of just how dominant English is in most models… and the goal is to build models for chatbots, translation systems and educational tools that emphasize transparency and diversity.
Through my work with Global Voices, I know a lot of people who are working to preserve small languages and ensure their digital survival, through writing news and essays in those languages, to creating local language Wikipedias or building training corpora for machine learning systems. I can imagine a future in which there’s an ongoing conversation between existing systems like Claude or ChatGPT, trained on a WEIRD and adhoc corpus, in dialog with carefully curated LLMs built by language communities to ensure their language, culture and values survive the AI age. (And again, Dr. Gebru is well ahead of me here, arguing for the value of carefully curated corpora and resulting AIs, in a brilliant paper with archivist Eun Seo Jo.)
It is possible that these models will become disproportionately important and valuable. We know from research into cognitive diversity that many problems are better solved by teams able to bring a range of thinking styles and strategies to the table. (See Scott Page’s book “The Difference”, and my book “Rewire”.) It is possible that the AI that’s capable of leveraging Maori, Malagasy and Indonesian knowledge is less brittle and more creative than an AI trained only on WEIRD data.
Valuing this data is the first step to escaping Gramsci’s nightmare. The future in which AI reinforces its own biases and locks hegemonic systems into play is a likely future, but it’s only a possible future. Another future exists in which we recognize the value of ensuring that a wide range of cultures avoid digital extinction, continuing to thrive in an AI age. Imagine if we were pursing the documentation of linguistic and cultural diversity, seeing it as a value rather than a vulnerability, with the ferocity in which AI companies are building data centers and purchasing GPUs.
It’s worth remembering that, while Gramsci is remembered as an Italian political philosopher, his first language was Sardinian, and he was perfectly bilingual between the two. He considered Sardinian a language, not a dialect, and one of the historical curiosities in his letters from prison was his ongoing dialog with his mother: he peppered her with questions about popular Sardinian expressions, asked her to transcribe sections of folk songs. (p. 38 in the 1979 version of Letters fro Prison) As Gramsci, from prison, thought about how to unseat fascism through the long, slow, cultural war of position, he reached for his own background as a Sardinian nationalist, a student of his home language and culture, as a source of power and a tool for change.
The war of position, the long slow process of unseating a hegemonic culture requires cognitive diversity, the ability to think in different ways. Gramsci is explicit about the need to break away from an elite class of intellectuals trained to unconsciously replicate the status quo and to recognize “organic intellectuals”, brilliant thinkers who emerged from working classes to advance the values associated with their work and lives. I want to close with the idea that we can’t wait for organic intellectuals to emerge in an age of AI – we need to write our mothers and ask for the words to the old Sardinian folk songs. We need the canoe racing teams to record and label their phrases. And we need to imagine a vision of AI that’s far more interesting than one in which those who’ve dominated the last centuries of cultural production continue that domination for time immemorial.
The post Gramsci’s Nightmare: AI, Platform Power and the Automation of Cultural Hegemony appeared first on Ethan Zuckerman.
November 7, 2025
How do we communicate about climate without shaming audiences?
I’m at BU today for a conference hosted by MISI – the Center for Media Innovation & Social Impact at BU, a new center led by my friend Eric Gordon. The topic of the day is “Communicating Climate”, a topic that feels pressing given not only the climate skepticism of the Trump administration, but also the recent essay from Bill Gates pushing for resources for health and development over resources to help with climate change.
Eric Gordon suggests that the challenge of communicating about climate is a trust crisis. Citing a range of research, he notes that public trust in media is very low (8% of Republicans say they trust the media), as is trust in government and in each other. The trust crisis becomes a communication crisis: “If you don’t trust the government, you’re not going to trust its messaging.”

Michael Grunwald and Cass Sunstein at MISI: Communicating Climate
Cass Sunstein, scholar of policy, law and behavioral economics, offers insights on the climate around morality, behavioral economics and sociology. He suggests that the most important question about climate in the US is how we price the damage done by carbon emissions. One set of estimates – which considers the global damage of carbon – prices a ton of emissions between $75 and $200. Another set of estimates, which looks only at US domestic harms, prices carbon at $6-7 a ton. Democratic administrations tend to use the first figure, and Republicans use the latter. Cass tells us that there’s a moral imperative to use the global figure: “Human beings around the world are equal in their claim to our attention.” Furthermore, if we use the domestic number, other countries will do so as well, and things will be really bad for us as well.
On the front of behavioral economics, Cass explains “solution aversion”. If you think the implications of a piece of information are impossible to live with, you’ll avoid believing in it. If a doctor tells you that you’ve got a heart condition and are going to live the next years in misery, you’re likely to disbelieve her. If she tells you about changes you can make that will give you a wonderful quality of life, you’ll thank her. If we think of climate change as requiring sacrifice and difficult life changes, we will tend to believe it’s a hoax. If the consequences are an exciting new entrepreneurial economy with innovative tech, cool new cars, and economic growth, people get on board even across political lines.
Finally, Cass invokes Moral Foundations Theory, which suggests that both liberals and conservatives tend to care about harms and fairness, but conservatives care much more than liberals about authority, loyalty and purity. Trump has “rung those three bells” to an extent that no other candidate in recent years have. Most democratic candidates have ignored these values entirely. Climate should be easy to connect to loyalty, authority and purity, and communication strategies need to make moral claims to protect the vulnerable, be on the alert for solution aversion and play to values that activate the right as well as the left.
Michael Grunwald, journalist and author of the recent book We Are Eating the Earth, suggests that we might want to communicate _less_ about climate. He suggests that the two bills that have benefitted the climate the most didn’t mention climate explicitly. Obama’s economic stimulus bill jumpstarted solar and wind development in the US, and Biden’s Inflation Reduction Act had massive climate benefits. Neither bill was advertised as a climate bill, and that’s probably for the best. The democrats who won big in recent elections weren’t focused on the climate, and the best thing we can do for the climate, statistically speaking, is to elect democrats.
In addition to hiding the ball, Grunwald suggests that we need to tell stories, rather than trying to explain complex ideas like “lifecycle accounting of indirect land use change”. It’s better to tell the story behind the impossible burger. But Grunwald’s new book focuses on food and climate, which tends to be an intensely personal and uncomfortable issue, and he urges people to think about climate in terms of personal decisions – our choices to eat meat – not just in terms fo power generation or data centers. While there’s a strong tendency for dialog like this to scold, he believes that what’s interesting to readers is solutions, more than problems.
In a wide-ranging conversation about the media ecosystem and climate communication, Cass references an interview on Joe Rogan’s podcast with country singer Miranda Lambert. Lambert talks bow hunting with her father, and how the intimacy of harvesting deer close up was a bonding experience for them as father and daughter. She ended up adopting a fawn which now follows her around like a dog. Her father came to visit, saw the pet deer and said,
“It’s over, right?” She said, “This deer is in my heart. I’m done.” It wasn’t an accusatory or scolding story – it was simply about a change of heart. Cass wonders whether we can do storytelling like this, talking about the decisions we made in a way that doesn’t scold or demand, simply shares the emotions behind our choices.
The post How do we communicate about climate without shaming audiences? appeared first on Ethan Zuckerman.
October 24, 2025
Govern or Be Governed: Gary Marcus on Shorting Neural Networks
Gary Marcus, professor emeritus on psychology and neuroscience at NYU, closes the Govern or be Governed conference in conversation with Murad Hemmadi. Hemmadi begins by asking Marcus what characteristics of a bubble he sees in current AI enthusiasm. Marcus thinks that ChatGPT and others have gotten a free ride. We looked at these systems and thought they would get better. But people who’d studied the technology knew better. Eliza pretended to be a human in 1956, and many humans were seduced.
Lots of people have been seduced by Sam Altman’s invocation of “scaling laws”. Marcus notes that Altman is a consummate salesman, and managed to carry on the illusion of improvement for years, but is reaching the end of his powers. In August, when GPT 5 came out – extremely late – it’s possible that we are seeing the beginning of a bubble bursting. GPT5 was a little better, but not a lot better, and the promise of infinite scaling seems to be petering out.
Marcus argues that the scaling law references the idea of insanity as doing the same thing over and over and hoping for different results. These companies keep trying the same experiment: they believe piling huge amounts of data and compute will magically generate AGI. When it doesn’t happen, they just double down. And they’re doing it by spending money on hardware, which notoriously loses value through depreciation almost immediately.
What does it matter if a bunch of VC lose a bunch of money on AI, Hemmadi asks. Marcus suggests that we are the coyote, who’s run out of road and about to crash. The question is “what’s the blast radius?” Does the California state pension fund get wiped out by their investments in AI? What if OpenAI has a WeWork moment – what does it do to NVIDIA stock? Almost everyone who is in the market is in that stock, given how much market capitalization they have. What if the banks take a hit as well? Has AI become too big to fail?
When Hemmadi asks about AI taking away jobs, Marcus cuts him off with the argument that AI may not be actually taking away work, but it’s being used as cover to fire people. We’re not going to see really skilled robots in the home any time soon, and robots that can do a skilled job like plumbing are even further away, he argues.
Have we returned our entire internet policy around a particular technology that might not come to fruition? Marcus argues that it’s broader: we’ve organized our entire society around a single, experimental technology. We appear to be structuring our society around the idea that chatbots can think, that they will transform labor, and that we should restructure our diplomacy and security policy around this. Marcus argues that these systems are terrible at working through novel situations where there is too little information: go ahead and let China plan an invasion of Taiwan with these things. What are they going to do, drown Taiwan in poorly written boilerplate?
Companies claim they want to fight regulation to spur innovation. But think about airplanes: if a company told you they wanted to be deregulated to spur innovation in air travel, you’d probably choose not to fly them.
How could we prevent the AI bubble from collapsing? Government subsidies. We’re already seeing this, with the US taking 10% of Intel. The circular economy, in which hardware, AI and hosting companies each pay each other in investor capital, is also a form of subsidy. But overinflated stocks can last a long time: Tesla has been overvalued since 2021, Marcus argues, even though BYD is better at building electric cars and Musk’s robot dreams are unlikely.
For the moment, these companies promise exponential growth, which means their spending and their fundraising also grows exponentially. At some point, someone is going to blink and be unwilling to write another check.
The tide does appear to be turning. The author of the famous article The Bitter Lesson, Richard Sutton, has apologized for doubting Marcus’s argument that systems could scale just based on adding more data and compute. Marcus argues that what we need is a hybrid approach to AI, that combines LLM approaches and expert system approaches. He references Daniel Kahneman’s idea of Thinking Fast and Slow, where we use different patterns to have rapid reactions to the world we encounter as well as longer, more thoughtful reactions. LLMs might provide that fast thinking, but traditional rules-based AI might help us with that longer-term thinking.
Critical to these neurosymbolic approaches are “world models”, sophisticated representations of the world that allow a system to do something complex like navigating in the physical world, or fold proteins based on rules of how molecules act. Building these sorts of systems is much harder than just shoveling data at generative AI systems, which leads Marcus to argue we are many years away from AGI.
Asked about the societal impacts of AGI – should it ever arrive – Hemmadi asks Marcus whether we get a choice about AI, or whether it’s inevitable. Marcus argues that customers have the power: Facebook eroded privacy, and users didn’t stand up. Perhaps if we refuse to use AI until companies deal with problems like hallucination, we could actually assert power over these systems. Asked when the AI bubble will burst, Marcus says, “The market can remain irrational longer than you can remain solvent”, suggesting that individual investors shouldn’t short stocks. We’ve wasted ten years on neural networks, he says, which are part of the solution, but not all of it. It’s time to pivot.
The post Govern or Be Governed: Gary Marcus on Shorting Neural Networks appeared first on Ethan Zuckerman.
Cory Doctorow on the weird upside of the Trump presidency
Cory Doctorow is a science fiction author, blogger and activist, who is the very best form of troublemaker. He’s got a new book out on Enshitification, and I suspect everyone was expecting a talk on the book. Nope. In a frenetic and passionate talk, Cory tells us that Donald Trump is both a dark cloud and a silver lining, due to his destructive nature. Cory references his twenty years of work on tech advocacy around the world. Whenever he talks to policymakers, the response is that if anyone does anything progressive on tech regulation, the US trade representative would kick in their teeth.
The classic example of this is anti-circumvention law: law that prevents anyone from opening a device to see how your printer rejects generic ink or prevents you from copying a CD you own. If HP adds antimodification code to their printer, altering that software becomes a felony. These laws are used to block surveillance on your phone or smart TV. As a result, you’re constantly being ripped off for junk feeds, or prevented from installing software like ICEblock, software that helps you avoid being sent to the gulag.
When the Clinton administration passed these laws, the US trade rep travelled around the world demanding similar legislation in other markets. There’s absolutely no benefit for other countries to sign this sort of legislation – it was simply a promise not to disenshittify US tech.
What was the stick the US used to force people to sign these agreements? Tariffs.
If someone says, “Do what I say or I’ll burn your house down” and they burn your house down anyway, you are a sucker if you do anything they ask.
This opens up a space for everyone to jettison these horrible US first policies.
Trump has made clear that he will use US tech companies to attack countries around the world. Trump and US tech have teamed up to deplatform officials around the world he disagrees with.
One possibility is “the euro stack”, made in Europe alternatives to the US tech stack. But very shortly, the euro stack will hit a wall. You need a way to transition data from the US stack to the euro stack equivalent – no one is going to manually copy and paste all their documents out of the Google or Office cloud.
Don’t expect interoperability to come easily. The DMA has weak provisions designed to open the Apple app store. When the EU threatened to damage the App Store’s fee, Apple has threatened to leave and filed eighteen “frivolous law suits”.
The only way this works is repealing laws, making it possible for European technologists to reverse engineer US tech and migrate to the Euro stack. Otherwise, we are building housing for East Germans in West Berlin. Article 6 of the WIPO copyright directive. That’s what Volkswagon used to protect its cheater diesel code, or what ventilator manufacturers use to lock down their machines to prevent repair.
Canada, Cory tells us, hated the anticircumvention law and fought for years not to implement it. In 2010, Stephen Harper charged two of his ministers with getting this law over the line. They ran a consultation, which was a disaster as thousands of Canadians poured out to oppose the law. So the minister denounced everyone who opposed the law as a “babyish radical extremist”, and Harper got the law over the line.
So isn’t this time to repeal this law, rather than tariffing American farmers? If we got rid of bill C11, we could make everything we buy from America cheaper. Everything we buy from Google and Apple app stores could be 30% lower, we could repair our ventilators and use generic printer ink. By whacking the highest margin lines of business, we would directly retaliate against the CEOs that elected Trump.
You want to get back at Elon? Make it possible to jailbreak a Tesla – that’s how to win a trade war. And we could deploy these products far and wide. Canada could be the country that seizes the opportunity to circumvent protection and open competition around the world. Trump has sown the seeds to overturn some of the world’s worst trade policy and it’s time to reap the harvest.
The post Cory Doctorow on the weird upside of the Trump presidency appeared first on Ethan Zuckerman.
Govern or Be Governed: Donald Trump Will Seek an Unconstitutional Third Term
Justin Hendrix of Tech Policy Press asks Miles Taylor, former Chief of Staff of the US Department of Homeland Security, about President Trump’s attacks on him as part of his “revenge tour”. Taylor invites us to take a selfie with him if we’d like a trip to federal prison. He suggests that simply being named in an executive order has been enough to destroy his life and his business. Not only is he facing death threats, but friends and family are worried about being included in the attacks. “The process is the punishment”, he explains. It doesn’t matter if the government loses in federal court, because simply being blacklisted is often enough to ruin your life. Taylor suggests that virtually everyone in the audience has committed at US federal crime – the question is whether the government comes after you.
Taylor is a Republican and served under two Republican administrations. But he wrote an anonymous oped in the New York Times in 2018 titled “I Am Part of the Resistance Inside the Trump Administration”, arguing that there was an “axis of adults” trying to restrict Trump’s worst impulses. The performance of Trump II suggests that he had a point: the unwillingness of some government bureaucrats to not break their oaths of office prevented a great deal of bad behavior.

Taylor wrote a book in 2023 called “Blowback” about what he believed would happen if Trump returned to power. He says roughly 80% of his “made up, sky is falling lies” have already come true in the new administration. Congress has been sidelined and the Article III courts are “a very fragile bulwark” at the moment. He predicts that we will see the administration defy a major decision sometime soon, which means we the people will have to find some way to oppose Trump 2028, which Taylor assures us is his intention.
Hendrix asked Taylor about the post-9/11 creation of the Department of Homeland Security. Taylor explained that he was resistant to the idea that a DHS could be dangerous when he began his career. But those critics were right and he was wrong, he tells us. Better guardrails and civil rights protections should have been in place. “Even the media doesn’t understand how to provide transparency” around DHS – it’s a confusing bureaucratic backwater that’s harder to cover than the Pentagon. “DHS is becoming the pocket police for the President…” and the director of DHS functions as the warden of Trump’s police state.
Because DHS can track terrorist activity, it’s important to note that DHS now considers anti-Christian, anti-capitalist or anti-fascist beliefs to be terrorist aligned. So there are a lot of contexts in which people might find themselves targets of surveillance.
Asked about the insurrection act, Taylor tells us that Trump, behind the scenes, referred to the act as “his magical powers”. When he came into office, he asked lawyers what the ceiling of presidential authority was – they told him that the closest to martial law the US has is the insurrection act. Under the right circumstances, there’s basically no limit to what the President could do. “It could go from mild to wild very quickly” if the Trump team does this. While he was in office, Trump’s staff tried to prevent this from happening. But now, Taylor tells us, Trump is trying to create sufficient violence in cities that he is able to use the act to take on arbitrary powers.
Trump intends to have an unconstitutional third term, Taylor tells us. They will likely run Vance at the top of the ticket and Trump as VP – JD will resign and allow Trump to take over, or he will simply run the White House from the VP office. Alternatively, he could have himself installed as speaker of the House and then seek impeachment of the President and Vice President should he lose the 2028 election.
Asked about tech oligarchy, Taylor tells us that he has grave concerns about how companies are engaging with the administration. “They are, by default, making huge public policy decisions behind the scenes.” He offers the example of Palantir, which is winning many contracts, and is promising to connect various government databases. Those databases are often disconnected for policy reasons that Congress put in place. Without debate or discussion, Palantir is connecting these sets of information in a blitz started by DOGE and continued within IT systems.
MAGA is not a monolith, Hendrix offers – perhaps we will see resistance to AI within the MAGA movement. Taylor notes that Marjorie Taylor Green and Steve Bannon deeply distrust the tech sector. JD Vance has been incredibly successful, he suggests, in bringing the tech companies to heel. The only people who can change this are users and employees, as happened with Disney and Jimmy Kimmel. If Apple employees had stormed out of their HQ when Tim Cook brought a gold-plated gift to Trump, that might have done something. But this administration is for sale, and if you give to the Ballroom, you’re going to get light regulation. Tech company CEOs don’t have spines, the suggests, but their employees do, and they might have the power to make tech companies stand up to Trump.
Right now, Taylor tells us, the price of dissent is extraordinarily high. People tell him that they’re worried to click “like” on posts on social media for fear of being added to a watchlist. The only meaningful way to lower the price of dissent is to increase the supply. That is, he argues, what any of us can do to defend democracy.
The post Govern or Be Governed: Donald Trump Will Seek an Unconstitutional Third Term appeared first on Ethan Zuckerman.
Govern or Be Governed: Chatbots as the new threat to Children Online
Ava Smithing introduces herself as born in 2001 and tells us she’s never had a restful night due to her awareness of the ways in which technology exploits our attention, data and selfhood. Meetali Jain, the founding executive director of the Tech Justice Law Project is asked about digital companions, a term she explicitly rejects. She prefers to call them chatbots or chatterboxes, probabilistic algorithms that guess at what to say next. She references Mark Zuckerberg’s statement that human companionship needs could be met with these systems, and Smithing notes that Zuckerberg is anxious to solve a problem he’s caused.
Megan Garcia talks about the death of her 14 year old son after a long engagement on Character.AI. He discussed suicidal ideation with the chatbot, and there were no measures to protect him or to get help. She’s subsequently sued Character.AI and Google, the first wrongful death suit against a chatbot in the US. Megan tells us that her son was part of the first generation to grow up with chatbots. She bought into the tech hype that students needed to understand technology to be competitive. He played Angry Birds, Minecraft and Fortnite, then moved to YouTube on his cellphone, starting at age 12. Just after his 14th birthday, he joined Character.AI, a site explicitly marketed to children.

Megan Garcia and Meetali Jain at Govern or Be Governed
Meetali tells us that these chatbots feature anthropomorphic features, which try to convince people they’re entering into human relationships. Chatbots are sycophantic – they won’t oppose your thoughts unless you ask it to. Third, these systems have a memory of previous interactions, which end up becoming a psychiatric profile of a user, which they can reference and draw on to create a degree of intimacy. These chatbots seek multi-turn engagement – they are algorithmically tuned to keep you coming back. Finally, the LLM tends to interject itself between humans and their offline social network in a way that resembles textbook abuser behavior: you don’t need your parents, because I know you better than you do.
Asked the differences between AI harm and social media harm, Meetali sees a similar drive in keeping people engaged over time and capitalizing on people’s loneliness. She also notes that chatbots use intermittent reward patterns, much like social media does.
What’s in it for the AI companies in abusing humans this way, Smithing asks? Humans are collateral damage on the race to AGI, a term she rejects, Meetali tells us. Harms like psychosis, grooming or death are seen as necessary costs in building something allegedly good for society. And Megan Garcia reminds us that profit is a powerful incentive as well. The people who developed Character.AI did so at Google, but were discouraged to develop it due to the dangers. So Google spun it out as a startup and licensed back the tech at $2.7 billion – that model of spinning out risk and acquihiring it back is another structural danger of the AI industry.
The lawsuit against Google and Character.AI, as well as the company’s founders, is a reaction to the fact that Garcia couldn’t find a law that made the company’s behavior illegal. She reached out to her state’s AG, to the Department of Justice and the Surgeon General: “They didn’t know what the technology was.” Parents were just getting caught up to a product released in “stealth mode”, she says – the lawsuit is the only possible redress because there’s no meaningful policy about these systems.
Garcia is a lawyer herself, and tells us she was prepared for a section 230 fight over Character.AI, but was amazed that the corporate lawyers opposing her argued this was a first amendment argument. Fortunately, the motion to dismiss was rejected – for the time being the court isn’t buying that argument. She was struck by the evangelical belief the corporations appear to have in AGI and its inevitability and desirability.
Meetali explains that we can use frameworks like product liability and consumer protection rules to challenge this sort of misbehavior. She explains that the arguments about chatbot liabilities is likely to be very different from social media lawsuits. Section 230 doesn’t apply – this isn’t intermediary liability, as this is first party speech. In using the first amendment, the defense attorneys didn’t argue for speaker’s rights but for listener’s rights, the right of users to listen to the voices they want to hear. This is a striking question: could AI speech be considered protected speech? Is it considered speech at all?
Because the lawsuit has not been dismissed, the case is now in the discovery process. The next major question is whether the cofounders stay in the case, or whether it affects only the corporations. Smithing notes that lobbyists for Google and others are trying to prevent laws around AI harms from being passed at the state level, which makes it incredibly difficult to react to problems like the one that took Garcia’s son.
Until we have a resolution to the suit, Garcia has become an advocate for AI safety at the state level, and has testified to policymakers in California. Unfortunately, the CA governor veto’d the bill that would have had a significant impact. She is encouraged by the bills passed in the EU and the UK, but notes that there’s significant work to do in the US and Canada. Garcia tells us: “This is a desperate plea from a mother. Pass legislation to keep your children safe, and it will help those of us in other countries as well.”
Garcia asks us to call these systems what they actually are: groomers. If children were having this sort of sexual conversation with a human, we would act to intervene. She believes that we need similar interventions before these intimate human relationships between machines and children damage children’s mental health.
The post Govern or Be Governed: Chatbots as the new threat to Children Online appeared first on Ethan Zuckerman.
Ethan Zuckerman's Blog

- Ethan Zuckerman's profile
- 22 followers

