Benchmarking Producer/Consumer in Akka
Further to this conversation on the Akka mailing list, I decided to benchmark various different approaches to implementing the producer/consumer pattern.
I wanted to choose a “real” problem, so I decided to count the words on the first 100,000 pages of Wikipedia. The producer parses the Wiki XML dump and the words are counted page-by-page by a pool of consumers.
I implemented three different approaches – producer pushes to a bounded queue, producer pushes to an unbounded queue together with a flow control protocol, and consumer pulls.
The source code for the different implementations is here, and the results are at the bottom of this message.
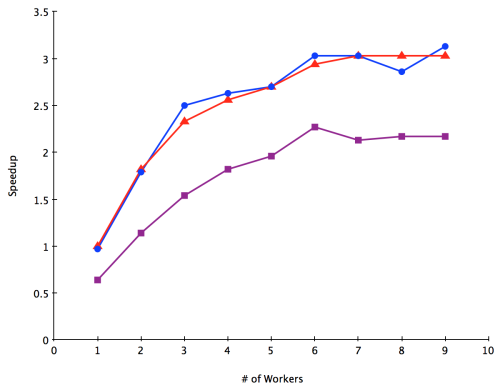
Some observations:
I only timed to the nearest second as I see an approx. 3 second variation from run to run with identical parameters. I’m not sure why I see such a large variation—suggestions welcome.
There’s basically no difference between the two “producer pushes” implementations. The “consumer pulls” implementation is much slower, however
I tried both Dispatcher and BalancingDispatcher and RoundRobinRouter and SmallestMailboxRouter in the producer pushes implementations—the differences were too small to measure
I’m surprised that there is so much difference between producer pushes and consumer pulls. It’s quite possible that I’ve done something stupid in the implementation—I’d be very grateful for a pointer to what it is.
Here are the results (all on my i7 MacBook Pro—4 cores, 2 hyperthreads per core).
Bounded
Unbounded
Pull
Consumers
Seconds
Speedup
Seconds
Speedup
Seconds
Speedup
1
100
1.00
103
0.97
156
0.64
2
55
1.82
56
1.79
88
1.14
3
43
2.33
40
2.50
65
1.54
4
39
2.56
38
2.63
55
1.82
5
37
2.70
37
2.70
51
1.96
6
34
2.94
33
3.03
44
2.27
7
33
3.03
33
3.03
47
2.13
8
33
3.03
35
2.86
46
2.17
9
33
3.03
32
3.13
46
2.17