
Andrea Leopardi's Blog
April 27, 2025
How to Async Tests in Elixir
Recently, I've been focusing a lot on the health of our test suite at Knock. Fast, reliable tests are a boost for confidence and developer happiness, so I naturally care a lot about this. I've been wrestling with two main things: slow tests, and flaky tests. My sworn enemies.
The good news here is that I believe that the "solution" to both these issues are proper, robust asynchronous tests. When tests are asynchronous, single tests can even be somewhat slow because you have ways to overcome that. You can scale horizontally with more parallel tests, more cores, and so on. You can split up test cases and parallelize slow tests even more. What about flakiness? Right. In my experience, so much of the flakiness comes from either improperly-written asynchronous tests or slow timeouts and assertions on messages. Go fix the latter, I have no silver bullet for that.
This post is about beautiful, elegant, robust asynchronous tests in Elixir. It's also a kind of ode to OTP concurrency and about parallel-forward thinking and maybe some other made up words.

First of all, throw tests for pure code out of the window. We don't care about those. Say I have a function that checks if a string is valid base64 data:
defvalid_base64?(string)do match?({:ok, _},Base.decode64(string))endNothing that has to do with testing it in parallel here. This has no side effects. It's as pure as the eyes of a golden retriever puppy. Test this in parallel to your heart's desire, even though I doubt this is the kind of tests that are making your test suite slow.
So, side effects are what make it hard to turn tests async? Yeah, in some way. That, but in particular singletons. We'll see in a sec, let's go through why some side effects are easy to test in parallel.
Maybe you want to test a function that writes something to a file. Writing to the filesystem is a side effect, no doubts, and a destructive kind (the scariest kind!). But, as long as you're smart about where to write, you can kind of get away with it:
test "writes output to a file"do filename ="#{System.unique_integer([:positive])}.txt" output_path =Path.join(System.tmp_dir!(), filename)MyMod.calculate_something_and_write_it(output_path)end[!warning] Don't do this at homeUse ExUnit's tmp_dir tag. It cleans up for you and it's nicer and it protects kittens (probably).
Cool, you can run many of these tests in parallel and they won't step on each other's toes, even though the system under test is all about the side effect.
Singletons Are the Bane of Async TestsBack to singletons. A singleton is something which you have a single instance in your system. Those are hard to test. You want an example that you probably know about? I'll give you one. That sick, deprived Logger. Yucksies. Logger is a singleton in the sense that you usually only log to stdout/stderr and use ExUnit.CaptureLog functions to assert on logged content. But if two pieces of code log at the same time���because spoiler, it's two tests running concurrently and executing some code that logs something���:vomiting_face:. Who captures what. It's undeterministic (well until you have to patch a hotfix in production, then it's whatever makes at least one of the tests fail in CI).
You're likely to have an assorted, colorful bunch of other singletons in your system. The GenServers ticking every few seconds and doing godknowswhat���. The ETS tables doing the cachin'. You know the ones.
But fear no more, there is a fix for almost all situations. It's based on LLMs, agentic processing, and the power of AI. Nah just kidding, it's ownership (plus getting rid of singletons, lol).
The getting-rid part first.
No More SingletonsDesign your processes and interfaces and applications so that singleton-ness (singleton-icity? singleton-ality?) is optional. Say I have a process that buffers metric writes to a StatsD agent so as to be Very Fast��� and out of the way of your system.
defmoduleMetricsBufferdouseGenServerdefstart_link([]= _opts)doGenServer.start_link(__MODULE__,:no_args,name:__MODULE__)enddefincrement_counter(name)doGenServer.cast(__MODULE__,{:metric,:counter, name})end# ...@implGenServerdefhandle_cast({:metric, type, name}, state)do{:noreply, buffer_metric(state, type, name)}endendBad news: that's a singleton if I've ever seen one. The sneaky name: __MODULE__ is the culprit. If you register the process with a (very "static") name, and then cast to it by name, then there can only be one of those processes in the system. If two concurrent tests emit a metric through MetricsBuffer, you just lost the ability to test those metrics as you'll have unpredictable results depending on the order those tests execute stuff in.
I don't know of a perfectly clean way to solve this. "Clean" in testing usually involves stuff like "don't change your code to make tests easier" and stuff like that. I'd rather have some test code in there and write tests for this, then to not write tests altogether, so let's power through.
De-singleton-ifyingThe simplest approach to take in these cases, in my opinion, is to make your singleton behave like a singleton at production time, but not making it a singleton at test time. You'll see what I mean in a second.
defmodule MetricsBuffer do use GenServer- def start_link([] = _opts) do def start_link(opts) do- GenServer.start_link(__MODULE__, :no_args, name: __MODULE__) name = Keyword.get(opts, :name, __MODULE__) GenServer.start_link(__MODULE__, :no_args, name: name) end- def increment_counter(name) do def increment_counter(server \\ __MODULE__, name) do- GenServer.cast(__MODULE__, {:metric, :counter, name}) GenServer.cast(server, {:metric, :counter, name}) end # ... endNow, you're making the GenServer name optional and defaulting to __MODULE__. That's what it'll use in production. In tests, you can start it with something like
setup context do server_name =Module.concat(__MODULE__, context.test) start_supervised!({MetricsBuffer,name: server_name}) %{metrics_server: server_name}endNice, but there are some issues. The main one is that you have to explicitly reference that new name everywhere in your test case now. But you might not be testing the public API for MetricsBuffer directly���maybe your code-under-test is calling out to that. How do you pass stuff around? Turns out, you combine this technique with ownership.
Ownership async: true = :heart:First, a few words to explain what I���m talking about. The idea with ownership is that you want to slice your resources so that each test (and its process) own the resources. For example, you want each test process to "own" its own MetricsBuffer running instance. If the owned resources are isolated from each other, then you can run those tests asynchronously.
There are a few ways you can build ownership into your code. Let's take a look.
At the Process Level: nimble_ownership and ProcessTreeOwnership (in this context) is essentially always at the process level. Each test process owns the resource. However, the important caveat is that you often want "child processes" of the test process to be allowed to use the resource too. Basically, you want this to work:
test "async metrics"doTask.async(fn-># ��� Should still use the metrics server owned by the test process code_that_reports_metrics()end)endwithout necessarily passing the MetricsServer around (which is often a pain to do). There's a pretty easy solution that, however, requires you to modify your MetricsServer code a bit.
ProcessTreeI���m talking about a library called process_tree. Its job is pretty simple: it looks up keys in the process dictionary of the current process and its "parents". A short example:
Process.put(:some_key,"some value")task =Task.async(fn->{Process.get(:some_key),ProcessTree.get(:some_key)}end)Task.await(task)#=> {nil, "some value"}This "parent lookup" is based on a few features of OTP, namely the :"$callers" process dictionary key that many OTP behaviours use as well as :erlang.process_info(pid, :parent). This turns out to be pretty reliable.
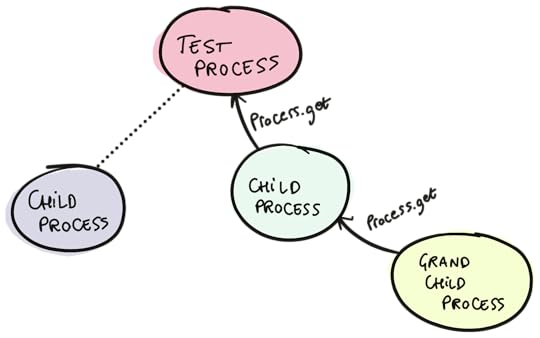
Now, the trick to have async tests here is to store the PID of the metrics server (or whatever singleton) in the process tree of your test process. Then, every "child" of your test process has access to this. In my opinion, a nice way to do this is to just slightly modify the MetricsServer code:
defmoduleMetricsServerdodefstart_link(opts)doGenServer.start_link(__MODULE__,:no_arg,Keyword.take(opts,[:name]))enddefincrement_counter(name)doGenServer.cast(server(),{:metric,:counter, name})end# ...ifMix.env()==:testdodefpserverdoProcessTree.get({__MODULE__,:server_pid})endelsedefpserverdo__MODULE__endendendThe idea is that you start your server with name: MetricsServer in your application supervisor. In tests, instead, you do:
setup do pid = start_supervised({MetricsServer,[]})Process.put({MetricsServer,:server_pid}, pid):okendVoila! You have Solved Async Tests���.
Now, if you're worried about whether this is a "clean" solution, I get it. However, let's think through this a sec. What is it that you're doing in production that you're not testing here? I'd argue it's only the name resolution. In production, you're not testing that __MODULE__ name registration works... But that's OTP, so I trust that.
Now, ProcessTree falls short when you want to have utilities that test something about the owned resource after the test is finished. This is somewhat a common use case. The prime example is Mox. In Mox, you want to assert that the expected number of calls were received during the test, but after the test is done. Mox uses a on_exit hook for this, but when on_exit runs the test process has already exited... We need to store these expectations outside of the test process, and be able to retrieve them after the test is done. We need a resource that outlives the test.
Enter nimble_ownershipnimble_ownership is a small library that we extracted out of Mox itself. Its job is to provide an "ownership server" and track ownership of resources across processes.
The ownership server can store some metadata for a given process. Then, that process can allow other processes to access and modify that metadata.
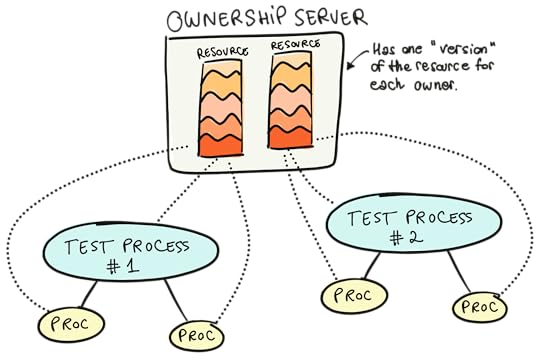
You might see how Mox uses this. Mox starts a global ownership server when it starts (Mox.Server) and stores expectations for each function in each mock module, for each process that calls Mox.expect/4. A simplified implementation could:
Store a list of {mock_module, function_name, implementation} tuples.Whenever there's a call to a function in the mock module, the mock module (which is implemented by Mox) would find the tuple for the right mock module and function, and "pop" the implementation.Then, you'd allow other processes (like child processes) to use the mocks. The server would do something like:
defmoduleMyMoxdodefstart_linkdoNimbleOwnership.start_link(name:__MODULE__)enddefexpect(mod, fun, impl)doNimbleOwnership.get_and_update(__MODULE__, _owner = self(), _key =:mocked_functions,fn current_value -> new_value =(current_value ||[]) [{mod, fun, impl}]{new_value,:unused_return_value}end)endendThen, the generated mock modules could do something like:
defmy_mocked_fun(arg1, arg2)do{:ok, owner}=NimbleOwnership.fetch_owner( _ownership_server =MyMox,[self()| callers()],:mocked_functions) impl =NimbleOwnership.get_and_update(MyMox, owner, _key =:mocked_functions,fn current_value -> pop_implementation(current_value)end) apply(impl,[arg1, arg2])enddefpcallersdoProcess.get(:"$callers")|| parents(self())enddefpparents(pid)docaseProcess.info(pid,:parent)do{:parent,:undefined}->[]{:parent, parent}->[parent | parents(parent)]endendThe key thing here is that mock implementations are not tied to the lifecycle of the test process, nor is the ownership server. So, when the test process has exited (like in an on_exit hook), you can still access the owned resources for that exited test process and perform assertions on those.
This whole ownership thing is not super straightforward, but the nimble_ownership documentation does a good job at explaining how it works. Also, you can go dig into the Mox implementation to see how it uses nimble_ownership.
Now, there's another way of doing process-based ownership that you've likely been using.
At the Database Level: TransactionsEcto is probably the best-known example of tracking ownership. Ecto calls it the sandbox, but the idea is quite similar. First, why this is an issue: the database is, in its own way, shared state. Say you had:
A test that selects all rows from table accounts.Another test that inserts a row in the accounts table.Test #1 would sometimes see the new from test #2 and sometimes not. Flaky test.
So, instead of tracking a resource like a nimble_ownership server or similar, the Ecto sandbox tracks a database transaction. All DB operations in a test and in the allowed processes for that test run in a database transaction, that gets rolled back when the test finishes. No data overlap!
Ecto implements its own ownership mechanism, Ecto.Adapters.SQL.Sandbox, but the ideas are the same as the ones we discussed in this post.
At Other Levels: WhooopsieThere are some singletons that you cannot get out of having. We already mentioned Logger, for example. You could get clever with ownership-aware logger handlers and whatnot, but that's not the only common one. Another frequent suspect is Application configuration. If your code reads values from the application environment, then testing changes to those values makes it impossible to run those tests asynchronously:
deftruncate_string(string)do limit =Application.get_env(:my_app,:truncation_limit,500)String.slice(string,0..limit)endtest "truncate_string/1 respects the configured limit"do current_limit =Application.get_env(:my_app,:truncation_limit) on_exit(fn->Application.put_env(:my_app,:truncation_limit, current_limit))end) string =String.duplicate("a",10)Application.put_env(:my_app,:truncation_limit,3) assert truncate_string(string)=="aaa"endThis dance is pretty common. Get the current value, make sure to set it back after the test finishes, and then change it to test the behavior. But you can see how another concurrent test changing that value would potentially break this test.
So, what are you to do in these cases? Tough luck. There's no satisfaction here. The most successful practical approach I've seen is to define an interface for Application and use mocks to have values read/written in an async-friendly way. You can use Mox, you can use Mimic, whatever floats your boat really. Just go read The Mox Blog Post first.
Practical AdvicesJust a bunch of jotted-down advices:
Hardcoded singletons are "clean" from a code perspective, but so hard to work with. Make your life easier, and think like a library author when you can: no singletons, just configurable processes. Then, these can act as a single global resource if needed.Try to start with ProcessTree rather than nimble_ownership. The ownership idea is powerful but quite more complex than just climbing up the process tree to find a PID.Abstract as much as possible into your own testing helpers. At Knock, we have quite a few MyApp.SomePartOfTheAppTesting helpers that we use in our tests. This facilitates abstracting what to store in the process dictionary, key names, and so on.ConclusionWoah, that was a lot.
First, a short acknowledgement. I've got to thank my coworker Brent, who put me onto ProcessTree and who I've designed much of what I've talked about with.
We started with what the common issues that prevent asynchronous tests are. Then, we explored solutions for:
Limiting singletons in your system.Using ProcessTree to track resources back to a test process.Establishing resource ownership with nimble_ownership (or Ecto's sandbox).Using mocks as the last resource.Some resources to check out:
I spoke about some of these topics a few years ago���the talk is more philosophical and high level than this post, but might be helpful. Testing Elixir , which goes into more detail on some of the things we discussed.I hope this all made sense. If I can help clarify anything, leave a comment or throw an email my way. See ya!


December 30, 2024
Tech I Use �����2024
Other people do this. I assume, because only Louis' post popped up in my timeline, but hey, one's enough.
I've never done a write-up on stuff I use, but I'm a sucker for reading this kind of posts, so I figured I'd join in on the fun. Here's to this becoming a yearly tradition.
By the way, an up-to-date list is always available at my /uses page.

I mostly type away at my desk. I've used a 2021 14" M1 MacBook Pro for most of this year (and the past three). It works fantastic. For work, I now switched to a 16" M4 MacBook Pro. It's mostly the same, but the nanotexture anti-glare display thing��� Eye-watering stuff.
I mostly keep the laptop hooked up to a 32" external monitor, the BenQ PD3205U. I love this thing to death. I can plug a single USB-C cable and I get a big 4K screen, charging, more ports, all in one go. Had this for a year-ish, can't see myself switching for the foreseeable future.
This year my wife and I moved out of our house and are temporarily hanging out in temporary accommodations, so my setup is not as good as it used to be (it'll be again soon). I'm not using my nice R��de desk mic for meetings these days. I do use a Logitech MX Brio webcam though���another lovely piece of tech.
I quietly type on an Apple Magic Keyboard. I do not need another hobby. I've used this thing for, I don't know, 4-5 years? Anyway it has Touch ID��� and the keys have short travel. I am very fond of both those things.
A couple months back I upgraded from an older iPad Air to a 13" M4 iPad Pro. What a lovely device. It's too thin, but man it's cool. I draw a lot of my "educational" stuff on there, illustrations for my blog and book(s), and whatnot. I watch all the media I watch on there. I read papers on there. Also got a keyboard for it now���not the Apple one though. The Apple one is silly IMO, because you cannot get your iPad to stand (ever watched a movie or something!?) without the keyboard in the way. Take away the keyboard, and you have no case��� and no way to get the iPad to stand. Cool. I got a Logitech Combo Touch instead. It does both things. At least it's still expensive, so you get that Apple feeling uh.
Headphones are still the same as they've been for the past few years. AirPods Max (in black) at the desk, and AirPods Pro 2 or whatever version for going around. AirPods Pro are my favorite piece of tech ever, I carry them everywhere.
SoftwareI have a particular type of love for software and apps and whatnot. This list would change all the time, but here's my end-of-2024 snapshot, in no particular order.
Apple Mail for email (Fastmail for personal, GMail for work). It works and I don't get enough email to need anything fancier. Fantastical for calendars. Love it. I use the "openings" feature quite a bit. Todoist for tracking tasks. This last one is a recent entry���I switched in late 2024, coming from Apple Reminders. Apple's apps are generally good, but I want my tasks to be readable from other apps (see Obsidian) and whatnot, so there ya go.
Some easy ones: I still listen to music on Spotify, and I still store passwords in 1Password.
This year I switched from Safari to Arc for browsing the interwebs. I like it. I also recently switched to Ghostty for my terminal, coming from iTerm. Super nice but not a big difference for someone like me, since I use VS Code's terminal 95% of the time.
I started using Raycast over Alfred this year too. Plugin ecosystem is nicer. I don't want to pay $9/mo or however much it is for their pro subscription (I can't justify it), but that leaves me without sync across computers, which is annoying. We'll see what sticks.
I still use:
VS Code for writing software. I like it.Obsidian for taking notes. I love it.Notion for storing DB-like information. I keep a home inventory here, info about my car and whatnot, and all that sort of stuff. I find it to work better than Obsidian, easier to share pages with my wife (like our dog's info), and I don't know, I can't seem to get out of it.September 3, 2024
Reducing Compile-Time Dependencies in Gettext for Elixir
The Elixir compiler does what most modern compilers have to do: it only recompiles the files it needs to. You change a file, and the compiler figures out all the files that somehow depend on that file. Those are the only files that get recompiled. This way, you get to avoid recompiling big projects when changing only a few files.
All good and nice, but it all relies on files not having too many dependent files. That's what was happening with Gettext, Elixir's localization and internationalization library. This post goes through the issue in detail, and how we ended up fixing it.

Jos�� and I started Gettext for Elixir in March 2015, so close to ten years ago at the time of writing. Back then, writing Elixir was different. We didn't think too much about generating a lot of code at compile time, inside macros and use calls.
The way Gettext has worked for most of its lifetime has been this. Users created a Gettext backend by calling use Gettext within a module in their application:
defmoduleMyApp.GettextdouseGettext,otp_app::my_appendThat little line of code generated a whopping twenty-one macros and functions in the calling module. Users could call those macros to perform translation:
importMyApp.Gettextgettext("Hello world")Gettext backends read .po and .pot files containing translations and compile those translations into pattern matches. Every time you add or change a translation, the Gettext backend needs to be recompiled. I wrote a whole blog post about how Gettext extraction and compilation work, if you're curious.
This works pretty straightforward overall. However, calling those Gettext macros creates a compile-time dependency on the imported backend. Just importing the backend doesn't, as that's what the Elixir compiler calls an export dependency���the difference is explained in mix xref's documentation.
This makes sense: if a module changes, we want to recompile modules that use macros from it too, as those macros are expanded at compile time. The main issue arose with Phoenix applications. By default, Phoenix has a MyAppWeb module for boilerplate code that you want to inject in controllers, views, and whatnot. For controllers, live views, live components, and views, the generated code included this:
importMyAppWeb.GettextYou could use *gettext macros everywhere this way. Maybe you can already see the issue: everything using Gettext macros would have a compile-time dependency on the backend. Uh oh. Take a look at this: I generated a new Phoenix app (mix phx.new my_app), added gettext/1 calls to all controllers and views, and then used mix xref to trace all the files that have a compile-time dependency on MyAppWeb.Gettext.
$ mix xref graph --sink lib/my_app_web/gettext.ex --label compilelib/my_app_web/components/core_components.ex��������� lib/my_app_web/gettext.ex (compile)lib/my_app_web/controllers/error_html.ex��������� lib/my_app_web/gettext.ex (compile)lib/my_app_web/controllers/page_controller.ex��������� lib/my_app_web/gettext.ex (compile)lib/my_app_web/controllers/page_html.ex��������� lib/my_app_web/gettext.ex (compile)Yuck! In an app with tens of controllers and views, the list above gets a lot longer. But worry not, we fixed this.
The FixWe do need to generate something in Gettext backends: the actual translations pattern matches. Gettext generates two important functions to handle that in each backend, lgettext and lngettext. lgettext's signature looks like this:
deflgettext(locale, domain, msgctxt \\nil, msgid, bindings)The generated clauses are a bunch of these:
deflgettext("it","default",nil,"Red", _bindings),do:"Ross"deflgettext("it","default",nil,"Green", _bindings),do:"Verde"deflgettext("it","default",nil,"Yellow", _bindings),do:"Giallo"# ...and so onWell, after thinking about it for a bit, we realized that this is all we need from a Gettext backend. We don't need all the macros we generated in them, or the translation-extraction feature (we can do that outside of the backend). We just need the backend to hold the compiled patterns for the translations.
So, Jonatan (one of the maintainers of Gettext for Elixir) came up with an initial API where we would not have to import Gettext backends:
defmoduleMyApp.GettextdouseGettext,otp_app::my_appenddefmoduleMyApp.GreeterdouseGettext,backend:MyApp.Gettextdefsay_hello,do: gettext("Hello")endThis was the right direction, but we needed to actually implement it. After refining and iterating on the API for a while, we came up with a re-hauled solution to using Gettext. It goes like this.
First, you use Gettext.Backend (instead of just Gettext) to create a Gettext backend:
defmoduleMyApp.GettextdouseGettext.Backend,otp_app::my_appendVery clear that you're defining just a backend���or a repository of translations, or a storage for translations, or however you want to think about this. The Gettext backend just exposes lgettext and lngettext (which are documented callbacks now).
Then, you have Gettext.Macros. This is where all those *gettext macros live now. There's a variant of each of those macros suffixed in _with_backend which now explicitly takes a backend as its first argument. So, no magic here anymore:
Gettext.Macros.gettext_with_backend(MyApp.Gettext,"Purple")#=> "Viola"Not super ergonomic though. So, we also have "normal" gettext macros. These infer the backend from an internal module attribute, that you set by using the original API proposed by Jonatan:
defmoduleMyApp.GreetingdouseGettext,backend:MyApp.Gettextdefsay_hello,do: gettext("Hello")endThat's it! gettext/1 here does not come from the backend, it comes from Gettext.Macros, which is never recompiled (it comes from a dependency after all). Walking backwards, the code above roughly translates to:
defmoduleMyApp.Greetingdo@gettext_backendMyApp.Gettextdefsay_hellodoGettext.Macros.gettext_with_backend(@gettext_backend,"Hello")endendIn turn, say_hello/0's contents more or less expand to:
defsay_hellodoif extracting_gettext?()do extract_translation(@gettext_backend,"Hello")end# This finally calls @gettext_backend.lgettext/5 internally:Gettext.gettext(@gettext_backend,"Hello")endGettext.gettext/2 calls the backend's lgettext/5 function "dynamically" (akin to using apply/3), which does not create a compile-time dependency!
That's the trick. At compile-time we can still extract translations, as we have to recompile the whole project anyway to perform extraction. However, now adding translated strings to PO files only causes the Gettext backend to recompile���and not all the files that use macros from it. You can verify this in a new Phoenix app generated with phx_new from main (I also added gettext/1 calls to the same controllers and views as the previous example):
$ mix xref graph --sink lib/my_app_web/gettext.ex --label compile# Prints nothing hereFantastique.
ConclusionWhen working on libraries that do compile-time work and use macros, or do other weird stuff, think about this stuff. We didn't, and it took us a while to figure it out. If you want to do some spelunking through the changes, here's a list of stuff to look at:
The original Gettext issue.This Gettext PR and this other Gettext PR.The PR that updates Phoenix generators to use the new Gettext API.Lesson learned!
November 28, 2023
Verifying JWTs from Apple's App Store
If you've ever had to interact with Apple APIs related to App Store purchases and whatnot (like the App Store Server Notifications), there's a chance you had to verify JWTs at some point. I had used, signed, and verified JWTs extensively before this, but Apple uses a bit of a unique way of signing their JWTs that I had never stumbled upon in the past. In this short post, I'll show some code around verifying Apple's JWT signatures in Elixir.

At Veeps, we're working on some features connected to the App Store. This involves verifying that the notifications (webhooks) that Apple sends to us are legitimate.
One note before we start: I'm using the term JWT here mostly out of ignorance and out of desire to bump this blog post's ranking in search engines! What Apple sends to us is a JWS (JSON Web Signature). JWTs are the payload that ships inside a JWS. RFC 7519 is the one you want to take a look at if you want to know more about this. Anyway, minutiae.
Let's first have a look at the general idea of how Apple signs these JWTs. After that, we'll look at some Elixir code.
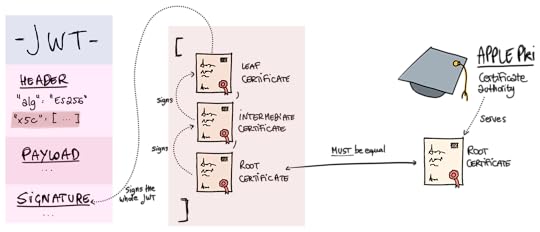
The deal with Apple's JWTs is that they are signed via certificates rather than via symmetric or asymmetric signatures. Essentially, Apple signs the JWT's payload with a private key. Then, they include the public key for that in a DER certificate in the JWS itself (the "leaf" certificate). That certificate is itself signed by an intermediate certificate, which in turn is signed via their root certificate. The root certificate and intermediate certificate are public and available through Apple's certificate authority (Apple PKI).
 Some Elixir Code
Some Elixir CodeYou technically don't really need any third-party Elixir/Erlang libraries for this, but I opted to use two nimble and widely-used ones:
JOSE is a foundational Erlang library (with an Elixir API as well) that implements many of the components described in the series of RFCs around JOSE (Javascript Object Signing and Encryption). I've used this library many times in the past for signing and verifying JWTs.
X509 is an Elixir library that simplifies working with X.509 certificates. It's built by Bram Verburg, who I consider to be the most knowledgeable person around web security in the Erlang and Elixir communities.
Let's get into it.
Error HandlingIn the code I'll show, I don't do any error handling that I would consider worthy of production code. I just match on stuff with = or in function heads. That leads to horrible MatchErrors and FunctionClauseErrors and whatnot, which are hard to debug and don't really provide context on what went wrong. In production, I'd never want that! The real-world code I wrote uses the throw/catch pattern, where I use throw/1 to throw errors that I catch at the end of the top-level function and return as {:error, reason} tuples.
throw/catch is a "dangerous" pattern because it uses non-local returns. However, it's a pattern that I've reached for several times in this type of situations. The trick is to never let a thrown term get out of a local function, or module at most. That way, users of the functions that throw don't have to know that those functions use throw/catch internally.
Decoding the JWS's HeaderThe first thing you want to do when verifying one of these JWTs is to peek at its header. This doesn't do any verification, but the header contains the certificate chain that we need to verify the JWT's signature, so we gotta look at it. JOSE provides a JOSE.JWT.peek_protected/1 function that returns the JWT's header as a raw JSON-encoded string:
decoded_header = signed_payload |> JOSE.JWS.peek_protected() |> Jason.decode!()Right. The algorithm should be ES256, so why not throw in a check for that:
%{"alg" => "ES256"} = decoded_headerExtracting and Verifying the CertificatesNext, we need to look at the x5c in the header. The x5c header field is documented in the JWT RFC (RFC 7515, sec. 4.1.6). It's a JSON array of base-64-encoded DER PKIX certificates. Those are complex acronyms that you and I really don't have to care about. The RFC (and Apple) says that you must validate the certificate chain.
First, let's extract the certificate chain:
# We pattern match on [_ | _] to make sure that the list of certs# isn't empty.%{"x5c" => [_ | _] = base64_cert_chain} = decoded_headercert_chain = Enum.map(base64_cert_chain, &Base.decode64!/1)Now, we can verify the certificate chain. We'll follow the process that I described above:
We'll check that the root certificate is the same as the certificate that Apple offers on Apple PKI.We'll check that the certificate chain is valid, meaning that each certificate was used to sign the next one in the chain.The code below assumes that you downloaded the Apple root certificate (AppleRootCA-G3 in particular). It reads it at compile time and embeds it in the bytecode of the module, so that you don't have to ship the file with your production application or release.
@apple_root_cert File.read!("certs/AppleRootCA-G3.cer")defp valid_certificate_chain?( [raw_leaf, raw_intermediate, _raw_root = @apple_root_cert] ) do case :public_key.pkix_path_validation( @apple_root_cert, [raw_intermediate, raw_leaf], [] ) do {:ok, _} -> true {:error, _} -> false endenddefp valid_certificate_chain?(_x5c_certs) do falseendBram basically hand-held me through this code, so thank you, Bram! We can use the valid_certificate_chain?/1 helper function to verify the certificate chain and blow up if it doesn't look right:
if not valid_certificate_chain?(cert_chain) do raise "certificate chain is invalid"endVerifying the JWS's SignatureLastly, the final (and fundamental) step: we need to check that the X.509 key in the leaf certificate was used to sign the whole JWT. JOSE provides the JOSE.JWK.from_key/1 function to build a JWK struct from a public key:
jwk = leaf_cert |> X509.Certificate.from_der!() |> X509.Certificate.public_key() |> JOSE.JWK.from_key()Now, the easiest part of all of this: we just use JOSE's verify/2 function to verify the signature in the JWT:
case JOSE.JWT.verify(jwk, signed_payload) do {_valid_signature? = true, jwt, _jws} -> {:ok, jwt} {_valid_signature? = false, _jwt, _jws} -> {:error, :invalid_signature} {:error, reason} -> {:error, reason} endConclusionThere's not much else to say about this. I spent a bunch of time on it and how to do it in Elixir after finding several pieces of code to do this in other languages. For example, Apple provides "App Store libraries" for a bunch of languages (take a look at the Python one). Apple also provides a useful video that explains this process.
Well, hope this helps someone. Thanks for stopping by!
July 23, 2023
A Breakdown of HTTP Clients in Elixir
Elixir's ecosystem has quite a few HTTP clients at this point. But what'sthe best one? In this post, I want to break down a bunch of the clients wehave available. I'll give an overview of the clients I personally like the most,and I'll talk about which clients are the best choice in different use cases.I'll also share some advice with library authors.

This is AI generated, just to be clear
All Your Clients Are Belong to UsSo, let's take a whirlwind tour of some HTTP clients available in Elixir. We'lltalk about these:
MintFinchReqhttpcThis is not a comprehensive list of all the Elixir HTTP clients, but rather alist of clients that I think make sense in different situation. At the end ofthis post, you'll also find a mention of other well-known clients, as well asadvice for library authors.
MintLet's start with Mint. Mint is arguably the lowest-level HTTP clientwe've got in Elixir. It's essentially a wrapper around a raw TCP or SSLsocket. Its job is to make the socket aware of the network protocol. It'sstateless, meaning that all you deal with is a "connection" data structure, andit's process-less, meaning that it doesn't impose any process architecture onyou.
Think about a :gen_tcp or a :ssl socket. Their job is to allow you toconnect servers and clients on the TCP and TLS network protocols, respectively.When you're using one of these directly, you usually have to do most of theencoding of decoding of the data that you're sending or receiving, because thesockets carry just binary data.
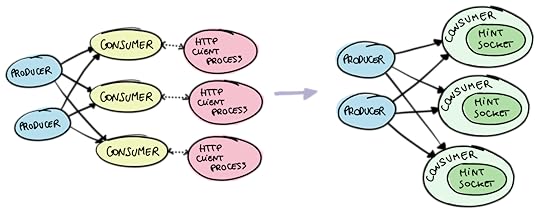
Mint introduces an abstraction layer around raw sockets, rather than on topof them. Here's a visual representation:
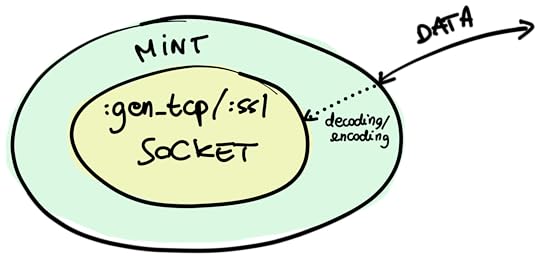
When you use Mint, you have an API that is similar to the one provided by the:gen_tcp and :ssl modules, and you're using a socket underneath. Mintprovides a data structure that it calls a connection, which wraps theunderlying socket. A Mint connection is aware of the HTTP protocol, so you don'tsend and receive raw binary data here, but rather data that makes sense in thesemantics of HTTP.
For example, let's see how you'd make a request using Mint. First, you'd want toopen a connection. Mint itself is stateless, and it stores all theconnection information inside the connection data structure itself.
{:ok, conn} = Mint.HTTP.connect(:http, "httpbin.org", 80)Then, you'd use Mint.HTTP.request/5 to send arequest.
{:ok, conn, request_ref} = Mint.HTTP.request(conn, "GET", "/", [], "")Sending a request is analogous to sending raw binary data on a :gen_tcp or:ssl socket: it's not blocking. The call to request/5 returns right away,giving you a request reference back. The underlying socket will eventuallyreceive a response as an Erlang message. At that point, you can useMint.HTTP.stream/2 to turn that message into something that makes sense inHTTP.
receive do message -> {:ok, conn, responses} = Mint.HTTP.stream(conn, message) IO.inspect(responses)end#=> [#=> {:status, #Reference<...>, 200},#=> {:headers, #Reference<...>, [{"connection", "keep-alive"}, ...},#=> {:data, #Reference<...>, "<!DOCTYPE html>..."},#=> {:done, #Reference<...>}#=> ]Mint supports HTTP/1.1 and HTTP/2 out of the box, as well as WebSocket throughmint_web_socket.
When to Use MintGenerally, don't use Mint. Seriously. You know I mean this advice, becauseI'm one of the two people who maintain andoriginally created Mint itself! For most use cases, Mint is too lowlevel. When you use it, you'll have to care about things such as poolingconnections, process architecture, keeping the connection structs around, and soon. It's a bit like what you'd do in other cases, after all. For example, you'reunlikely to use :gen_tcp to communicate directly with your PostgreSQLdatabase. Instead, you'd probably reach at least for something likePostgrex to abstract a lot of the complexity away.
Still, there are some use cases where Mint can make a lot of sense. First andforemost, you can use it to build higher-level abstractions. That's exactly whata library called Finch does, which we'll talk about in a bit. Mint can also beuseful in cases where you need fine-grained control over the performance andprocess architecture of your application. For example, say you have a fine-tunedGenStage pipeline where you need to make some HTTP calls at somepoint. GenStage stages are already processes, so having an HTTP client based ona process might introduce an unnecessary layer of processes in your application.Mint being processless solves exactly that.
A few years ago, I worked at a company where we would've likely used Mint inexactly this way. At the time, I wrote a blogpost that goes into more detail in case you'reinterested.
Bonus: Why Isn't Mint in the Elixir Standard Library?That's a great question! When we introduced Mint back in 2019, we posted aboutit on Elixir's website. Our original intention was to ship Mintwith Elixir's standard library. This is also one of the reasons why we wroteMint in Elixir, instead of Erlang. However, we then realized that it worked wellas a standalone library, and including it into the standard library wouldincrease the cost of maintaining the language as well as potentially slow downthe development of Mint itself.
That said, I think of Mint as the "standard-library HTTP client", that is, thelow-level client that you'd expect in the standard library of a language likeElixir.
FinchFinch is a client built on top of Mint. It serves an important job inthe "pyramid of abstractions" of HTTP clients listed in this post: pooling.Finch provides pooling for Mint connections. Using Mint on its own meansimplementing some sort of strategy to store and pool connections, which is whatFinch provides.
Finch is quite smart about its pooling. It uses nimble_pool when poolingHTTP/1.1 connections. The nimble_pool library is a tiny resource-poolimplementation heavily focused on a small resource-usage footprint as well as onperformance. Since HTTP/2 works quite differently from HTTP/1.1 and the formeris capable of multiplexing requests, Finch uses a completely different strategyfor HTTP/2, without any pooling. All of this is transparent to users.
The API that Finch provides is still quite low-level, with manual requestbuilding and such:
{:ok, _} = Finch.start_link(name: MyFinch)Finch.build(:get, "https://hex.pm") |> Finch.request(MyFinch)#=> {:ok, %Finch.Response{...}}However, but the convenience of pooling and reconnections that Finch provides isfantastic.
Okay, when to use Finch then? Personally, I think Finch is a fantastic librarywhenever you have performance-sensitive applications where you're ready tosacrifice some of the convenience provided by "higher-level" clients. It's alsogreat when you know you'll have to make a lot of requests to the same host,since you can specify dedicated connection pools per host. This is especiallyuseful when communicating across internal services, or talking to third-partyAPIs.
ReqReq is a relatively-new kid on the block when it comes to HTTP clients inElixir. It's one of my favorite Elixir libraries out there.
Req.get!("https://api.github.com/repos/wojtekma... "Req is a batteries-included HTTP client for Elixir."It's built on top of Finch, and it takes a quite "functional-programming"approach to HTTP. What I mean by that is that Req revolves around aReq.Request data structure, which you manipulate to addoptions, callbacks, headers, and more before making an HTTP request.
req = Req.Request.new(method: :get, url: "https://github.com/...") |> Req.Request.append_request_steps( put_user_agent: &Req.Steps.put_user_agent/1 ) |> Req.Request.append_response_steps( decompress_body: &Req.Steps.decompress_body/1, decode_body: &Req.Steps.decode_body/1 ) |> Req.Request.append_error_steps(retry: &Req.Steps.retry/1){req, resp} = Req.Request.run_request(req)Req is extensively customizable, since you can writeplugins for it in order to build HTTP clients thatare tailored to your application.
When To Use ReqFirst and foremost, Req is fantastic for scripting. With the introduction ofMix.install/2 in Elixir 1.12, using libraries in Elixirscripts is a breeze, and Req fits like a glove.
Mix.install([ {:req, "~> 0.3.0"}])Req.get!("https://andrealeopardi.com").hea... [#=> {"connection", "keep-alive"},#=> ...#=> ]Req is also a great fit to use in your applications. It provides a ton offeatures and plugins to use for things like encoding and decoding requestbodies, instrumentation, authentication, and so much more. I'll take a quotestraight from Finch's README here:
Most developers will most likely prefer to use the fabulous HTTP clientReq which takes advantage of Finch's pooling and provides an extremelyfriendly and pleasant to use API.
So, yeah. In your applications, unless you have some of the needs that wedescribed so far, just go with Req.
httpcWhile Mint is the lowest-level HTTP client I know of, there's another clientworth mentioning alongside it: httpc. httpc ships with the Erlangstandard library, making it the only HTTP client in the ecosystem thatdoesn't require any additional dependencies. This is so appealing! There arecases where not having dependencies is a huge bonus. For example, if you're alibrary author, being able to make HTTP requests without having to bring inadditional dependencies can be great, because those additional dependencieswould trickle down (as transitive dependencies) to all users of your library.
However, httpc has major drawbacks. One of them is that it provides littlecontrol over connection pooling. This is usually fine in cases where you need afew one-off HTTP requests or where your throughput needs are low, but it can beproblematic if you need to make a lot of HTTP requests. Another drawback is thatits API is, how to put it, awkward.
{:ok, {{version, 200, reason_phrase}, headers, body}} = :httpc.request(:get, {~c"http://www.erlang.org", []}, [], [])The API is quite low level in some aspects, since it can make it hard to composefunctionality and requires you to write custom code for common functionalitysuch as authentication, compression, instrumentation, and so on.
That said, the main drawback of httpc in my opinion is security. While allHTTP clients on the BEAM use ssl sockets under the hood (whenusing TLS), some are much better at providing secure defaults.
iex> :httpc.request(:get, {~c"https://wrong.host.badssl.com", []}, [], [])09:01:35.967 [warning] Description: ~c"Server authenticity is not verified since certificate path validation is not enabled" Reason: ~c"The option {verify, verify_peer} and one of the options 'cacertfile' or 'cacerts' are required to enable this."While you do get a warning regarding the bad SSL certificate here, the requeststill goes through. The good news is that this is mostly going away from OTP 26onward, since OTP 26 made SSL defaults significantlysafer.
When to Use httpcSo, when to use httpc? I would personally recommend httpc only when the mostimportant goal is to not have any external dependencies. The perfect example forthis is Elixir's package manager itself, Hex. Hex useshttpc because, if you think about it, what would be thealternative? You need Hex to fetch dependencies in your Elixir projects, so itwould be a nasty chicken-and-egg problem to try to use a third-party HTTP clientto fetch libraries over HTTP (including that client!).
Other libraries that use httpc are Tailwind andEsbuild. Both of these use httpc to download artifacts the firsttime they run, so using a more complex HTTP client (at the cost of additionaldependencies) isn't really necessary.
Choosing the Right ClientI've tried to write a bit about when to use each client so far, but to recap,these are my loose recommendations:
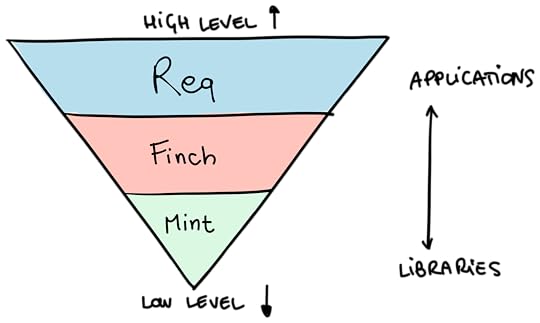
ClientWhenMintYou need 100% control on connections and request lifecycleMintYou already have a process architecture, and don't want to introduce any more processesMintYou're a library author, and you want to force as few dependencies as possible on your users while being mindful of performance and security (so no httpc)FinchYou need a low-level client with high performance, transparent support for HTTP/1.1 (with pooling) and HTTP/2 (with multiplexing)ReqMost applications that make HTTP callsReqScriptinghttpcYou're a (hardcore) library author who needs a few HTTP requests in their library, but you don't want to add unnecessary transitive dependencies for your usersSome of the HTTP clients I've talked about here form sort of an abstractionpyramid.
I want to also talk about library authors here. If you're the author of alibrary that needs to make HTTP calls, you have the options we talked about. Ifyou're only making a handful of one-off HTTP calls, then I'd go with httpc, sothat you don't have any impact on downstream code that depends on your library.However, if making HTTP requests is central to your library, I would reallyrecommend you use the "adapter behaviour" technique.
What I mean by adapter behaviour technique is that ideally you'd build aninterface for what you need your HTTP client to do in your library. For example,if you're building a client for an error-reporting service (such asSentry), you might only care about making synchronous POST requests.In those cases, you can define a behaviour in your library:
defmodule SentryClient.HTTPClientBehaviour do @type status() :: 100..599 @type headers() :: [{String.t(), String.t()}] @type body() :: binary() @callback post(url :: String.t(), headers(), body()) :: {:ok, status(), headers(), body()} | {:error, term()}endThis would be a public interface, allowing your users to implement their ownclients. This allows users to choose a client that they're already using intheir codebase, for example. You can still provide a default implementation thatships with your library and uses the client of your choice. Incidentally, thisis exactly what the Sentry library for Elixir does: it ships with a defaultclient based on Hackney. If you go with thisapproach, remember to make the HTTP client an optional dependency of yourlibrary:
# In mix.exsdefp deps do [ # ..., {:hackney, "~> 1.0", optional: true} ]endWhat About the Others?These are not all the HTTP clients available in Elixir, let alone on the BEAM! Ihave not mentioned well-known Elixir clients such as HTTPoison andTesla, nor Erlang clients such as hackney.
HTTPoisonHTTPoison is an Elixir wrapper on top of hackney:
HTTPoison.get!("https://example.com")#=> %HTTPoison.Response{...}Because of this, I tend to not really use HTTPoison and, if necessary, gostraight to hackney.
Hackneyhackney is a widely-used Erlang client which provides a nice and modern API andhas support for streaming requests, compression, encoding, file uploads, andmore. If your project is an Erlang project (which is not the focus of thispost), hackney can be a good choice.
:hackney.request(:get, "https://example.com", [])#=> {:ok, 200, [...], "..."}However, hackney presents some issues in my opinion. The first is that hackneyhad questionable security defaults. It uses good defaults, but when changingeven a single SSL option, then it drops all those defaults. This is prone tosecurity flaws, because users don't always fill in secure options. While nottechnically a fault of the library itself, the API makes it easy to mess up:
# Secure defaults::hackney.get("https://wrong.host.badssl.com")#... {:error, {:tls_alert, {:handshake_failure, ...# When changing any SSL options, no secure defaults anymore:ssl_options = [reuse_sessions: true]:hackney.get("https://wrong.host.badssl.com", [], "", ssl_options: ssl_options)# 11:52:32.033 [warning] Description: ~c"Server authenticity is not verified ...#=> {:ok, 200, ...}In the second example above, where I changed the reuse_sessions SSL options,you get a warning about the host's authenticity, but the request goes through.
Another thing that I think could be improved in hackney is that it brings in awhopping seven dependencies. They're all pertinent to what hackney does, butit's quite a few in my opinion.
Last but not least, hackney doesn't use the standard telemetry library toreport metrics, which can make it a bit of a hassle to wire in metrics (sincemany Elixir applications, at this point, use telemetry for instrumentation).
One important thing to mention: while HTTPoison is a wrapper around hackney, itsversion 2.0.0 fixes the potentially-unsecure SSL behaviorthat we just described for hackney.
TeslaTesla is a pretty widely-used HTTP client for Elixir. It provides asimilar level of abstraction as Req. In my opinion, its main advantage is thatit provides swappable HTTP client adapters, meaning that you can use itscommon API but choose the underlying HTTP client among ones like Mint, hackney,and more. Luckily, this feature is in the works for Req as well.
The reason I tend to not reach for Tesla is mostly that, in my opinion, itrelies a bit too much on module-based configuration and meta-programming. Incomparison, I find Req's functional API easier to compose, abstract, and reuse.
There are other clients in Erlang and Elixir: gun, ibrowse, andmore. But we gotta draw a line at some point!
ConclusionsWe went through a bunch of stuff here. We talked about the clients I personallylike and recommend for different use cases. You also got a nice little summarytable for when to use each of those client. Last but not least, I mentioned someother clients as well reasons why I prefer the ones in this post.
That's all. Happy HTTP'ing!
AcknowledgementsI want to thank a few folks for helping review this post before it went out. Thank you Jos��, Wojtek, and Jean.
January 4, 2023
Protohackers in Elixir
I recently published a new screencast series where I solve some network programming puzzles in Elixir. The challenges are provided by Protohackers, a website I recently found on the interwebs (it's sort of like Advent of Code, but for network challenges). You can find all the videos in this post.
Here's the playlist on YouTube:
November 30, 2022
Advent of Code 2022
November 27, 2022
Get Rid of Your Old Database Migrations
January 24, 2022
Testing AWS in Elixir
At Community we run most of our infrastructure and services on AWS. We use several different AWS services. Many of our own services interact with AWS directly, such as by uploading and downloading files from S3, querying Athena, and more. Lately, I���ve been trying to improve how we test the interaction between our services and AWS, testing error conditions and edge cases as well as running reproducible integration tests. In this post, I���ll talk about Localstack, mocks, ex_aws, and more.
January 8, 2022
Example-based Tests And Property-based Tests Are Good Friends
I mostly use property-based testing to test stateless functional code. A technique I love to use is to pair property-based tests together with example-based tests (that is, ���normal��� tests) in order to have some tests that check real input. Let���s dive deeper into this technique, some contrived blog-post-adequate examples, and links to real-world examples.


