
David Bryant Copeland's Blog
November 5, 2025
Discussing Brut on Dead Code Podcast
I recently got to chat with Jared Norman on the Dead Code Podcast. We talked mostly about Brut, but also a bit about hardware synthesizers and looptober.
If you want to know about more about why Brut exists or its philisophical underpinnings, check it out!


October 7, 2025
Building a Sub-command Ruby CLI with just OptionParser
I���ve thought deeply about building CLIs and built alot of them over the years. I���ve used Rake, Thor, my own gem GLI and many others. After all that, the venerable OptionParser���part ofRuby���s standard library���is the best choice for scripting and sub-command (git-like) CLIs. I want to show you how.
What is a Sub-Command CLI?At first glance, OptionParser doesn���t seem to support a sub-command CLI, like so (I���ll explain what each part is below):
> bin/test --verbose audit --type Component specs/front_endYes, you could configure --verbose and --type TYPE, then figure out that the first thing left over in ARGV was a command, but it gets very cumbersome when things get beyond trivial, especially when you want to show help.
Fortunately, OptionParser's lesser-known (and oddly-named) methodorder! parses the command-line up to the first argumentit doesn���t understand. How does this help?
Consider the command above. It���s made up of five parts: the app name (bin/test), the globally-applicable options (--verbose), the subcommand (audit), command-scoped options (--type Component) and the arguments (specs/front_end):
> bin/test --verbose audit --type Component specs/front_end ---+-- ---+-- --+-- ----------+--- ----+------ | | | | |App---+ | | | |Global Options---+ | | |Sub Command------------+ | |Command Options------------------------+ |Arguments----------------------------------------+You���d design a CLI like this if the various sub-commands had shared code or behavior. It also helps to avoid having a zillion differentscripts and provides a namespace, especially if you can provide good help. Fortunately, OptionParse does provide good help and can parse this.
Two Option Parsers Divide Up the WorkThe key is to use two OptionParsers:
The first parses the global options. It uses order! (instead of parse!) so that it only parses options up to the first argument itdoesn���t understand (audit) in our case. The second uses parse!, which consumes the entire rest of the command line, leaving ARGV with whatever wasn���t parsed.Here���s a basic sketch. First, we���ll create the global OptionParser:
require "optparse"global_parser = OptionParser.new do |opts| opts.banner = "bin/test [global options] command [command options] [command args...]" opts.on("--verbose", "Show additional logging/debug information")endNext, we���ll need the second OptionParser for the audit subcommand. You���d need one OptionParser for each subcommand you want tosupport.
commands = {}commands["audit"] = OptionParser.new do |opts| opts.on("--type TYPE", "Set the type of test to audit. Omit to audit all types")end# Add more OptionParsers for more commands as neededNow, when the app runs, we parse the global options first using order!. This means that ARGV[0] (i.e. the first part of the command line that didn���t match anything in the global OptionParsers) is the command name. We use that to locate the OptionParser to use, then call parse! on that.
global_options = {}command_options = {}global_parser.order!(into: global_options)command = ARGV[0]command_parser = commands[command]command_parser.parse!(into: command_options)# Now, based on the value of command, do whatever needs doingWhat OptionParser doesn���t give you is a way to manage the code to run for the e.g. audit command, but you have all the object-orientedfacilities of Ruby available to do that. In Brut, the way I did this was to create a class with an execute methodthat maps to its name and exposes it���s OptionParser. Roughly:
class AuditCommand def self.option_parser OptionParser.new do |opts| opts.on("--type TYPE", "Set the type of test to audit. Omit to audit all types") end end def initialize(command_options:, args:) @command_options = command_options @args = args end def execute # whatever endendcommands["audit"] = AuditCommand# ...command = ARGV[0]command_klass = commands[command]command_parser = command_klass.option_parsercommand_parser.parse!(into: command_options)command_klass.new(command_options:, args: ARGV).executeOptionParser also provides sophisticated type coercion via accept.Many built-in conversions are available and youcan create your own.
This code gets more complex when you want to show help or handle errors
Showing Help and Handling ErrorsOptionParser can produce a decent help message:
puts global_parser# orputs command_parserYou can do much fancier stuff if needed by using summarize.
For handling errors, OptionParser will raise an error if options were provided that aren���t valid, and you can check whatever you need andcall exit.
Now, there is a lot of ���do whatever you want��� here, as well as potentially verbose code. Why not use a gem that does this for you?
Don���t Use Gems if Your Needs are TypicalCode that relies only on the standard library is stable code. The standard library rarely breaks things and is maintained. OptionParseris designed to parse a UNIX-like command line, which is usually what you want.
Even though OptionParser is a bit verbose, you likely aren���t writing command-line code frequently, so the verbosity���and reliance on thestandard library���is a bonus. DSLs, at least in my experience, tend to have a half-life and can be hard to pickup, so you re-learn them overand over, unless you are working in them every day.
I built GLI to make this easier, but in practice, it���s a somewhat wide DSL that you have to re-learnwhen editing your CLI.
Thor is very popular, included with Rails, and mostly supports this kind of UI, but it is an even denser DSL that I don���t think rewards you for learning it. And, because it does not use OptionParser, it���s very sensitive to command and argument ordering in a way that seasoned UNIX people would find surprising and annoying. It also includes a ton of other code you likely don���t need, such as the ability copy files and templates around.
Rake is part of the standard library, but the CLIs it produces are not very ergonomic. You must use asequence of square brackets and quotes to pass arguments, and there is no facility for options like --verbose. Rake is designed as adependency manager, e.g. build my favicon.ico whenever my favicon.png changes. It���s not a general-purpose way to make command line apps.
So, embrace the standard library, and embrace OptionParser!
August 18, 2025
Confirmation Dialog with BrutRB, Web Components, and no JS
I created a short (8 minute) screencast on adding a confirmation dialog to form submissions using BrutRB���s bundled Web Components. You don���t have to write any JavaScript, and you can completely control the look and feel with CSS.
There���s also a tutorial that does the same thing or, if you are super pressed for time:
message="Are you sure?"> Save value="ok"> value="cancel">NevermindProgressive enhancement, and no magic attributes on existing elements.
docs docsAugust 6, 2025
Please Create Debuggable Systems
When a system isn���t working, it���s far easier to debug the problem when that system produces good error messages as well as useful diagnostics. Silent failures are sadly the norm, because they are just easier to implement. Systems based on conventions or automatic configuration exacerbate this problem, as they tend to just do nothing and produce no error message. Let���s see how to fix this.
Rails popularized ���convention over configuration���, but it often fails to help when conventions aren���t aligned, often silently failing with no help for debugging. This cultural norm has proliferated to many Ruby tools, like Shopify���s ruby-lsp, and pretty much all of Apple���s software design.
I asked my editor to jump to a definition and the LSP didn���t do it and there is no error message. I took a picture on my phone, it���s connected to WiFi, as is my computer, and it���s not synced to my photos. There is no ���sync��� button, norany sort of logging telling me if it tried to sync and failed or didn���t try and why not. I���m creating my dev and test databases and it doesn���t create my dev database, but creates my test database twice. (I hope this poor guy figured it out���it���s been seven years!)We all experience these failures where we get an error message that���s not helpful and then no real way to get more information about the problem.
Creating a debuggable system is critical for managing software, especially now that more and more code is not written be a real person. To create such a system, it must provide two capabilities:
Helpful and descriptive error messages The ability to ask the system for much more detailed informationBoth of these capabilities must be pre-built into the system. They cannot be provided only in some interactive debugging session or only in a development environment. You want these capabilities in your production system.
Write Helpful and Descriptive Error MessagesThere is always a tension between an error message that is so full of information as to be useless and one so vacant that it, too, is useless. Designers never want users to see error messages. The security team never wants to allow error messages to provide hackers with information. And programmers often write errors in their own language, which no one else understands.
Ideally, each error message the system produces is both unique and is written in a way you can reference more detailed information about what to do.
Consider what happens when using NeoVim and Shopify���s ruby-lsp is asked to go to the definition of a Ruby class and, for whatever reason, it can���t:
No Location Found
This absolutely sucks:
It doesn���t explain what went wrong It doesn���t provide any pointers for further investigation It���s not clear what is producing this message: ruby-lsp, the Neovim plugin, or Neovim itself It doesn���t even say what operation it was trying to perform!Here are some better options:
���Could not find definition of ���FooComponent������ ���Could not find definition of ���FooComponent���, ruby-lsp returned empty array��� ���Could not find definition of ���FooComponent���, restart ruby-lsp server with --debug to debug��� ���Could not find definition of ���FooComponent���, see NeoVim���s log at ~/cache/logs/neovim.log for details��� ���Could not find definition of ���FooComponent���, searched 1,234 defined classes from 564 folders���These messages each have attributes of a useful error:
The operation that caused the issue (���Could not find definition���) The specific inputs to that operation (FooComponent) Observed behavior of dependent systems (���ruby-lsp returned empty array���) Options to get more information (���restart ruby-lsp������ and ���see NeoVim���s log���) Metadata about the request (���searched 1,234 classes������)These can all help you try to figure out the problem. Even if you can���t provide all diagnostics, you should always consider including in your error message:
What operation you tried to perform What result you got (summarized, not analyzed) What systems are involved: attach your system���s name to messages you create attach the subsystem���s name to message you receive and pass alongAside from this, creating a way to get more information is also extremely helpful.
Create a Debug or Diagnostic ModeThe volume of information required to fully debug a problem can be quite large. It can be costly to produce and difficult to analyze. This can be a worthwhile tradeoff if something isn���t working and you don���t have any other options. This means your system needds a debug or diagnostic mode.
A diagnostic mode should produce the inputs and outputs as well as intermediate values relevant to producing the outputs. Let���s imagine how finding the definition of a class in Ruby works in the ruby-lsp.
At a high level, the inputs are the symbol being looked-up and the outputs are a list of files and locations where that sybmol is defined. LSP is more low level, however, as it will actually accept as input a line/column of a file where a symbol is referenced, and expect a list similar locations in return.
This means there are a few ways this can fail:
The file doesn���t exist There is no symbol at the location of the file The symbol���s definition can���t be found The symbol was found, but the file isn���t accessible to the callerThe most common case is a symbol being correctly identified in the file, but not found. This is where intermediate values can help.
Presumably, a bunch of files were searched for the symbol that can���t be found. Knowing those files would be useful! But, presumably, those files were found by searching some list of folders for Ruby files. That list of folders would be nice to know as well!
This is obviously a massive amount of information for a single-line error message, however the information could be stored. The entire operation could be given a unique ID, which is then included in the error message and included in a log file that produces all of this information. Given the volume of information, you���d probably want the LSP to only produce this when asked, either with a per-request flag or a flag at startup (e.g. --diagnostic or --debug).
Making all this avaiable requires extra effort on the part of the programmer. Sometimes, it could be quite a bit of effort! For example, there may not be an easy way to generate a unique ID and ensure it���s available to everywhere in the code with access to the diagnostic information. And, of course, all this diagnostic code can itself fail, creating more intermediate values needed to diagnose problems. We���ve probably all written something like this before:
begin some_operationrescue => ex begin report_error(ex) rescue => ex2 $stderr.puts "Encountered #{ex2} while reporting error #{ex} - something is seriously wrong" endendIn addition to just culling the data, you have to log it, or not. Ruby���s Logger provides a decent solution using blocks:
logger.debug { # expensive calculation}The block only executes if the logger is set to debug level. Of course, you may not like the all-or-nothing approach. The venerable log4j used in almost every Java app allows you to configure the log level per class and even dynamically change it at runtime. You can do this in Ruby with SemanticLogger:
require "semantic_logger"SemanticLogger.appenders << SemanticLogger::Appender::IO.new(STDOUT)class Foo include SemanticLogger::Loggable def doit logger.debug("FOO!") endendclass Bar include SemanticLogger::Loggable def doit logger.debug("BAR!") endendfoo = Foo.newbar = Bar.newfoo.debug # => nothingbar.debug # => nothingFoo.logger.level = :debugfoo.debug # => 2025-08-06 18:35:59.138433 D [2082290:54184] Foo -- FOO!bar.debug # => nothingWhile SemanticLogger only allows runtime changes of the global log level, you could likely write something yourself to change it per class.
Please Create Debuggable SystemsWhile you could consider everything above as a part of observability, to me this is distinct. Debuggable systems don���t have to have OTel or other fancy stuff���they can write logs or write to standard output. Debuggable systems show useful error messages that explain (or lead to an explanation of) the problem, and can be configured to produce diagnostic information that tells you what they are doing and why.
You can get started by creating better error messages in your tests! Instead of writing assert list.include?("value"), try this:
assert list.include?("value"), "Checking list '#{list}' for 'value'"Try to make sure when any test fails, the messaging you get is everything you need to understand the problem. Then proliferate this to the rest of your system.
July 23, 2025
Build a blog in 15ish Minutes with BrutRB
This is a whirlwind tour of the basics of Brut, where I build a blog from scratch in a bit over 15 minutes. The app is fully tested and even has basic observability as a bonus. The only software you need to install is Docker.
Watch on YouTube, if PeerTube isn���t working for you for some reason Check out the source code, if you don���t want to watch a videoJuly 8, 2025
Brut: A New Web Framework for Ruby

Brut aims to be a simple, yet fully-featured web framework for Ruby. It's different than other Ruby web frameworks. Brut has no controllers, verbs, or resources. You build pages, forms, and single-action handlers. You write HTML, which is generated on the server. You can write all the JavaScript and CSS you want.
Here���s a web page that tells you what time it is:
class TimePage < AppPage def initialize(clock:) @clock = clock end def page_template header do h1 { "Welcome to the Time Page!" } TimeTag(timestamp: @clock.now) end endendBrut is built around low-abstraction and low-ceremony, but is not low-level like Sinatra. It���s a web framework. Your Brut apps have builtin OpenTelemetry-based instrumentation, a Sequel-powered data access layer, and developer automation based on OptionParser-powered command-line apps.
Brut can be installed right now, and you can build and run anapp in minutes. You don���t even have to install Ruby.
> docker run \ -v "$PWD":"$PWD" \ -w "$PWD" \ -it \ thirdtank/mkbrut \ mkbrut my-new-app> cd my-new-app> dx/build && dx/start> dx/exec bin/setup> dx/exec bin/dev# => localhost:6502 is waitingThere���s a full-fledged example app called ADRs.cloud you can run right now and see how it works.
What You GetBrut has extensive documentation, however these are some highlights:
Brut���s core design is around classes that are instantiated into objects, upon which methods are called. No excessive include calls to create a massive blob of functions. No Hashes of Whatever. Your session, flash, and form parameters are all actual classes and defined data types. Minimal reliance of dynamically-defined methods or method_missing. Almost everymethod has documentation.Brut leverages the modern Web Platform. Client-side and server-side form validation is unified into one user experience. BrutJS is an ever-evolving libraryof autonomous custom elements AKA web components to progressively enhance yourHTML. With esbuild, you can write regular CSS and haveit instantly packaged, minified, and hashed. No PostCSS, No SASS.Brut sets up good practices by default. Your app will have a reasonable content security policy. Your database columns aren���t null by default. Your foreign keys will a) exist, b) be indexed, and c) not be nullable bydefault. Time, available through Brut���s Clock, is always timezone-aware. Localization is there and is as easy as we can make it. We hope to make it easier.Brut uses awesome Ruby gems RSpec is how you write your tests. Brut includes custom matchers to make iteasier to focus on what your code should do. Faker and FactoryBot will set up your test and dev data Phlex generates your HTML. No, we won���t be supporting HAML.Brut doesn���t recreate configuration with YAML. I18n uses the i18n gem, with translations in a Ruby Hash. No YAML. Dynamic configuration is in the environment, managed in dev and test by thedotenv gem. No YAML. OK, the dev environment���s docker-compose.dx.yml is YAML. But that���s it. YAML, not even oncetwice.Brut doesn���t create abstractions where none were needed. Is this the index action of the widgets resource or the show action of the widget-list resource? is a question you will never have to ask yourself or your team. The widgets page is called WidgetsPage and available at /widgets. My Widgets class accesses the WIDGETS table, but it also has all the domain logic of a widget! No it doesn���t. DB::Widget gets your data. You can make Widget do whatever you want. Heck, make a WidgetService for all we care! What if our HTML had controllers but they were not the same as the controllers in our back-end? There aren���t any controllers. You don���t want them, you don���t have to make them. What about monads or algebraic data types or currying or maybe having everythingbe a Proc because call?! You don���t have to understand any part of that question. But if you want your business logic to use functors, go for it. We won���t stop you.WHY?!?!?!I know, we can vibe away all the boilerplate required for Rails apps. But how much fun is that? How much do you enjoy setting up RSpec, again, in your new Rails app? How tired are you of changing the ���front end solution��� every few years? And aren���t you just tired of debating where your business logic goes or if it���s OK to use HTTP DELETE (tunneled over a _method param in a POST) to archive a widget?
I know I am.
I want to have fun building web apps, which means I want write Ruby, use HTML, and leverage the browser. Do you know how awesome browsers are now? Also, Ruby 3.4 is pretty great as well. I���d like to use it.
What I don���t want is endless flexibility, constant architectural decision-making, or pointless debates about stuff that doesn���t matter.
I just want to have fun building web apps.
Next StepsI will continue working toward a 1.0 of Brut, building web apps and enjoying the process. I hope you will, too!

June 12, 2025
Neovim and LSP Servers Working with Docker-based Development
Working on an update to my Docker-based Dev Environment Book, I realized it would be important to show how to get an LSP server worker inside Docker. And I have! And it���s not that easy, but wasn���t that hard, either. It hits a lot of my limits of Neovim knowledge, but hopefully fellow Vim users will find this helpful.
The ProblemMicrosoft created the Language Server Protocol (LSP), and so it���s baked into VSCode pretty well. If you require a more sophisticated and powerful editing experience, however, you are using Vim and it turns out, Neovim (a Vim fork) can interact with an LSP via the lsp-config plugin.
Getting this all to work requires solving several problems:
Why do this at all? How Can Neovim talk to an LSP server? Which LSP Servers do I need and how do I set them up? But how do I do that inside a Docker development container? What can I do with this power?What Does an LSP Server Do?I had never previously pursued setting up an LSP server because I never felt the need for it. To be honest, I couldn���t even tell you what it did or what it was for. I���ve used vi (and Vim and Neovim) for my entire career never using an IDE beyond poking at a few and deciding they were not for me.
The cornerstone of an LSP server is that it can understand your code at a semantic level, and not just as a series of strings. It can know precisely where a class named HTMLGenerator is defined and, whenever you cursor onto that class name, jump to that location, even if it doesn���t conform to Ruby���s conventions.
Traditional Vim plugins don���t do this. They���d mangle HTMLGenerator to come up with html_generator.rb or h_t_m_l_generator.rb and then find that filename, hoping that���s where the class was defined.
With this core feature, an LSP server can allow features not possible in Neovim (or at least not possible beyond string manipulation):
Completion based on language and project. When you enter a variable name and ., it will show a listof possible methods to call. This works in non-dot-calls-a-method languages, too. Jump to the definition of a symbol, regardless of the filename where it���s defined. List all symbols in the current file to e.g. quickly jump to a method or variable. Pop up a window inside Neovim to show the documentation for a symbol, based on the documentation in thesource file you are using (i.e. and not fetching it from a website). See where the given symbol is being referenced. Perform a project-wide rename of a symbol. Show the method signature of a method you are calling Show the type hierarchy of the class you are in. Syntax highlighting based on language constructs and not regular expressions. For example, an LSP-basedsyntax highlight could show local variables and method calls differently, even though in Ruby they look the same.���Inlay hints��� which add context to the code where something implicit is going on. The simplest examplefor Ruby is the somewhat new Hash syntax:
foo = "bar"blah = 42doit({ foo:, blah: })Since the keys are the same as local symbols, this is the same as { foo: foo, blah: blah }. With inlay hints, the editor would show that:
foo = "bar"blah = 42doit({ foo: foo, blah: blah})This added information is not editable, and if your cursor is on the space after foo:, moving to the right skips over the ���inlayed��� foo, right to the next comma.
Realtime compiler errors and warnings. This shows a marker in the column of a line with an error,along with potentially red squiggles, and an ability to open a pop-up window showing the error message.There is more that can be done per language and tons of extensions. I have had a successful programming career of many years without these features, but they do seem useful. They���ve just never seemed worth it to give up Vim and use an IDE, which usually provides a terrible text editing experience.
Getting an LSP Server To Work with NeovimGetting an LSP server to work requires figuring out how install the server, then configuring Neovim to use it via the lsp-config plugin. This creates the meta-problem of how to set up that plugin, because Neovim has a lot of plugin management systems.
I use a system that allows me to clone plugins from a Git repo inside ~/.vim (for Vim) and ~/.local/share/nvim/site (for Neovim) and restart Vim and stuff works. It���s been so long I don���t know what this is called.
After you���ve installed lsp-config however you install Neovim plugins, the next issue is that most of the configuration is documented in Lua. Because I am old, all my configuration is in VimScript. Getting some Lua configuration is a single line of code, inside ~/.config/nvim/init.vim:
lua require('config')This assumes that ~/.config/nvim/lua/config.lua exists, and then runs that configuration as normal. With that in place, here���s an outline of the configuration needed to use Shopify���s Ruby LSP server and Microsoft���s CSS and Typescript LSP servers. These aren���t complete, yet, but this gives you an idea:
local lspconfig = require('lspconfig')-- Set up Shopify's LSP server. The string-- "ruby_lsp" is magic and you must consult lsp-config's-- documentation to figure out what string to use for-- what LSP server.lspconfig.ruby_lsp.setup({ -- To be filled in})-- Set up Microsoft's CSS LSP server (again, "cssls" is magic)lspconfig.cssls.setup({ -- To be filled in})-- Set up Microsoft's TypeScript/JavaScript-- server, "ts_ls" being magic.lspconfig.ts_ls.setup({ -- To be filled in})With this configuration, Neovim will attempt to use these LSP servers for Ruby, CSS, TypeScript, and JavaScript files. Without those servers installed, you will get an error each time you load a file.
Installing and Configuring LSP ServersIn most cases, installing LSP servers can be done by installing a package with e.g. RubyGems or NPM.
Ruby: gem install ruby-lsp (or put in Gemfile) CSS: npm install --save-dev vscode-langservers-extracted TypeScript/JavaScript: npm install --save-dev typescript typescript-language-server (Note: you may have typescript installed already if you are using it elsewhere in your project)The lsp-config plugin assumes that the servers can be run as bare commands, e.g. ruby-lsp or typescript-language-server. In most cases, these don���t work this way (e.g. you must use npx or bundle exec). When running them in Docker, they definitely won���t work from the perspective of Neovim running outside Docker.
When the LSP Server and Neovim are running on the same machine, you can get it working easily by tweaking the cmd configuration option:
lspconfig.ts_ls.setup({ cmd = { 'npx', 'typescript-language-server', '--stdio' },})If we want the servers to be run inside a Docker development container, we���ll need to do a bit more tweaking of the configuration.
Configuring LSP Servers to Run Inside DockerSince the LSP servers will be installed inside the Docker container, but will need to be executed from your computer (AKA the host), you���ll need to tell Neovim to basically use docker compose exec before running the LSP server���s command.
 Open bigger version in new window
Open bigger version in new window The way I set up my projects, I have a script called dx/exec that does just this. dx/exec bash will run Bash, dx/exec bin/setup will run the setup script, etc.
The command you ultimately want to run isn���t just the LSP server command. You need to run Bash and have Bash run that command. This is so your LSP server can access whatever environment set up you have.
To do this, you want Neovim to run docker compose exec bash -lc ��LSP Server command��. -l tells Bash to run it as a login shell. You need this to simulate logging in and running the LSP server, which is what is expected outside Docker. -c specified the command for bash to run.
Given that I have dx/exec to wrap docker compose exec, here is what my configuration looks like:
local lspconfig = require('lspconfig')lspconfig.ruby_lsp.setup({ cmd = { 'dx/exec', 'bash', '-lc', 'ruby-lsp', }, -- More to come})lspconfig.cssls.setup({ cmd = { 'dx/exec', 'bash', '-lc', 'npx vscode-css-language-server --stdio' }, -- More to come})lspconfig.ts_ls.setup({ cmd = { 'dx/exec', 'bash', '-lc', 'npx typescript-language-server --stdio' },})Note that this is somewhat meta. cmd expects a list of command line tokens. Normally, npx typescript-language-server --stdio would be considered three tokens. In this case, it���s a single token being passed to bash, so you do not break it up like you would if running everything locally.
Once they are running, you���ll need to make further tweaks to get them to talk to Neovim in a way that will work.
Making LSP Servers Inside Docker Work with NeovimThe ���protocol��� in LSP is based around paths to files and locations in those files. This means that both Neovim and the LSP server must view the same files as having the same path. When they both run on the same computer, this is how it is.
In a Docker-based dev environment, the container is typically configured to mount your computer���s filesinside the container, so that changes on your computer are seen inside the Docker container andvice-versa. If the filenames and paths aren���t identical, the LSP servers won���t work.
Consider a setup where /home/davec/Projects/my-awesome-app is the path to the code is on my computer, but I���ve mounted it inside my development container at /home/appuser/app:
 Open bigger version in new window
Open bigger version in new window When the LSP Server tells NeoVim that a symbol is defined in /home/appuser/app/foo.br, Neovim won���t find it, because that file is really in /home/davec/Projects/my-awesome-app/foo.rb.
Ensuring the LSP Server and NeoVim Use the Same PathsWhat you want is for them to be mounted in the same location.
 Open bigger version in new window
Open bigger version in new window In my case, I use Docker Compose to configure the volume mapping, so here���s what it should look like:
services: app: image: ��image name�� init: true volumes: - type: bind source: "/home/davec/Projects/my-awesome-project" target: "/home/davec/Projects/my-awesome-project" consistency: "consistent" working_dir: "/home/davec/Projects/my-awesome-project"Note that because docker-compose.yml can interpret environment variables, you can replace the hard-coded paths with ${PWD} so it can work for everyone on your team (assuming you run docker compose up from /home/davec/Projects/my-awesome-project).
services: app: image: ��image name�� init: true volumes: - type: bind source: ${PWD} target: ${PWD} consistency: "consistent" working_dir: ${PWD}This works great���for files in your project. For files outside your project, it depends.
Files Outside Your Project Must Have the Same Paths, TooFor JavaScript or TypeScript third party modules, those are presumably stored in node_modules, so the paths will be the same for the LSP server inside the Docker container and to Neovim. Ruby gems, however, will not be, at least by default.
The reason this is important is that you may want to jump to the definition of a class that exists in a gem, or view its method signature or see its documentation. To do this, because the LSP server uses file paths, the paths to e.g. HTTParty���s definition must be the same inside the Docker container as they are to Neovim running on your computer.
The solution is to set GEM_HOME so that Ruby will install gems inside your project root, just as NPM does for JavaScript modules.
This configuration must be done in both ~/.profile and ~/.bashrc inside the Docker container, since there is not a normal invocation of Bash that would source both files. I have this as bash_customizations which is sourced in both files. bash_customizations looks like so:
export GEM_HOME=/home/davec/Projects/my-awesome-app/local-gems/gem-homeexport PATH=${PATH}:${GEM_HOME}/binYou���ll want to ignore local-gems in your version control system, the same as you would node_modules.
Now, re-install your gems and jumping to definitions will work great.
This leads to an obvious question: how do you jump to a definition?!
Configuring Neovim to use LSP Commandslsp-config does set up a few shortcuts, which you can read in their docs. This isn���t sufficient to take advantage of all the features. You also can���t access all the features simply by creating keymappings. Some features must be explicitly enabled or started up.
Of course, you don���t want to set any of this up if you aren���t using an LSP server. This can be addressed by putting all setup code in a Lua function that is called when the LSP ���attaches���. This function will be called on_attach and we���ll see it in a minute (note that I���m adding some configuration for Ruby LSP to make inlay hints work, as I couldn���t find a better place to do that in this blog post :).
local lspconfig = require('lspconfig') lspconfig.ruby_lsp.setup({ cmd = { 'dx/exec', 'bash', '-lc', 'ruby-lsp', },��� on_attach = on_attach,��� init_options = {��� featuresConfiguration = {��� inlayHint = {��� enableAll = true��� }��� }, } }) lspconfig.cssls.setup({ cmd = { 'dx/exec', 'bash', '-lc', 'npx vscode-css-language-server --stdio' },��� on_attach = on_attach, -- More to come }) lspconfig.ts_ls.setup({ cmd = { 'dx/exec', 'bash', '-lc', 'npx typescript-language-server --stdio' },��� on_attach = on_attach, -- More to come })on_attach will do two things: 1) set up keybindings to call the Lua functions exposed by lsp-config (which will then make the right calls to the right server), and 2) enable various LSP features that are off by default.
Here���s how I have mine set up (you may want different keybindings). I���ve commented what each does:
local on_attach = function(client, bufnr) local opts = { buffer = bufnr, noremap = true, silent = true } -- When on a symbol, go to the file that defines it vim.keymap.set('n', 'gd', vim.lsp.buf.definition, opts) -- When on a symbol, open up a split showing files referencing -- this symbol. You can hit enter on any file and that file -- and location of the reference open. vim.keymap.set('n', 'gr', vim.lsp.buf.references, opts) -- Open up a split and show all symbols defined in the current -- file. Hitting enter on any symbol jumps to that location -- in the file vim.keymap.set('n', 'gs', vim.lsp.buf.document_symbol, opts) -- Open a popup window showing any help available for the -- method signature you are on vim.keymap.set('n', 'gK', vim.lsp.buf.signature_help, opts) -- If there are errors or warnings, go to the next one vim.keymap.set('n', 'dn', function() vim.diagnostic.jump({ count = 1, float = true }) end) -- If there are errors or warnings, go to the previous one vim.keymap.set('n', 'dp', function() vim.diagnostic.jump({ count = -1, float = true }) end) -- If you are on a line with an error or warning, open a -- popup showing the error/warning message vim.keymap.set('n', 'do', vim.diagnostic.open_float) -- Open the "hover" window on a symbol, which tends to show -- documentation on that symbol inline vim.keymap.set('n', 'K', vim.lsp.buf.hover, opts) -- While in insert mode, Ctrl-Space will invoke Ctrl-X Ctrl-o -- which initiates completion to show a list of symbols that -- make sense for autocomplete vim.api.nvim_set_keymap('i', '', '', { noremap = true, silent = true }) -- Enable "inlay hints" vim.lsp.inlay_hint.enable() -- Enable completion vim.lsp.completion.enable(true, client.id, bufnr, { autotrigger = true, -- automatically pop up when e.g. you type '.' after a variable convert = function(item) return { abbr = item.label:gsub('%b()', '') } -- NGL, no clue what this is for but it's needed end, }) -- If the LSP server supports semantic tokens to be used for highlighting -- enable that. if client and client.server_capabilities.semanticTokensProvider then vim.lsp.semantic_tokens.start(args.buf,args.data.client_id) endend-- The documentation said to set this for completion-- to work properly and/or well. I'm not sure what happens-- if you omit thisvim.cmd[[set completeopt+=menuone,noselect,popup]]Whew! The lsp-config documentation can help you know what other functions might exist, but the setup above seems to use most of them, at least the ones for Ruby that I think are useful.
Once this is all set up, you will find that the CSS and JavaScript LSP Servers still don���t work.
Getting Microsoft���s LSP Servers to Work Because They Crash By DefaultOnce I had Ruby working, I installed CSS and TypeScript and found that they would happily complete any single request and then crash. Apparently, they assume the editor and server are running on the same computer and use a process identifier to know if everything is running normally.
Since this would not work with Docker (the process IDs would be different or not available), you need to configure both LSP servers in lsp-config to essentially not care about process IDs.
lspconfig.cssls.setup({ cmd = { 'dx/exec', 'bash', '-lc', 'npx vscode-css-language-server --stdio' }, on_attach = on_attach,��� before_init = function(params)��� params.processId = vim.NIL��� end, }) lspconfig.ts_ls.setup({ cmd = { 'dx/exec', 'bash', '-lc', 'npx typescript-language-server --stdio' }, on_attach = on_attach,��� before_init = function(params)��� params.processId = vim.NIL��� end, })This is all great, but you may not want Neovim trying to connect to LSPs when you have not set them up.
Don���t Configure LSP if It���s Not AvailableWhen I open up a random Ruby script on my computer, I get errors about LSP servers not being available. What I decided to do was configure LSP as opt-in in my Neovim configuration.
If the Lua setup script finds the file .nvim.lua in the project root, it will source it. If that file sets useLSP to true, all of the above configuration happens. If useLSP is absent, no LSP configuration is done:
local project_config = vim.fn.getcwd() .. "/.nvim.lua"if vim.fn.filereadable(project_config) == 1 then dofile(project_config)endif useLSP == nil then useLSP = falseendif useLSP then -- configuration from aboveendAnd Now We Can Work!I���ve been using this configuration for a few days and to be honest, I can���t quite tell how well it���s working. But it doesn���t seem that fragile, and it seems useful to have setup in case other extensions or LSP servers become very useful.
March 21, 2025
One Week With Desktop Linux After a 20 Year Absence
I bought a Framework laptop a couple weeks ago, set it up with stock Ubuntu, and used it for myprimary computer for a week. It���s the first time I���ve used Linux in earnest in 20 years.It���s amazing how much has changed and how much hasn���t.
The tl;dr for this post is that I don���t know if I could use Linux as my desktop full time for web development. While there are many papercuts, the three main issues I can���t see a way around are: lack of integrated API documentation lookup (e.g. Dash.app), inability to customize keyboard shortcuts consistently across all apps, and the absolute tire-fire of copy and paste.
Why Even Do This?I actually grew up on UNIX and then Linux. All through college and for my first 12 years ofprofessional experience, I used UNIX or Linux. OS X made it clear that Desktop Linux waspossible, it was just made by Apple and based on BSD Unix.
I didn���t really miss Linux, but when writing Sustainable Dev Environments with Docker and Bash, I never actually tried anything on a real Linux. I checked it all on WSL2 and that was that.
It turns out that running a devcontainer as root creates a lot of problems on Linux, and Ifigured the best way to truly solve them was to revisit day-to-day Linux. However, I have lost a lot of enthusiasm for messing with configs and trying to get something working on hardware notdesigned for it.
Since it doesn���t seem like you can easily run Linux on an M3 Mac, I decided to get a Linuxlaptop whose vendor officially supported some sort of Linux.
The HardwareMy requirements for hardware were:
Vendor must officially support at least one Linux distro, so I know it will work with theirhardware 13��� Laptop I could take with me Can use my LG Ultrafine 4K Thunderbolt monitor as a secondary displayThe Framework Laptop 13I considered System76 and Framework. Anecdotal reviews of System76hardware were mixed, and I liked the idea of a modular laptop, so I went with a Framework Laptop 13 DIY Edition (Intel�� Core��� Ultra Series 1). This is not the latest one they recently announced, but the now older model. I also opted for Intel as that was the only processor I could determine should support my Thunderbolt display. I could not figure out if AMD did, and didn���t want to find out that it didn���t.
My configuration was pretty basic. I stuck with the default processor, but opted for the���better��� of the two screens. I don���t need HDMI, Ethernet, or an SD card reader, so I went withthree USB-C ports and a USB-A port. I stuck with the boring black bezel.
Assembly and SetupIt was fun putting the laptop together - I haven���t shoved RAM into a socket in quite a few years, so it was cool seeing all the parts and putting it all together. Framework���s instructions were spot on and I had no real issues. Most everything either went into a secure socket or was magnetically attached. I did need to screw some tiny screws in, but they provided a nice screwdriver for their Torx screws.
Framework's instructions were spot onThe last time I did this, I was building a desktop PC and all the parts came in theseanti-static foil thingies in very basic packaging. Framework has gone the complete other way,with Apple-style packaging that was very easy to open and deal with.
That said, even though it���s all recylcable, it felt like a ton of waste. Not having somethingto recycle beats recyling any day of the week.
 At least it's all recylcable? View the full size image.
At least it's all recylcable? View the full size image. The DYI edition does not come with an OS, but Framework officially supports Ubuntu and Fedora.Since I���ve used Ubuntu as the basis for Docker containers, I went with that. I followedtheir instructions to flash a USB drive with an ISO and install from there. It all workedperfectly, exactly as they had documented.
I���ll discuss the software side in a minute
How Is The Hardware?While the Framework is by no means a Macbook Pro, it does feel high quality. Yes, it���s made ofplastic and has holes for fans. And yes, there are seams in it where the modular partsconnect. I���m fine with all of that.
The screen looked a lot better than I was expecting���the keyboard felt as good as the one on my MacbookThe screen looked a lot better than I was expecting. It seems retina-quality, or at leastnowhere near as bad as the $400 Lenovo Windows laptop I used for testing my book. It���s not as bright as myMac���s, but the only time I really noticed was when I was switching between the two computers.
The keyboard felt as good as the one on my Macbook Pro. My only quibbles are: 1) the placement of the why-is-there-always-an-unmappable-Fn-key, as it���s where Control is on my Mac, 2) a fucking Windows key logo, which I am not kidding almost made me not buy this thing, and 2) The F9 key, whose function I would describe as ���completely decimate your display setup and fuck up everything until you keep hitting it and eventually arrive at what you had before���.

 The location of the Fn and Control keys are swapped. And, of course, neither computer allows re-mapping the Fn key.
The location of the Fn and Control keys are swapped. And, of course, neither computer allows re-mapping the Fn key. The trackpad���well���it���s OK. It���s not as big as I���d like, but not as tiny as your average PC laptop���s. I find it extremely hardto use, but I also find the Magic Trackpad hard to use with Linux. It���s clear that Apple���s driver does some stuff to avoidmisclicks and other stuff. You also cannot control the scrolling speed, so I found myself making a lot of mistakes using bothTrackpads.
Battery life seems very good. Not Mac-level, but I have left it closed for 24 hours and the battery is still pretty well charged. As I type, it���s at 88% and the OS is telling me it���s got 5 hours left.
No issues with WiFi; I was able to connect to my iPhone for tethering. The fingerprint reader is more finicky than Apple���sTouchID, but worked almost every time.
The First Day Was RoughThe first day with Linux was rough for me. Mostly due to two things:
Muscle memory of keyboard shortcuts that aren���t set up or do other bizarre things on Linux. This is purely my fault. The trackpad/mouse configuration is woefully inadequate. Scroll speeds are 100MPH, acceleration is weird, and clicking with the trackpad causes numerous mislicks. Each click on either my Magic Trackpad or the laptop���s resulted in the mouse moving down a tiny bit. This was often enough to miss a click target. I have to assume Apple���s drivers account for this.As we���ll see, I somewhat tamed the keyboard shortcuts, though not sufficiently, and I ended upgetting a mouse which was much easier for me to control.
That said, after the first day, I realized I need to slow down and not try things until I knewthey would work. It felt like trying to type on a new keyboard layout or using my left hand formousing.
My WorkflowMy goal was to recreate as much of my workflow from the Mac to this new Linux laptop. In theend, I was mostly able to do so, however some apps or behaviors were simply not possible.
At a high level, my workflow when programming is something like this:
A terminal is for running command line apps and scripts. Neovim is my editor, however it runs as a GUI app, not in the terminal All development is done inside a Docker container, with source code mounted. This allowsediting in Neovim, but alleviates me from having to manage a bunch of version managers anddatabases. A launcher like Alfred responds to Cmd-Shift-Space to allow me to type the name of an app or initiate a web search. I use copy and paste liberally, and have a clipboard manager (Alfred, again) to managemultiple pastable things. I heavily rely on a core set of keyboard shortcuts supported by all Mac software (including bad citizens like Firefox and Electron). 1Password manages my passwords, which I unlock with TouchID. Cmd-Tab allows switching apps.. Inside Neovim (or through my launcher) I can look up API documentation using Dash. This meansif my cursor is in a .css file in the middle of max-height, I can type K and Dash willraise to the top, get focus, and show me the MDN docs for the max-height CSS property. For Mail, Calendar, Mastodon, BlueSky, or Plex, I expect to be able to Cmd-Tab or use my launcher to select them���they do not run as tabs in Firefox. Occasionally, I run the iPhone simulator, draw diagrams with Omnigraffle, or edit images withPixelmator. I rarely use the FinderI was able to get most of this working, however, keyboard shortcuts were challenging, copyand paste is confusing, and the API documentation options pale in comparison to Dash.
SoftwareI basically got to the setup below by working on real projects and, when I hit a wall, figuredout the Linux way of addressing the issue. This usually involved installing a lot of stuffwith sudo apt-get install and I did not write down any of what I did.
I quickly learned that the Ubuntu ���App Center��� should never be used unless the people buildingthe software say to use it. Several apps did not work until I uninstalled them via AppCenter and re-installed them on command line.
Below is a breakdown of which Mac app I use and what I used on Linux as a replacement.
Terminal Emulator
Terminal.app on Mac

Ghostty on Linux
����Gnome-terminal was very hard to configure and very limited. Ghostty allowed me to configure all of my keyboard shortcuts and worked well. I don't use it on Mac since Terminal.app works well and Ghostty killed my battery life. It doesn't seem to have that issue on Linux.
Vim GUI
VimR on Mac

Neovide on Linux
����Neovide has the most bizarre set of defaults I've ever seen. It is configured to animate every move of the cursor at an extremely slow animation rate. It is almost impossible to use. But, this can all be turned off very easily and the documentation is great.
I was also unable to get Neovide to behave as its own "app". I can Cmd-Tab to it as a separate window, but it shows a default icon and is considered a window of Ghostty. I tried creating magic .desktop files, but they didn't seem to do the trick.
Docker
Docker Desktop on Mac
Docker Daemon on Linux
����I installed Docker per their Linux instructions, which does not include a desktop GUI. That's fine, as I never use the GUI anyway. I followed the Linux post-install instructions to allow my user to access Docker. This was 1) because it was much easier than the rootless setup, and 2) required for me to get the details in the book right.
App Launcher
Alfred on Mac

Albert on Linux
����Albert looks inspried by Alfred and works pretty well. I had to configure a system-wide keyboard shortcut inside the Ubuntu/Gnome/??? Settings app. Albert doesn't seem able to do this, even though it has a configuration option for it. Fortunately, albert open will open, raise, and focus Albert.
Albert includes a clipboard manager, but it didn't work as well as Alfred's. I think this is because Linux lacks a system-wide clipboard and/or has multiple clipboards. I eventually gave up on relying on it.
Password Manager
1Password on Mac
1Password on Linux
����1Password worked great���once I got it installed
Installing 1Password and Firefox from App Center resulted in the browser extension not working and caused 1Password to ask for 2FA every time I opened it. It was actually not easy to delete both apps from App Center, but once I re-installed them, they both worked fine.
On Linux only, the browser extension will randomly open up 1Password's web page and ask to me log in, though if I ignore this, everything still works. This is what it does on Safari on macOS (except there it just doesn't work).
Even now, the browser extension can no longer be unlocked with the fingerprint scanner and I have to enter my passphrase frequently. It's extremely annoying. But at least it works, unlike on Safari, which just does not.
App and Window Switching Cmd-TabSwitch apps on Mac
Cmd-TabSwitch windows of all apps on Linux
����In theory, the Gnome task switcher allows switching between apps like on macOS. In practice, because I could not get Neovide to run as a separate ���app��� in the eyes of Gnome, I could not Cmd-Tab to it. I would have had to Cmd-Tab to Ghostty, then Cmd-~ to Neovide.
Fast API Doc Lookup
Dash on Mac

A Mess on Linux
����More on this below, but Zeal didn't work for me. I ended up using a hacky system of FirefoxPWA, DevDocs, and some config.
Fastmail
FastMail on Mac (as Safari Web App)
FastMail on Linux (as Firefox PWA)
����More on FirefoxPWA below, but this worked great.
Calendar
Fantastical on Mac
Fastmail on Linux (as Firefox PWA)
����More on FirefoxPWA below. I could not set a custom icon, but this works fine. FastMail's calender UI is pretty good.
Mastodon Client
Ivory on Mac

Mastodon.com on Linux (as Firefox PWA)
����First time really using Mastodon's web UI and it's not very good. But works well enough.
Bluesky Client
Bluesky on Mac (as Safari Web App)
Bluesky on Linux (as Firefox PWA)
����It's the same crappy UI in both.
Plex
Plex on Mac (as Safari Web App)
Plex on Linux (as Firefox PWA)
����Plex is plex.
Streaming Music
Apple Music on Mac
Apple Music on Linux (as Firefox PWA)
����Kindof amazed this existed and works! Firefox insists on "installing DRM" but also didn't seem to actually do anything. I think the Apple Music app is really just this web player. It works the same, and is still just as crappy as it was the day it launched as iTunes.
Messaging
Messages on Mac
����Nothing on Linux
����Messages is an Apple-only thing, so I was stuck taking out my phone a lot. I just didn't interact with my friends on text nearly as much.
Maps
Maps on Mac

Wego Here on Linux (as Firefox PWA)
����I have tried to avoid having Google in my life, and Apple's maps are pretty good, at least in the US. OpenStreetMap is servicable, but Wego Here is a bit nicer.
Keyboard Configurator
Keychron Launcher on Mac
����Nothing on Linux
����Chrome could not access USB no matter what I did. I chmod'ed everything in /dev/ to be owned by me and it didn't work. I ended up having to program the keyboard on my Mac, plug it into the Framework to check it and switch it back. Ugh.
RSS
Reeder on Mac

Feedbin on Linux (as Firefox PWA)
����Reeder has always required an RSS back-end. I initially used David Smith's excellent Feed Wrangler, but he sold it to Feedbin a few years back. I've never actually used the Feedbin web UI before, but it's pretty good! Installed as a PWA, it works great.
Light Image Editing
Preview on Mac

Krita on Linux
����Preview is an underrated app. It's truly amazing and demonstrates what Apple is���or at least used to be���capable of. It views PDFs, lets you edit them, sign them, save them. It views images and lets you crop them, adjust their colors, and do a lot of the 80 in 80/20 changes.
Krita is more like a Pixelmator or Photoshop. I had to consult the documentation to figure out how to crop an image. It's coloring didn't respect my desktop light/dark mode, and it made me miss a hugely helpful thing almost every mac has: keyword search of menus.
How it WorkedTo toot my own horn, every single dev environment built and passed tests without any changes. I pulled down arepo, ran dx/build to build images, ran dx/start to start containers,dx/exec bin/setup to set up the app inside the container and dx/execbin/ci to run all tests, which all passed.
Every single dev environment built and passed tests without any changesOnce I started actually making changes to my code, I did run into issues running all containers as root. I have sorted that out and the book will be updated to reflect this.
Aside from that, the experience was overall pretty great once I had installed everything andconfigured as much as I could to have keyboard shortcuts I could live with. To use this fulltime for software development, however, a few things would need to change.
Instead of ���The Good, The Bad, and The Ugly���, I���m going to list Dealbreakers, Papercuts, andPleasntries.
DealbreakersThere are three major issues that I would have to address to use Linux full time: clipboardcraptitude, keyboard shortcut inconsistency, and API documentation lookup.
Clipoard CraptitudeJust do a web search for ���Copy and Paste on Linux��� or ���Clipboards on Linux��� and you will find astream of confusion about the clipboard situation on Linux. I mean, just read this.
On Mac (and on Windows, I believe), there is a single system-wide clipboard. When you copysomething into it, it becomes available to paste anywhere. You can run an optional clipboardmanager that stores the history of stuff you have copied and allow you to paste it.
On Linux, the clipboard absolutely does not work this wayOn Linux, it absolutely does not work this way. There is a clipboard that���s filled when youselect text (and there may be one for X11 apps and one for Wayland apps?). There���s a systemclipboard, too, but it���s not always clear if you���ve copied to it, or if you are pasting fromit.
In Neovim, I could not tell what was happening. Usually :*p will paste and:*y will yank. Neither seemed to do what I expected. I ended up mappingAlt-C and Alt-V in NeoVim���s configuration to do copy and paste. It worked better, but not 100% of the time. Update I also realized that + is a better option than * because unlike on Mac, * on Linux is the ���whatever you had selected in X11��� and not ���the system clipboard���, which is +. FML.
I���m sure the way copy and paste works on Linux can be learned, but I found myself failing to successfully copy and/or paste on numerous occasions. Eventually, I learned to always type # in the terminal before pasting, because I never knew exactly what was going to be pasted there.
Albert���s clipboard manager didn���t allow pasting in all apps, and it didn���t store an accuratehistory of stuff I had copied (and pasted). I���m not sure how it works, but I just stopped usingit after a while.
I cannot fathom why this clipboard behavior is the default, and I would probably need to go on a deep dive to understand and remedy it, if I were to use Linux full time. It���s hard to overstate how frustrating it is to not have copy and paste work. Christ, it works better on iOS, which I thought had the worst copy and paste experience ever created.
Keyboard Shortcut InconsistencyOn a Mac, there are certain keyboard shortcuts that every app responds to, even bad citizenslike Firefox and Electron. Not so on Linux.
The source of this problem is, I guess, due to terminals relying on the Control key fornon-alphanumeric sequences. The Control key was adopted by Linux GUI apps as the key to usewhen you want to invoke a shortcut.
On a Mac, this has historically been either the ���Apple Key��� or now the Command (Cmd) key. Thiskey not only is irrelevant to any terminal emulator, it also is right under your left thumb.
 The Cmd key is within easy reach of your thumb.
The Cmd key is within easy reach of your thumb. This makes it ergonomically easy to use, even with other modifiers. Cmd-Shift or Cmd-Option are far easier to use than Control-Shift or Control-Alt.
I have a ton of muscle memory built up using the key under my thumb. On Mac, that key is Cmd or Super. On the Framework laptop, it���s Alt. I rarely use Control, since it���s almost never a modifier on Mac. I also have Caps Lock mapped as Escape, since I have not had a keyboard with Escape on it in quite a while (thus, I cannot use that for Control, which would be slightly better, ergonomically).
Apps on Linux do not have consistent keyboard shortcuts���Firefox provides no way to customize keyboard shortcutsTo make matters worse, apps on Linux do not have consistent keyboard shortcuts. Copying andPasting in Gnome-Terminal is different than in Firefox. And to make matters evenworse, Firefox provides no way to customize keyboard shortcuts. Youhave to use Ctrl-C to copy (e.g.).
What this means is twofold:
Any new app I install, I have to inspect its configuration to see if I can configure thekeyboard shortcuts I want. Namely, using the ���key under my thumb that is not Control��� as themodifier. When using Firefox, I have to internalize and use its Control-based shortcuts, since theycan���t be modified.To try to deal with this situation, I accepted that Linux uses Alt way more thanSuper, so I set the ���Windows Mode��� of my Keychron keyboard to have Alt asthe ���key under my thumb��� (which is the left space bar).
 The thumb key is easy to reach and my muscle memory can be re-used.
The thumb key is easy to reach and my muscle memory can be re-used. This meant switching from my desktop keyboard to the laptop wasn���t so jarring. It also meant, a few default shortcuts worked like on Mac.
For Firefox, the situation is dire, but I did find an extension that gave me some ability tocontrol the shortcuts. I was able to get it to allow changing tabs with Alt-{ and Alt-}, however it only works 90% of the time.
I���m not sure how I would deal with this day-to-day. I guess I���d just build up muscle memorythat when I���m in Firefox, I do things differently.
I do think this inconsistency is a contributor to some of my copy and pastewoes. I���m sure I thought I copied something when I didn���t, only to paste whatever waslast on the clipboard.
API Documentation LookupFor my entire career, I���m used to being able to quickly go from a symbol in my editor (which has always been some form of vi) to API documentation. Yes, I wrote a Java Doclet that generates vimdoc for the Java Standard Library. Nowadays, I use Dash.
I use it in two ways. First, I can use Alfred to lookup something in Dash, say ���max-height���, hit return, andhave Dash show me the docs directly:
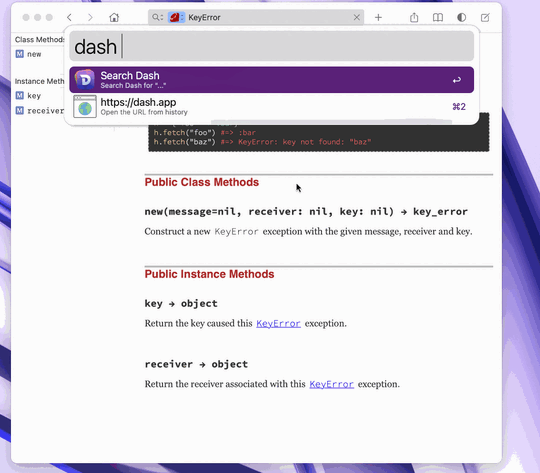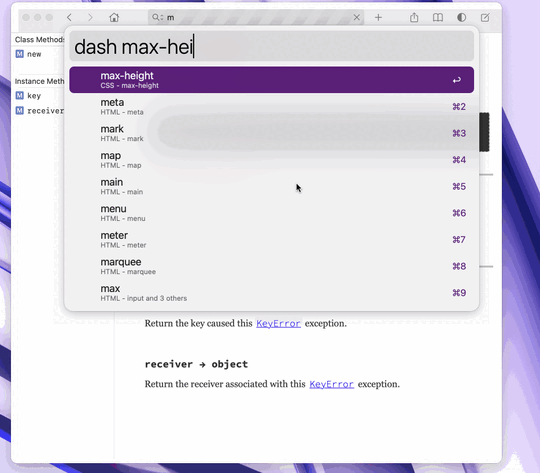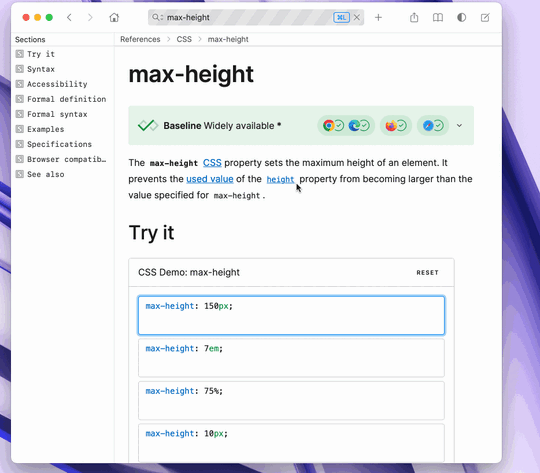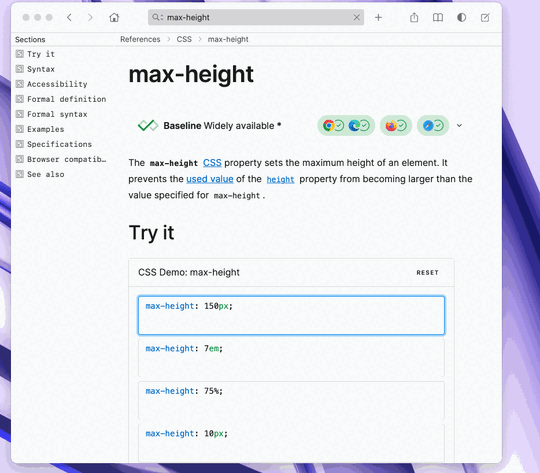
Second, I can do this directly from vim by placing the cursor on a symbol and hitting K. This brings up Dash, performing a search in the context of only Ruby documentation:
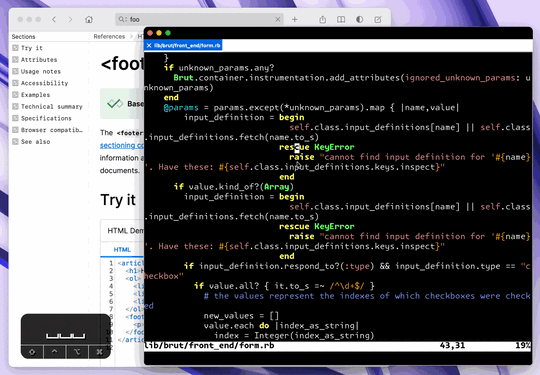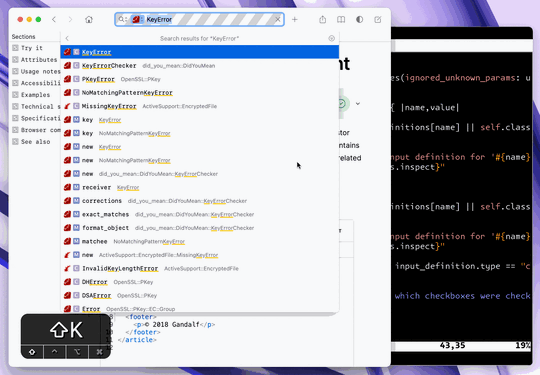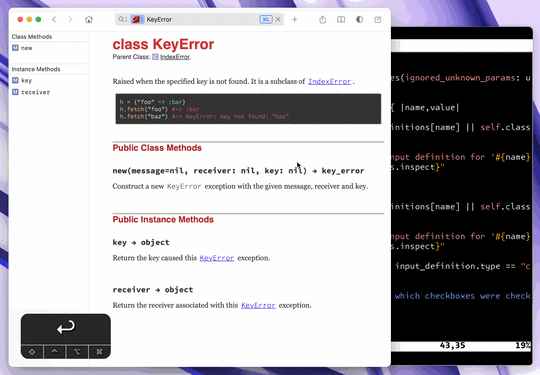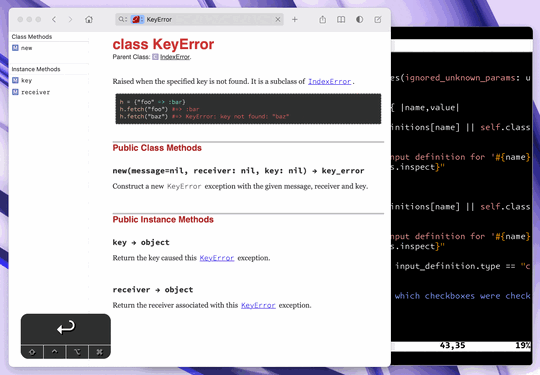
As you can see, it���s very fast, and easy to get used to. It���s nice to have docs at your fingertips, and it���snice having them in another app/window. I find a documentation-reading-based approach encourages exploration ofthe docs, which can be a great way to learn new stuff you can do with your existing libraries.
One bit that you can���t see from these examples is that Dash allows you to install documentationfor pretty much any Ruby Gem (or other code library). That means I can have esoteric stufflike the Ruby Playwright bindings or the Faker gem���s RubyDoc available. Searching in Dash isfar faster than web searching or trying to use GitHub.
First, I tried Zeal. Zeal did not seem to have a way to installdocumentation for arbitrary Ruby Gems. Worse, I could not ever get Zeal to get focus, raise tothe top, and show me search results. I tried a lot of options and it just never worked.
Next, I tried DevDocs. I ran DevDocs in a FirefoxPWA (more on thatbelow), so it behaved like a separate app. I configured both Albert and Neovim to useopen to open a magic URL that would search DevDocs and show the results in thePWA.
This behavior works about 90% of the time (the other 10% it shows as different URL). DevDocsdoes not allow installing arbitrary documentation. You get whatever they have, and they aren���tlooking to install docs for RubyGems.
This sucks for my workflow. I would have to sort this out. I guess devs today who aren���tletting AI write their code are just hitting Cmd-Space and seeing what VSCode shows them? Ijust can���t work that way.
PapercutsThese are issues that were annoying, but I could live with.
Mouse/Trackpad scrolling speed cannot be adjusted. I could not find a way that worked onWayland and X11. I did find a way to configure my extra mouse buttons and extra mousewheel, usinginput-remapper. It sometimes just stops working and needs to be restarted, but it did exactlywhat I wanted. Too many ways to install software. Sometimes you use App Center, sometimes you useapt-get, sometimes you download a file and dump it into your path, sometimes you do somethingelse. This is how it was 20 years ago, and it still is like this and it sucks. No system wide text replacement. I can type dtk anywhere on my Mac and it replaces it withmy email address. I found a version of this for Linux and it just didn���t work. I ultimatelyprogrammed a macro into my Keychron keyboard. The font situation is baffling. I���m going to set aside how utterly hideous most of the fonts are. For some reason, Linux replaces fonts in websites, making font-family totally useless.If I specify, say, Helvetica, 'URW Gothic', sans-serif, and URW Gothic is installed, Linuxwill send Noto Sans, because that is a replacement for Helvetica. I can���t understand thereasoning for this. No ApplePay on websites means using PayPal or swtiching to my phone. Cannot copy on iPhone and paste on Linux or vice-versa. Web-only access to iCloud. Apple is not good at web apps. Entering non-ASCII characters is either really weird or something I have to learn. Control-Shift-U-2026-Enter to type an ellipsis just���sucks. I think there���s a better way, so to be researched.PleasantriesI realize this is a lot of criticism, but I did actually miss just how fun it was to use anoperating system that I could tweak, and that wasn���t being modified by whims of Apple designerslooking to get promoted. While Apple is great at hardware, and good at software/hardwareintegration, their software has gotten much worse over the last 10 years, often foistingzero-value features on users.
Many apps I use are web apps, and that those apps are pretty goodThe other thing that surprised me was just how many apps I use are web apps, and that those apps are pretty good, especially when run as a standalone ���web app��� and not as a tab in Firefox.
Ironically, Apple provides a great UI for doing this via Safari Web Apps (it���s too bad they also hamstring what a PWA can do on iOS). The situation on Linux is rather dire. Chrome supports it, but it���s cumbersome, and Firefox, of all browsers, provides zero support for it. But, FirefoxPWA to the rescue!
Firefox PWAThe good and bad parts of Linux are both its flexibility and configurability. FirefoxPWA is nodifferent. The general protocol of a ���Web App Running as a Standalone App��� is, in my mind:
Separate app in the app switcher, complete with icon and title. Navigation within the app���s website stays in the app. Navigating outside the app���s website opens in the system browser. Activating or opening the app from another context (e.g. app launcher or command line) bringsthe app into focus, but does not reload the app���s start page.This is possible with FirefoxPWA, but requires some tweaking.
Once you���ve created your app and relaunched it, it will use the Web Manifest to get icons andnames. It does not respect the scope attribute, so by default all links open in the PWA and not Firefox. By default, when a PWA is launched or activated by the OS, it will reload the start page. It also won���t allow you to override icons. Well, it will, it just doesn���t work.
Fortunately, the author(s) of FirefoxPWA have done a good job with configuration anddocumentation. In any app, you can do Control-L to go to a URL and typeabout:config to get into the settings.
From there, to fix app activation, set firefoxpwa.launchType to ���3���. To ensure URLs outside the app are opened in Firefox, set firefoxpwa.openOutOfScopeInDefaultBrowser to true, and setfirefoxpwa.allowedDomains to the domains of the app.
I couldn���t figure out a way to make these the defaults, but this is all one time setup, soworked fine. Once I had this setup, Mastodon, Bluesky, Plex, and Fastmail all behaved liketheir own apps.
DevDocsWhile DevDocs isn���t perfect, when used with FirefoxPWA, it is serviceable. DevDocs has a URLformat that will perform a search. Basically, devdocs.io/#q=keyword will search all yourconfigured docs for ���keyword���, and devdocs.io/#q=ruby keyword will search only Ruby docs for���keyword���.
Thus, I needed to be able to run open devdocs.io/#q=keyword and have it open the DevDocs PWAand load the given URL. This was somewhat tricky.
First, I had to change firefoxpwa.launchType for DevDocs to ���2���, which replaces the existingtab with whatever the URL is. This requires setting ���Launch this web app on matching website���for DevDocs and setting automatic app launching for the extension.
The result is that open devdocs.io/#q=ruby keywdord will open that URL in regular Firefox,which triggers Firefox PWA to open that URL in the DevDocs web app. And this works about90% of the time.
FirefoxPWA installs Firefox profiles for each Web App, but I could not figure out how to usethis to open a URL directly in the DevDocs PWA. There might be a way to do it that I have notdiscovered.
Other Cool StuffAlt-click anywhere in a window to drag it. Yes! I had forgot how much I loved being able to dothis. Mouse over a window to activate���but not raise���it. Makes it really handy to enter text ina browser window while observing dev tools.
I also missed having decent versions of UNIX command-line tools installed. macOS���s versionsare woefully ancient and underpowered.
Time will tell if I take advantage of Framework���s upgradeability. At the very least, I canswap out ports if needed.
Where I Go from HereI still need to update Sustainable Dev Environments with Docker and Bash, and I plan to dothat entirely on the Framework laptop. My book-writing toolchain is Docker-based, so shouldwork.
Depending on how that goes, I may spend more time addressing the various major issues andpapercuts to see if I could use it for real, full time, for web development and writing.
October 10, 2024
A Simple Explanation of Postgres' Timestamp with Time Zone
Postgres provides two ways to store a timestamp: TIMESTAMP and TIMESTAMP WITH TIME ZONE (or timestamptz).I���ve always recommended using the later, as it alleviates all confusion about time zones. Let���s see why.
What is a ���time stamp���?The terms ���date���, ���time���, ���datetime���, ���calendar���, and ���timestamp��� can feel interchangeable but the are not. A ���timestamp��� is a specific point in time, as measured from a reference time. Right now it is Oct 10, 2024 18:00 in the UK, which is the same timestamp as Oct 10 2024 14:00 in Washington, DC.
To be able to compare two timestamps, you have to include some sort of reference time. Thus, ���Oct 10, 202518:00��� is not a timestamp, since you don���t know what the reference time is.
Time zones are a way to manage these references. They can be confusing, especially when presenting timestamps orstoring them in a database.
Storing time stamps without time zonesConsider this series of SQL statements:
db=# create temp table no_tz(recorded_at timestamp);CREATE TABLEdb=# insert into no_tz(recorded_at) values (now());INSERT 0 1adrpg_development=# select * from no_tz; recorded_at ---------------------------- 2024-10-10 18:03:11.771989(1 row)The value for recorded_at is a SQL timestamp which does not encode timezone information (and thus, I would argue, is not an actual time stamp). Thus, to interpret this value, there must be some reference. In this case, Postgres uses whatever its currently configured timezone is. While this is often UTC, it is not guaranteed to be UTC.
db=# show timezone; TimeZone ---------- UTC(1 row)This value can be changed in many ways. We can change it per session with set session timezone:
db=# set session timezone to 'America/New_York';SETOnce we���ve done that, the value in no_tz is, technically, different:
db=# select * from no_tz; recorded_at ---------------------------- 2024-10-10 18:03:11.771989(1 row)Because the SQL timestamp is implicitly in reference to the session or server���s time zone, this value is nowtechnically four hours off, since it���s now being referenced to eastern time, not UTC.
This can be solved by storing the referenced time zone.
Storing timestamps with time zonesLet���s create a new table that stores the time both with and without a timezone:
CREATE TEMP TABLE tz_test( with_tz TIMESTAMP WITH TIME ZONE, without_tz TIMESTAMP WITHOUT TIME ZONE);We can see that, by default, the Postgres server I���m running is set to UTC:
db=# show timezone; TimeZone ---------- Etc/UTCNow, let���s insert the same timestamp into both fields:
INSERT INTO tz_test( with_tz, without_tz ) VALUES ( now(), now() );The same timestamp should be stored:
db=# select * from tz_test; with_tz | without_tz ------------------------------+--------------------------- 2024-10-10 18:09:35.11292+00 | 2024-10-10 18:09:35.11292(1 row)Note the difference in how these values are presented. with_tz is showing us the time zone offset���+00. Let���s change to eastern time and run the query again:
db=# set session timezone to 'America/New_York';SETdb=# select * from tz_test; with_tz | without_tz ------------------------------+--------------------------- 2024-10-10 14:09:35.11292-04 | 2024-10-10 18:09:35.11292(1 row)The value for with_tz is still correct. There���s no way to misinterpret that value. It���s the same timestamp weinserted. without_tz, however, is now wrong or, at best, unclear.
Why not Just Always stay in UTC?It���s true that if you are always careful to stay in UTC (or any time zone, really), the values for a TIMESTAMPWITHOUT TIME ZONE will be correct. But, it���s not always easy to do this. You saw already that I changed thesession���s timezone. That a basic configuration option can invalidate all your timestamps should give you pause.
Imagine an ops person wanting to simplify reporting by changing the server���s time zone to pacific time. If yourtimestamps are stored without time zones, they are now all wrong. If you had used TIMESTAMP WITH TIME ZONE itwouldn���t matter.
Always use TIMESTAMP WITH TIME ZONEThere���s really no reason not to do this. If you are a Rails developer, you can make Active Record default tothis like so:
# config/initializers/postgres.rbrequire "active_record/connection_adapters/postgresql_adapter"ActiveRecord::ConnectionAdapters::PostgreSQLAdapter.datetime_type = :timestamptzThis can be extremely helpful if you are setting time zones in your code. It���s not uncommon to temporarilychange the time zone to display values to a user in their time zone. If you write a timestamp to the databasewhile doing this, TIMESTAMP WITH TIME ZONE will always store the correct value.
October 1, 2024
Custom Elements Reacting to Changes
In the endnotesof my post on creating a sorting and filter table using customelements,I mentioned that my solution would not work if the inside was modified. This postoutlines how to address that using MutationObserver, and it���s kinda gnarly.The Problem - Your DOM Changes out From Under You
The contract of the as that if sort-column was set, the table���s rows would be sorted, and iffilter-terms was set, only rows matching the filter would be shown. That contract breaks if the inside of the is modified.
Ideally, whatever behavior an HTML Web Component bestows upon the DOM it wraps is bestowed to whatever is inthere, no matter when or how it got there. The most acute version of this problem is how the elements areinitialized when the DOM is loaded.
Element Initialization And DOMContentLoadedIn my previous solution you���ll note that I had to call customElements.define inside aDOMContentLoaded event, or the custom elements wouldn���t have access to the DOM they wrap in order to do whatthey need to do.
To explain this secondary point more, here is my understanding of the order of operations.
In the tag, customElements.define("fancy-table",FancyTable) is called, which tells the browser that is a custom element implemented by FancyTable. As the DOM is loaded, when is parsed, a FancyTable is created and connectedCallback() is called. At this point, this.innerHTML is empty, since the browser has not examined anything beyond the element it���s currently parsing. The rest of the DOM is parsed. There is no callback for this as part of the custom element spec, so the custom elements essentially don���t do anything at all.By moving customElements.define into DOMContentLoaded, things are reversed:
The DOM is parsed and loaded. customElements.define(...) is called. This causes the browser to call connectedCallback on all the custom elements. At this point each elements��� innerHTML is present, so this.querySelector and friends work.Both this startup issue and the need to handle changes made external to the element can be solved by using a MutationObserver.
MutationObserver Tells You When the DOM ChangesIf you recall my implementation, each custom element classimplemented a method called #update() that did whatever the element was supposed to do. #update() was calledfrom connectedCallback as well as attributeChangedCallback. This provided centralization of the customelements��� core behavior.
To address both the startup problem and the ���someone changed our DOM��� problem, we need to call #update()whenever the DOM changes. We can arrange that with MutationObserver.
It works like so:
// 1. Create a callback called when something changes// mutationRecords is an array of MutationRecord instances// describing the changesconst mutated = (mutationRecords) => {}// 2. Create the observer// NOTE: nothing is being observed yetconst observer = new MutationObserver(mutated)// 3. Start observing changes to `element`, based on// the contents of `options` (see below)observer.observe(element,options)For a custom element to observe changes to itself, it will need to call observe like so:
observer.observer( this, { subtree: true, // observe `this` and all children childList: true, // get notified about additions/removals })You can also observe attribute and CDATA changes if you like, but for my purposes here, it���s just enough toknow that any element inside the subtree was added or removed. And, it���s not necessary to know what happened. I just need to call #update() whenever there is a change, so the element can re-sort and re-filter the table���s rows.
The problem is that #update() creates changes that are observed that trigger the observer that then call#update(), thus creating an infinite loop.
Pausing Observation While Changing ThingsThe way I addressed this was to stop observing changes before calling #update(), then resuming observationagain after that. I���m assuming no DOM changes are happening during #update() because I think all changes tothe DOM must happen in a single, synchronous thread (though I���m not 100% sure).
First, I created two method, #observeMutations and #stopObservingMutations:
// Inside FancyTable#mutationObserver = null;#mutated = () => { this.#stopObservingMutations(); this.#update(); this.#observeMutations();};#observeMutations() { this.#stopObservingMutations(); if (!this.#mutationObserver) { this.#mutationObserver = new MutationObserver(this.#mutated); } this.#mutationObserver.observe(this, { subtree: true, childList: true });}Next, observation has to start when the element is connected, thus it���s called in connectedCallback:
connectedCallback() { this.#observeMutations() this.update();}Lastly, the callback will stop observation, call #update() and then resume observation:
#mutated = (records,observer) => { if (this.update) { this.#stopObservingMutations() this.#update(); this.#observeMutations() }}In general, this worked, however it needed to be added to all my custom elements. Since it���s so complicated, I created a base class to hold this and slightly changed the code from the previous post. You can see it all on CodePen. Notice that the elements are no longer defined inside a DOMContentLoaded event handler.
When you add as new row to the table, the form will essentially add a ������ to the end of the table���s . If you first sort or filter the table, you���ll notice that the row ends up sorted in the right place. Here is how things happen: The form is submitted. The form���s submit handler creates a new and puts two elements in it. The form���s submit handler locates the ���s and calls appendChild(tr). The new is added as the last row of the table. This triggers the mutation observer, so FancyTable���s #mutate is called, which pauses observation and calls #update() #update() then sorts the table based on its sort-column and sort-direction attributes. #update() completes and mutation observation is resumed.
This all happens in the blink of an eye, so it appears that the new row is inserted into the right place.
The Browser is Powerful, but Could Do MoreI���m glad MutationObserver exists so that these issues could be solved. I do wish the custom elements API hadricher callbacks so all of this could be avoided. Much like attributeChangedCallback is called when observedattributes are changed, it would be nice to have, say, domChangedCallback to be invoked whenever the DOM waschanged, and have it not result in an infinite loop if the DOM was changed from that callback.
Still, the existence of MutationObserver demonstrates the web���s power and flexibility. And whileMutationObserver can be complex, our degenerate case didn���t end up requiring too much code. And it all seemsto be working pretty well.
Other NotesWhile working on this, I realized that using nth-child(odd) and hidden doesn���t work properly. There is noway I could determine to properly select even and odd tr elements that were not hidden using only CSS. It seems nth-child just doesn���t work that way.
So, what I did was added a #stripe() helper that goes through each non-hidden and addsdata-stripe="odd" or data-stripe="even", which CSS then uses. I hate to have to use a data- element, butagain, this is the depth of the platform. If you can���t do something at a high level, you can do it at a lowlevel.



{kind=link}