
Заметки о практическом машинном обучении
Данный пост описывает мои личные наблюдения собранные во время работы над практической реализации задач решаемых при помощи машинного обучения (machine learning, ML). Данный топик всегда интересовал меня, наряду с другими областями, такими как обработка естественного языка (natural language processing, NLP), data mining, и имеющих к ним некоторое отношение технологий big data. Хотя я имею некоторый теоретический бэкграунд, достаточный для понимания применимости того или иного алгоритма, но все эти области интересуют меня в первую очередь с практической точки зрения.
Первый опыт практического применения машинного обучения я получил 2002-2003 годах, после выхода статьи Paul Graham Plan for Spam, которая описывала простой алгоритм для классификации спамерских почтовых сообщений. Простота алгоритма сподвигнула нашу группу, работающую над продуктом для фильтрации почтового трафика "Дозор-Джет, на написание соответствующего модуля для нашей системы. При реализации этого модуля мы первый раз наткнулись на тот факт, что основная сложность и трудоемкость системы не в алгоритме, а в сопутствующих вещах - собирании и очистке данных для тренировки моделей, анализе результатов, исправлении фальшивых срабатываний и т.п.
Позже, когда я стал работать в McAfee/Intel Security, я продолжал эксперементировать с различными алгоритмами и библиотеками, плюс получил большие теоретические знания благодаря онлайн курсам: ML Class (Andrew Ng) & AI Class (Peter Norwig & Sebastian Thrun), плюс последующие классы на Coursera. 2 года назад я перешел в новую группу, которая работает над применением технологий машинного обучения для задач информационной безопасности, что позволило мне получить больше практического опыта в этой области. На основании этого опыта, я и решил написать этот пост.
Как получить хорошие результаты при использовании машинного обученияРезультат применения методов машинного обучения к различным задачам зависит от многих факторов, включая:
Понимание того, какую проблему мы хотим решить. Это достаточно важный пункт - зная о том, какую задачу мы хотим решить, мы имеем информацию об ограничениях накладываемых на конкретные алгоритмы (потребление ресурсов, скорость работы, и т.п.), понимаем насколько критичны ошибки при применении алгоритма, как решение задачи влияет на наш бизнес, и т.д. Часто, "достаточно хорошее", но дешевое решение может быть предпочтительней "наилучшего", но очень дорогого с точки зрения разработки, ресурсов и т.п. (хороший пример этого - история Netflix prize, когда выигравший алгоритм так и не был реализован, а компания остановился на чуть-чуть худшем решении которое было дешевле в реализации);Хорошее знание предметной области. На мой взгляд - это важнейший фактор успеха проекта. Без знания предметной области очень трудно (если вообще возможно) построить хорошую модель. Хорошее знание предметной области позволяет сконцентрироваться на ключевых факторах (или их комбинациях) на базе которых будет построена модель, игнорировать ненужные данные, использование которых не даст выигрыша в качестве (или вообще приведет к деградации качества), выбрать правильные методы сбора, извлечения и кодирования данных, оценить применимость того или иного алгоритма, и т.п.;Наличие хорошей таксономии для задач классификации. В таких задачах необходимо отнести входные данные (текст, или что-то другое) к одному (или нескольким) предопределенным классам. В некоторых случаях, таксономии уже определены, и в задачу проекта может входить построение решения которое будет использовать эту таксономию. И иногда, существующие таксономии не совсем удобно применять с алгоритмами машинного обучения. Например, если имеется несколько "близких" друг к другу классификаций - в этом случае, алгоритмы классификации делают ошибки относя входные данные к "родственным" классам, хотя это не всегда правильно. Например, если вы имеете класс "Спорт" и класс "Азартные игры", может быть достаточно тяжело различить сайты которые обсуждают результаты футбольных матчей от сайтов которые дают советы по ставкам на футбольные матчи;Понимание применимости того или иного алгоритма к классу задач. Сейчас не нужно быть кандидатом наук для применения машинного обучения в практиеческих задачх. Но необходимо иметь понимание того, какие классы алгоритмов существуют, к каким задачам они могут применяться, требования к ресурсам, чувствительность к качеству тренировочных данных, и т.д. (В настоящее время существует огромное количество информации на эту тему - онлайн курсы, книги, документация к библиотекам и т.д., так что это только вопрос времени на ознакомление). Очень часто, наилучший результат приносят не индивидуальные алгоритмы, а алгоритмы основанные на ансамблях из разных моделей, каждая из которых сама по себе дает "средний" результат, например, Random Forest, различные реализации Boosted Trees, и т.д.;Применяемые методы сбора, извлечения и кодирования данных. Чистота и баланс данных. Для разных задач существуют различные методы сбора данных, но основная цель - получить качественный набор тренировочных данных, по возможности не содержащих некоректные данные (хотя это очень дорогое удовольствие для больших объемов данных). В некоторых случаях, при сборе данных необходимо также соблюдать баланс, чтобы объем данных одного класса не превосходил объем данных других классов (хотя существуют некоторые методы решения этой проблемы при построении моделей);Выделение ключевых факторов на базе которых будет построена модель. Также крайне важный фактор влияющий на качество модели - включение лишних факторов в модель может ухудшить ее качество или увеличить потребление ресурсов при построении модели. Также важную роль часто играет применение не индивидуальных факторов, а комбинаций разных независимых факторов;Отсутствие разделения на "разработчиков" и "ученых". Это больше организационный фактор, но он также важен. Иногда бывает, когда "ученые" и "разрабочики" относятся к совершенно разным группам, имеющим очень слабую связь. В таких случаях, при реализации проекта иногда возникает ситуация, когда "ученые" решают в пользу того или иного алгоритма, которые показывает очень хорошие результаты в лабораторых условиях, но который очень тяжело применять в реальной обстановке. Например, он очень требователен к ресурсам, тяжел в реализации, очень медленный и т.д. Лучше избегать такого разделения и позволить всем группам вместе работать над проектом с самого начала.Машинное обучение: теория и практика…Многие люди, не знакомые близко с машинным обучением, когда слышат этот термин, представляют себе листы бумаги исписанные формулами, какой-нибудь заумный код, и т.п. В реальности же, основная трудоемкость таких проектов часто приходится не на реализацию алгоритмов (существует огромное количество готовых библиотек), а на аналитические и инженерные задачи:
сбор и проверка данных. Это одна из самых трудоемких частей. Для этих задач существуют готовые библиотеки и утилиты, но все равно, иногда возникает необходимость в написании чего-то специального. После сбора данных, необходимо убедиться в том что мы действительно собрали правильные данные. Например, если вы занимаетесь классификацией веб страниц, то может возникнуть ситуация, когда содержимое сайта не соотвествует той классификации которая была ему когда-то присвоена - ПО сайта может возвращать сообщение об ошибке, сайт может сменить владельца, он может быть хакнут и помимо нормального содержимого он будет содержать какой-то другой текст (например, рекламу виагры, или порно-сайтов). Для проверки данных часто возникает необходимость в написании специализированных утилит, кросс-проверке данных и т.п.;анализ и выбор факторов (features) которые войдут в модель. Это одна из самых важных частей работы - необходимо понять, какие из факторов являются основными для получения качественных моделей. Для этого необходимо хорошо понимать предметную область, поскольку зачастую качество моделей зависит не от единичных факторов, а, например, от их комбинаций. Для некоторых областей, таких как классификация текстов, часто необходимо выполнить и выбор факторов (feature selection) (для классификации текстов - это слова в тексте), иначе модель будет слишком большая, что приведет к увеличенному потреблению ресурсов и замедлениям при тренировке моделей;извлечение данных - как мы выделяем нужные нам факторы. Например, при работе с текстовыми данными, нам может быть необходимо привести все входные данные к одной и той же кодировке, или необходимо выделить только определенную часть данных. Например, при анализе почтового трафика в поисках спама, мы можем игнорировать некоторые заголовки;анализ полученных результатов - еще одна трудоемкая часть. Существуют разные методы оценки качества моделей, зависящие от типа: классификация, кластеризация и т.п., но основная работа приходится на то чтобы понять откуда возникают фальшивые срабатывания и т.п. По результатам анализа может понадобиться настройка параметров моделей, изменение набора тренинговых данных, анализ влияния различных факторов и т.п.;настройка параметров модели. Многие алгоритмы имеют набор параметров которые могут влиять на качество моделей. Нет универсального набора параметров который бы подходил ко всем задачам, поэтому обычно производят построение моделей для диапазонов значений, и выбирают параметры приведшие к построению наилучшей модели. Остальные модели тоже могут принести пользу - например, все построенные модели могут использоваться для построения мета-модели, которая позволит получить лучшее качество чем одна модель;деплоймент моделей в эксплуатацию. Сюда входит: обеспечение беспрерывной работы системы, проверку результатов на реальных данных и т.п.На практике, лишь в небольшом количестве проектов возникает необходимость в новых алгоритмах или реализации существующих алгоритмов с нуля. В большинстве своем, практически всегда используются уже готовые библиотеки и фреймворки, такие как Scikit-Learn для Python, Apache Mahout, Apache Spark ML, H2O, XGBoost, библиотеки для R, и многие другие - эти библиотеки разрабатываются большими коллективами, протестированны для разных задач, и большая часть ошибок уже исправлена. Имея на руках готовые данные, и понимая применимость того или иногда алгоритма, с помощью этих библиотек можно быстро построить модели, оценить их применимость к вашей задаче, и принять решение о реализации.
Мои впечатления на эту тему совпадают с фразой и иллюстрацией из интересной статьи Hidden Technical Debt in Machine Learning Systems опубликованной сотрудниками Google: "It may be surprising to the academic community to know that only a tiny fraction of the code in many ML systems is actually devoted to learning or prediction (Для научных сотрудников может быть удивительным, что только мала часть кода во многих системах построенных на алгоритмах машинного обучения, в действительности относится к обучению или предсказанию)".
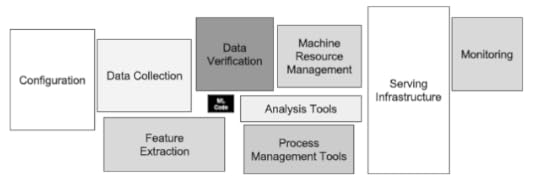
* * *В данном посте я пытался сформулировать свой опыт полученный при реализации конкретных проектов. В следующих постах я попытаюсь раскрыть те или иные пункты более подробно (насколько это не противоречит моему рабочему контракту :-). Я буду очень благодарен комментариям от моих читателей - может быть что-то описано не совсем ясно, тогда я постараюсь дополнить этот пост.
Первый опыт практического применения машинного обучения я получил 2002-2003 годах, после выхода статьи Paul Graham Plan for Spam, которая описывала простой алгоритм для классификации спамерских почтовых сообщений. Простота алгоритма сподвигнула нашу группу, работающую над продуктом для фильтрации почтового трафика "Дозор-Джет, на написание соответствующего модуля для нашей системы. При реализации этого модуля мы первый раз наткнулись на тот факт, что основная сложность и трудоемкость системы не в алгоритме, а в сопутствующих вещах - собирании и очистке данных для тренировки моделей, анализе результатов, исправлении фальшивых срабатываний и т.п.
Позже, когда я стал работать в McAfee/Intel Security, я продолжал эксперементировать с различными алгоритмами и библиотеками, плюс получил большие теоретические знания благодаря онлайн курсам: ML Class (Andrew Ng) & AI Class (Peter Norwig & Sebastian Thrun), плюс последующие классы на Coursera. 2 года назад я перешел в новую группу, которая работает над применением технологий машинного обучения для задач информационной безопасности, что позволило мне получить больше практического опыта в этой области. На основании этого опыта, я и решил написать этот пост.
Как получить хорошие результаты при использовании машинного обученияРезультат применения методов машинного обучения к различным задачам зависит от многих факторов, включая:
Понимание того, какую проблему мы хотим решить. Это достаточно важный пункт - зная о том, какую задачу мы хотим решить, мы имеем информацию об ограничениях накладываемых на конкретные алгоритмы (потребление ресурсов, скорость работы, и т.п.), понимаем насколько критичны ошибки при применении алгоритма, как решение задачи влияет на наш бизнес, и т.д. Часто, "достаточно хорошее", но дешевое решение может быть предпочтительней "наилучшего", но очень дорогого с точки зрения разработки, ресурсов и т.п. (хороший пример этого - история Netflix prize, когда выигравший алгоритм так и не был реализован, а компания остановился на чуть-чуть худшем решении которое было дешевле в реализации);Хорошее знание предметной области. На мой взгляд - это важнейший фактор успеха проекта. Без знания предметной области очень трудно (если вообще возможно) построить хорошую модель. Хорошее знание предметной области позволяет сконцентрироваться на ключевых факторах (или их комбинациях) на базе которых будет построена модель, игнорировать ненужные данные, использование которых не даст выигрыша в качестве (или вообще приведет к деградации качества), выбрать правильные методы сбора, извлечения и кодирования данных, оценить применимость того или иного алгоритма, и т.п.;Наличие хорошей таксономии для задач классификации. В таких задачах необходимо отнести входные данные (текст, или что-то другое) к одному (или нескольким) предопределенным классам. В некоторых случаях, таксономии уже определены, и в задачу проекта может входить построение решения которое будет использовать эту таксономию. И иногда, существующие таксономии не совсем удобно применять с алгоритмами машинного обучения. Например, если имеется несколько "близких" друг к другу классификаций - в этом случае, алгоритмы классификации делают ошибки относя входные данные к "родственным" классам, хотя это не всегда правильно. Например, если вы имеете класс "Спорт" и класс "Азартные игры", может быть достаточно тяжело различить сайты которые обсуждают результаты футбольных матчей от сайтов которые дают советы по ставкам на футбольные матчи;Понимание применимости того или иного алгоритма к классу задач. Сейчас не нужно быть кандидатом наук для применения машинного обучения в практиеческих задачх. Но необходимо иметь понимание того, какие классы алгоритмов существуют, к каким задачам они могут применяться, требования к ресурсам, чувствительность к качеству тренировочных данных, и т.д. (В настоящее время существует огромное количество информации на эту тему - онлайн курсы, книги, документация к библиотекам и т.д., так что это только вопрос времени на ознакомление). Очень часто, наилучший результат приносят не индивидуальные алгоритмы, а алгоритмы основанные на ансамблях из разных моделей, каждая из которых сама по себе дает "средний" результат, например, Random Forest, различные реализации Boosted Trees, и т.д.;Применяемые методы сбора, извлечения и кодирования данных. Чистота и баланс данных. Для разных задач существуют различные методы сбора данных, но основная цель - получить качественный набор тренировочных данных, по возможности не содержащих некоректные данные (хотя это очень дорогое удовольствие для больших объемов данных). В некоторых случаях, при сборе данных необходимо также соблюдать баланс, чтобы объем данных одного класса не превосходил объем данных других классов (хотя существуют некоторые методы решения этой проблемы при построении моделей);Выделение ключевых факторов на базе которых будет построена модель. Также крайне важный фактор влияющий на качество модели - включение лишних факторов в модель может ухудшить ее качество или увеличить потребление ресурсов при построении модели. Также важную роль часто играет применение не индивидуальных факторов, а комбинаций разных независимых факторов;Отсутствие разделения на "разработчиков" и "ученых". Это больше организационный фактор, но он также важен. Иногда бывает, когда "ученые" и "разрабочики" относятся к совершенно разным группам, имеющим очень слабую связь. В таких случаях, при реализации проекта иногда возникает ситуация, когда "ученые" решают в пользу того или иного алгоритма, которые показывает очень хорошие результаты в лабораторых условиях, но который очень тяжело применять в реальной обстановке. Например, он очень требователен к ресурсам, тяжел в реализации, очень медленный и т.д. Лучше избегать такого разделения и позволить всем группам вместе работать над проектом с самого начала.Машинное обучение: теория и практика…Многие люди, не знакомые близко с машинным обучением, когда слышат этот термин, представляют себе листы бумаги исписанные формулами, какой-нибудь заумный код, и т.п. В реальности же, основная трудоемкость таких проектов часто приходится не на реализацию алгоритмов (существует огромное количество готовых библиотек), а на аналитические и инженерные задачи:
сбор и проверка данных. Это одна из самых трудоемких частей. Для этих задач существуют готовые библиотеки и утилиты, но все равно, иногда возникает необходимость в написании чего-то специального. После сбора данных, необходимо убедиться в том что мы действительно собрали правильные данные. Например, если вы занимаетесь классификацией веб страниц, то может возникнуть ситуация, когда содержимое сайта не соотвествует той классификации которая была ему когда-то присвоена - ПО сайта может возвращать сообщение об ошибке, сайт может сменить владельца, он может быть хакнут и помимо нормального содержимого он будет содержать какой-то другой текст (например, рекламу виагры, или порно-сайтов). Для проверки данных часто возникает необходимость в написании специализированных утилит, кросс-проверке данных и т.п.;анализ и выбор факторов (features) которые войдут в модель. Это одна из самых важных частей работы - необходимо понять, какие из факторов являются основными для получения качественных моделей. Для этого необходимо хорошо понимать предметную область, поскольку зачастую качество моделей зависит не от единичных факторов, а, например, от их комбинаций. Для некоторых областей, таких как классификация текстов, часто необходимо выполнить и выбор факторов (feature selection) (для классификации текстов - это слова в тексте), иначе модель будет слишком большая, что приведет к увеличенному потреблению ресурсов и замедлениям при тренировке моделей;извлечение данных - как мы выделяем нужные нам факторы. Например, при работе с текстовыми данными, нам может быть необходимо привести все входные данные к одной и той же кодировке, или необходимо выделить только определенную часть данных. Например, при анализе почтового трафика в поисках спама, мы можем игнорировать некоторые заголовки;анализ полученных результатов - еще одна трудоемкая часть. Существуют разные методы оценки качества моделей, зависящие от типа: классификация, кластеризация и т.п., но основная работа приходится на то чтобы понять откуда возникают фальшивые срабатывания и т.п. По результатам анализа может понадобиться настройка параметров моделей, изменение набора тренинговых данных, анализ влияния различных факторов и т.п.;настройка параметров модели. Многие алгоритмы имеют набор параметров которые могут влиять на качество моделей. Нет универсального набора параметров который бы подходил ко всем задачам, поэтому обычно производят построение моделей для диапазонов значений, и выбирают параметры приведшие к построению наилучшей модели. Остальные модели тоже могут принести пользу - например, все построенные модели могут использоваться для построения мета-модели, которая позволит получить лучшее качество чем одна модель;деплоймент моделей в эксплуатацию. Сюда входит: обеспечение беспрерывной работы системы, проверку результатов на реальных данных и т.п.На практике, лишь в небольшом количестве проектов возникает необходимость в новых алгоритмах или реализации существующих алгоритмов с нуля. В большинстве своем, практически всегда используются уже готовые библиотеки и фреймворки, такие как Scikit-Learn для Python, Apache Mahout, Apache Spark ML, H2O, XGBoost, библиотеки для R, и многие другие - эти библиотеки разрабатываются большими коллективами, протестированны для разных задач, и большая часть ошибок уже исправлена. Имея на руках готовые данные, и понимая применимость того или иногда алгоритма, с помощью этих библиотек можно быстро построить модели, оценить их применимость к вашей задаче, и принять решение о реализации.
Мои впечатления на эту тему совпадают с фразой и иллюстрацией из интересной статьи Hidden Technical Debt in Machine Learning Systems опубликованной сотрудниками Google: "It may be surprising to the academic community to know that only a tiny fraction of the code in many ML systems is actually devoted to learning or prediction (Для научных сотрудников может быть удивительным, что только мала часть кода во многих системах построенных на алгоритмах машинного обучения, в действительности относится к обучению или предсказанию)".
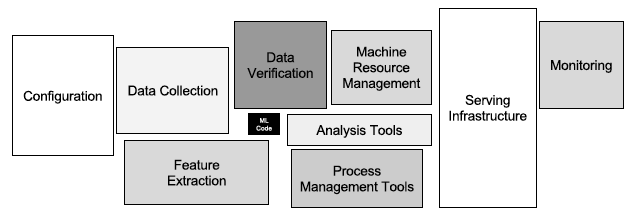
* * *В данном посте я пытался сформулировать свой опыт полученный при реализации конкретных проектов. В следующих постах я попытаюсь раскрыть те или иные пункты более подробно (насколько это не противоречит моему рабочему контракту :-). Я буду очень благодарен комментариям от моих читателей - может быть что-то описано не совсем ясно, тогда я постараюсь дополнить этот пост.


date newest »
newest »



Ну одно из преимуществ - то, что DL может найти сложные комбинации факторов, про которые ты мог и не подумать. Но сложность тренировки, делают эту задачу тоже не особо тривиальной.
Я думаю что традиционные модели будут еще долго жить, и эксперты будут нужны - все равно без знания экспертной области ты не сможешь правильно выбрать данные - не везде получается просто бросить сырые данные и получить результат.