
Alex Ott's Blog
June 1, 2016
Заметки о практическом машинном обучении
Данный пост описывает мои личные наблюдения собранные во время работы над практической реализации задач решаемых при помощи машинного обучения (machine learning, ML). Данный топик всегда интересовал меня, наряду с другими областями, такими как обработка естественного языка (natural language processing, NLP), data mining, и имеющих к ним некоторое отношение технологий big data. Хотя я имею некоторый теоретический бэкграунд, достаточный для понимания применимости того или иного алгоритма, но все эти области интересуют меня в первую очередь с практической точки зрения.
Первый опыт практического применения машинного обучения я получил 2002-2003 годах, после выхода статьи Paul Graham Plan for Spam, которая описывала простой алгоритм для классификации спамерских почтовых сообщений. Простота алгоритма сподвигнула нашу группу, работающую над продуктом для фильтрации почтового трафика "Дозор-Джет, на написание соответствующего модуля для нашей системы. При реализации этого модуля мы первый раз наткнулись на тот факт, что основная сложность и трудоемкость системы не в алгоритме, а в сопутствующих вещах - собирании и очистке данных для тренировки моделей, анализе результатов, исправлении фальшивых срабатываний и т.п.
Позже, когда я стал работать в McAfee/Intel Security, я продолжал эксперементировать с различными алгоритмами и библиотеками, плюс получил большие теоретические знания благодаря онлайн курсам: ML Class (Andrew Ng) & AI Class (Peter Norwig & Sebastian Thrun), плюс последующие классы на Coursera. 2 года назад я перешел в новую группу, которая работает над применением технологий машинного обучения для задач информационной безопасности, что позволило мне получить больше практического опыта в этой области. На основании этого опыта, я и решил написать этот пост.
Как получить хорошие результаты при использовании машинного обученияРезультат применения методов машинного обучения к различным задачам зависит от многих факторов, включая:
Понимание того, какую проблему мы хотим решить. Это достаточно важный пункт - зная о том, какую задачу мы хотим решить, мы имеем информацию об ограничениях накладываемых на конкретные алгоритмы (потребление ресурсов, скорость работы, и т.п.), понимаем насколько критичны ошибки при применении алгоритма, как решение задачи влияет на наш бизнес, и т.д. Часто, "достаточно хорошее", но дешевое решение может быть предпочтительней "наилучшего", но очень дорогого с точки зрения разработки, ресурсов и т.п. (хороший пример этого - история Netflix prize, когда выигравший алгоритм так и не был реализован, а компания остановился на чуть-чуть худшем решении которое было дешевле в реализации);Хорошее знание предметной области. На мой взгляд - это важнейший фактор успеха проекта. Без знания предметной области очень трудно (если вообще возможно) построить хорошую модель. Хорошее знание предметной области позволяет сконцентрироваться на ключевых факторах (или их комбинациях) на базе которых будет построена модель, игнорировать ненужные данные, использование которых не даст выигрыша в качестве (или вообще приведет к деградации качества), выбрать правильные методы сбора, извлечения и кодирования данных, оценить применимость того или иного алгоритма, и т.п.;Наличие хорошей таксономии для задач классификации. В таких задачах необходимо отнести входные данные (текст, или что-то другое) к одному (или нескольким) предопределенным классам. В некоторых случаях, таксономии уже определены, и в задачу проекта может входить построение решения которое будет использовать эту таксономию. И иногда, существующие таксономии не совсем удобно применять с алгоритмами машинного обучения. Например, если имеется несколько "близких" друг к другу классификаций - в этом случае, алгоритмы классификации делают ошибки относя входные данные к "родственным" классам, хотя это не всегда правильно. Например, если вы имеете класс "Спорт" и класс "Азартные игры", может быть достаточно тяжело различить сайты которые обсуждают результаты футбольных матчей от сайтов которые дают советы по ставкам на футбольные матчи;Понимание применимости того или иного алгоритма к классу задач. Сейчас не нужно быть кандидатом наук для применения машинного обучения в практиеческих задачх. Но необходимо иметь понимание того, какие классы алгоритмов существуют, к каким задачам они могут применяться, требования к ресурсам, чувствительность к качеству тренировочных данных, и т.д. (В настоящее время существует огромное количество информации на эту тему - онлайн курсы, книги, документация к библиотекам и т.д., так что это только вопрос времени на ознакомление). Очень часто, наилучший результат приносят не индивидуальные алгоритмы, а алгоритмы основанные на ансамблях из разных моделей, каждая из которых сама по себе дает "средний" результат, например, Random Forest, различные реализации Boosted Trees, и т.д.;Применяемые методы сбора, извлечения и кодирования данных. Чистота и баланс данных. Для разных задач существуют различные методы сбора данных, но основная цель - получить качественный набор тренировочных данных, по возможности не содержащих некоректные данные (хотя это очень дорогое удовольствие для больших объемов данных). В некоторых случаях, при сборе данных необходимо также соблюдать баланс, чтобы объем данных одного класса не превосходил объем данных других классов (хотя существуют некоторые методы решения этой проблемы при построении моделей);Выделение ключевых факторов на базе которых будет построена модель. Также крайне важный фактор влияющий на качество модели - включение лишних факторов в модель может ухудшить ее качество или увеличить потребление ресурсов при построении модели. Также важную роль часто играет применение не индивидуальных факторов, а комбинаций разных независимых факторов;Отсутствие разделения на "разработчиков" и "ученых". Это больше организационный фактор, но он также важен. Иногда бывает, когда "ученые" и "разрабочики" относятся к совершенно разным группам, имеющим очень слабую связь. В таких случаях, при реализации проекта иногда возникает ситуация, когда "ученые" решают в пользу того или иного алгоритма, которые показывает очень хорошие результаты в лабораторых условиях, но который очень тяжело применять в реальной обстановке. Например, он очень требователен к ресурсам, тяжел в реализации, очень медленный и т.д. Лучше избегать такого разделения и позволить всем группам вместе работать над проектом с самого начала.Машинное обучение: теория и практика…Многие люди, не знакомые близко с машинным обучением, когда слышат этот термин, представляют себе листы бумаги исписанные формулами, какой-нибудь заумный код, и т.п. В реальности же, основная трудоемкость таких проектов часто приходится не на реализацию алгоритмов (существует огромное количество готовых библиотек), а на аналитические и инженерные задачи:
сбор и проверка данных. Это одна из самых трудоемких частей. Для этих задач существуют готовые библиотеки и утилиты, но все равно, иногда возникает необходимость в написании чего-то специального. После сбора данных, необходимо убедиться в том что мы действительно собрали правильные данные. Например, если вы занимаетесь классификацией веб страниц, то может возникнуть ситуация, когда содержимое сайта не соотвествует той классификации которая была ему когда-то присвоена - ПО сайта может возвращать сообщение об ошибке, сайт может сменить владельца, он может быть хакнут и помимо нормального содержимого он будет содержать какой-то другой текст (например, рекламу виагры, или порно-сайтов). Для проверки данных часто возникает необходимость в написании специализированных утилит, кросс-проверке данных и т.п.;анализ и выбор факторов (features) которые войдут в модель. Это одна из самых важных частей работы - необходимо понять, какие из факторов являются основными для получения качественных моделей. Для этого необходимо хорошо понимать предметную область, поскольку зачастую качество моделей зависит не от единичных факторов, а, например, от их комбинаций. Для некоторых областей, таких как классификация текстов, часто необходимо выполнить и выбор факторов (feature selection) (для классификации текстов - это слова в тексте), иначе модель будет слишком большая, что приведет к увеличенному потреблению ресурсов и замедлениям при тренировке моделей;извлечение данных - как мы выделяем нужные нам факторы. Например, при работе с текстовыми данными, нам может быть необходимо привести все входные данные к одной и той же кодировке, или необходимо выделить только определенную часть данных. Например, при анализе почтового трафика в поисках спама, мы можем игнорировать некоторые заголовки;анализ полученных результатов - еще одна трудоемкая часть. Существуют разные методы оценки качества моделей, зависящие от типа: классификация, кластеризация и т.п., но основная работа приходится на то чтобы понять откуда возникают фальшивые срабатывания и т.п. По результатам анализа может понадобиться настройка параметров моделей, изменение набора тренинговых данных, анализ влияния различных факторов и т.п.;настройка параметров модели. Многие алгоритмы имеют набор параметров которые могут влиять на качество моделей. Нет универсального набора параметров который бы подходил ко всем задачам, поэтому обычно производят построение моделей для диапазонов значений, и выбирают параметры приведшие к построению наилучшей модели. Остальные модели тоже могут принести пользу - например, все построенные модели могут использоваться для построения мета-модели, которая позволит получить лучшее качество чем одна модель;деплоймент моделей в эксплуатацию. Сюда входит: обеспечение беспрерывной работы системы, проверку результатов на реальных данных и т.п.На практике, лишь в небольшом количестве проектов возникает необходимость в новых алгоритмах или реализации существующих алгоритмов с нуля. В большинстве своем, практически всегда используются уже готовые библиотеки и фреймворки, такие как Scikit-Learn для Python, Apache Mahout, Apache Spark ML, H2O, XGBoost, библиотеки для R, и многие другие - эти библиотеки разрабатываются большими коллективами, протестированны для разных задач, и большая часть ошибок уже исправлена. Имея на руках готовые данные, и понимая применимость того или иногда алгоритма, с помощью этих библиотек можно быстро построить модели, оценить их применимость к вашей задаче, и принять решение о реализации.
Мои впечатления на эту тему совпадают с фразой и иллюстрацией из интересной статьи Hidden Technical Debt in Machine Learning Systems опубликованной сотрудниками Google: "It may be surprising to the academic community to know that only a tiny fraction of the code in many ML systems is actually devoted to learning or prediction (Для научных сотрудников может быть удивительным, что только мала часть кода во многих системах построенных на алгоритмах машинного обучения, в действительности относится к обучению или предсказанию)".
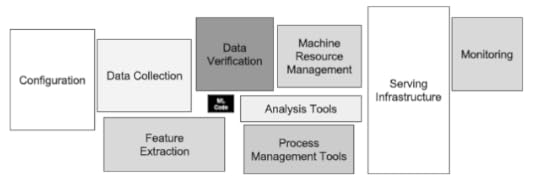
* * *В данном посте я пытался сформулировать свой опыт полученный при реализации конкретных проектов. В следующих постах я попытаюсь раскрыть те или иные пункты более подробно (насколько это не противоречит моему рабочему контракту :-). Я буду очень благодарен комментариям от моих читателей - может быть что-то описано не совсем ясно, тогда я постараюсь дополнить этот пост.
Первый опыт практического применения машинного обучения я получил 2002-2003 годах, после выхода статьи Paul Graham Plan for Spam, которая описывала простой алгоритм для классификации спамерских почтовых сообщений. Простота алгоритма сподвигнула нашу группу, работающую над продуктом для фильтрации почтового трафика "Дозор-Джет, на написание соответствующего модуля для нашей системы. При реализации этого модуля мы первый раз наткнулись на тот факт, что основная сложность и трудоемкость системы не в алгоритме, а в сопутствующих вещах - собирании и очистке данных для тренировки моделей, анализе результатов, исправлении фальшивых срабатываний и т.п.
Позже, когда я стал работать в McAfee/Intel Security, я продолжал эксперементировать с различными алгоритмами и библиотеками, плюс получил большие теоретические знания благодаря онлайн курсам: ML Class (Andrew Ng) & AI Class (Peter Norwig & Sebastian Thrun), плюс последующие классы на Coursera. 2 года назад я перешел в новую группу, которая работает над применением технологий машинного обучения для задач информационной безопасности, что позволило мне получить больше практического опыта в этой области. На основании этого опыта, я и решил написать этот пост.
Как получить хорошие результаты при использовании машинного обученияРезультат применения методов машинного обучения к различным задачам зависит от многих факторов, включая:
Понимание того, какую проблему мы хотим решить. Это достаточно важный пункт - зная о том, какую задачу мы хотим решить, мы имеем информацию об ограничениях накладываемых на конкретные алгоритмы (потребление ресурсов, скорость работы, и т.п.), понимаем насколько критичны ошибки при применении алгоритма, как решение задачи влияет на наш бизнес, и т.д. Часто, "достаточно хорошее", но дешевое решение может быть предпочтительней "наилучшего", но очень дорогого с точки зрения разработки, ресурсов и т.п. (хороший пример этого - история Netflix prize, когда выигравший алгоритм так и не был реализован, а компания остановился на чуть-чуть худшем решении которое было дешевле в реализации);Хорошее знание предметной области. На мой взгляд - это важнейший фактор успеха проекта. Без знания предметной области очень трудно (если вообще возможно) построить хорошую модель. Хорошее знание предметной области позволяет сконцентрироваться на ключевых факторах (или их комбинациях) на базе которых будет построена модель, игнорировать ненужные данные, использование которых не даст выигрыша в качестве (или вообще приведет к деградации качества), выбрать правильные методы сбора, извлечения и кодирования данных, оценить применимость того или иного алгоритма, и т.п.;Наличие хорошей таксономии для задач классификации. В таких задачах необходимо отнести входные данные (текст, или что-то другое) к одному (или нескольким) предопределенным классам. В некоторых случаях, таксономии уже определены, и в задачу проекта может входить построение решения которое будет использовать эту таксономию. И иногда, существующие таксономии не совсем удобно применять с алгоритмами машинного обучения. Например, если имеется несколько "близких" друг к другу классификаций - в этом случае, алгоритмы классификации делают ошибки относя входные данные к "родственным" классам, хотя это не всегда правильно. Например, если вы имеете класс "Спорт" и класс "Азартные игры", может быть достаточно тяжело различить сайты которые обсуждают результаты футбольных матчей от сайтов которые дают советы по ставкам на футбольные матчи;Понимание применимости того или иного алгоритма к классу задач. Сейчас не нужно быть кандидатом наук для применения машинного обучения в практиеческих задачх. Но необходимо иметь понимание того, какие классы алгоритмов существуют, к каким задачам они могут применяться, требования к ресурсам, чувствительность к качеству тренировочных данных, и т.д. (В настоящее время существует огромное количество информации на эту тему - онлайн курсы, книги, документация к библиотекам и т.д., так что это только вопрос времени на ознакомление). Очень часто, наилучший результат приносят не индивидуальные алгоритмы, а алгоритмы основанные на ансамблях из разных моделей, каждая из которых сама по себе дает "средний" результат, например, Random Forest, различные реализации Boosted Trees, и т.д.;Применяемые методы сбора, извлечения и кодирования данных. Чистота и баланс данных. Для разных задач существуют различные методы сбора данных, но основная цель - получить качественный набор тренировочных данных, по возможности не содержащих некоректные данные (хотя это очень дорогое удовольствие для больших объемов данных). В некоторых случаях, при сборе данных необходимо также соблюдать баланс, чтобы объем данных одного класса не превосходил объем данных других классов (хотя существуют некоторые методы решения этой проблемы при построении моделей);Выделение ключевых факторов на базе которых будет построена модель. Также крайне важный фактор влияющий на качество модели - включение лишних факторов в модель может ухудшить ее качество или увеличить потребление ресурсов при построении модели. Также важную роль часто играет применение не индивидуальных факторов, а комбинаций разных независимых факторов;Отсутствие разделения на "разработчиков" и "ученых". Это больше организационный фактор, но он также важен. Иногда бывает, когда "ученые" и "разрабочики" относятся к совершенно разным группам, имеющим очень слабую связь. В таких случаях, при реализации проекта иногда возникает ситуация, когда "ученые" решают в пользу того или иного алгоритма, которые показывает очень хорошие результаты в лабораторых условиях, но который очень тяжело применять в реальной обстановке. Например, он очень требователен к ресурсам, тяжел в реализации, очень медленный и т.д. Лучше избегать такого разделения и позволить всем группам вместе работать над проектом с самого начала.Машинное обучение: теория и практика…Многие люди, не знакомые близко с машинным обучением, когда слышат этот термин, представляют себе листы бумаги исписанные формулами, какой-нибудь заумный код, и т.п. В реальности же, основная трудоемкость таких проектов часто приходится не на реализацию алгоритмов (существует огромное количество готовых библиотек), а на аналитические и инженерные задачи:
сбор и проверка данных. Это одна из самых трудоемких частей. Для этих задач существуют готовые библиотеки и утилиты, но все равно, иногда возникает необходимость в написании чего-то специального. После сбора данных, необходимо убедиться в том что мы действительно собрали правильные данные. Например, если вы занимаетесь классификацией веб страниц, то может возникнуть ситуация, когда содержимое сайта не соотвествует той классификации которая была ему когда-то присвоена - ПО сайта может возвращать сообщение об ошибке, сайт может сменить владельца, он может быть хакнут и помимо нормального содержимого он будет содержать какой-то другой текст (например, рекламу виагры, или порно-сайтов). Для проверки данных часто возникает необходимость в написании специализированных утилит, кросс-проверке данных и т.п.;анализ и выбор факторов (features) которые войдут в модель. Это одна из самых важных частей работы - необходимо понять, какие из факторов являются основными для получения качественных моделей. Для этого необходимо хорошо понимать предметную область, поскольку зачастую качество моделей зависит не от единичных факторов, а, например, от их комбинаций. Для некоторых областей, таких как классификация текстов, часто необходимо выполнить и выбор факторов (feature selection) (для классификации текстов - это слова в тексте), иначе модель будет слишком большая, что приведет к увеличенному потреблению ресурсов и замедлениям при тренировке моделей;извлечение данных - как мы выделяем нужные нам факторы. Например, при работе с текстовыми данными, нам может быть необходимо привести все входные данные к одной и той же кодировке, или необходимо выделить только определенную часть данных. Например, при анализе почтового трафика в поисках спама, мы можем игнорировать некоторые заголовки;анализ полученных результатов - еще одна трудоемкая часть. Существуют разные методы оценки качества моделей, зависящие от типа: классификация, кластеризация и т.п., но основная работа приходится на то чтобы понять откуда возникают фальшивые срабатывания и т.п. По результатам анализа может понадобиться настройка параметров моделей, изменение набора тренинговых данных, анализ влияния различных факторов и т.п.;настройка параметров модели. Многие алгоритмы имеют набор параметров которые могут влиять на качество моделей. Нет универсального набора параметров который бы подходил ко всем задачам, поэтому обычно производят построение моделей для диапазонов значений, и выбирают параметры приведшие к построению наилучшей модели. Остальные модели тоже могут принести пользу - например, все построенные модели могут использоваться для построения мета-модели, которая позволит получить лучшее качество чем одна модель;деплоймент моделей в эксплуатацию. Сюда входит: обеспечение беспрерывной работы системы, проверку результатов на реальных данных и т.п.На практике, лишь в небольшом количестве проектов возникает необходимость в новых алгоритмах или реализации существующих алгоритмов с нуля. В большинстве своем, практически всегда используются уже готовые библиотеки и фреймворки, такие как Scikit-Learn для Python, Apache Mahout, Apache Spark ML, H2O, XGBoost, библиотеки для R, и многие другие - эти библиотеки разрабатываются большими коллективами, протестированны для разных задач, и большая часть ошибок уже исправлена. Имея на руках готовые данные, и понимая применимость того или иногда алгоритма, с помощью этих библиотек можно быстро построить модели, оценить их применимость к вашей задаче, и принять решение о реализации.
Мои впечатления на эту тему совпадают с фразой и иллюстрацией из интересной статьи Hidden Technical Debt in Machine Learning Systems опубликованной сотрудниками Google: "It may be surprising to the academic community to know that only a tiny fraction of the code in many ML systems is actually devoted to learning or prediction (Для научных сотрудников может быть удивительным, что только мала часть кода во многих системах построенных на алгоритмах машинного обучения, в действительности относится к обучению или предсказанию)".
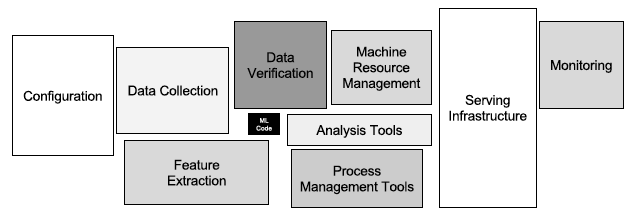
* * *В данном посте я пытался сформулировать свой опыт полученный при реализации конкретных проектов. В следующих постах я попытаюсь раскрыть те или иные пункты более подробно (насколько это не противоречит моему рабочему контракту :-). Я буду очень благодарен комментариям от моих читателей - может быть что-то описано не совсем ясно, тогда я постараюсь дополнить этот пост.


January 11, 2013
Готовится перевод "Clojure Programming"
Издательство "ДМК-Пресс" продолжает серию переводов книг про новые языки программирования, и следующая вещь в списке - "Clojure Programming". Перевод уже начался, и они ищут людей которые помогут с технической вычиткой перевода. Если кому-то интересно, то пишите на dm at dmk-press.ru.
December 3, 2012
Переводы книжек на тему ФП...
Я регулярно общаюсь с издательством ДМК-Пресс, которое в последнее время занимается изданием переводов книг по функциональному программированию и языкам ФП.
В данный момент они занимаются переводом "Scala for Impatient" и им нужны люди которые бы могли сделать техническую вычитку. Если кому интересно, то напишите Дмитрию Мовчану на dm at dmk-press.ru - я сам не знаю как это дело будет организовано...
Они также заинтересованы в издании перевода Practical Common Lisp, который находится в подвешенном состоянии уже давно (надо доперевести 1.5 главы и пройтись по тексту, вычитывая). Издательство приобрело права на издание книги в России, и обещает напечатать книгу по себестоимости. Если кто может принять участие в этом проекте, напишите мне, я выдам .git-репозиторий с текстом в формате LaTeX (или залить это дело на github?). У меня честно говоря совсем нет свободного времени довести PCL до ума.

В данный момент они занимаются переводом "Scala for Impatient" и им нужны люди которые бы могли сделать техническую вычитку. Если кому интересно, то напишите Дмитрию Мовчану на dm at dmk-press.ru - я сам не знаю как это дело будет организовано...
Они также заинтересованы в издании перевода Practical Common Lisp, который находится в подвешенном состоянии уже давно (надо доперевести 1.5 главы и пройтись по тексту, вычитывая). Издательство приобрело права на издание книги в России, и обещает напечатать книгу по себестоимости. Если кто может принять участие в этом проекте, напишите мне, я выдам .git-репозиторий с текстом в формате LaTeX (или залить это дело на github?). У меня честно говоря совсем нет свободного времени довести PCL до ума.
October 30, 2012
Новая версия статьи про CEDET
Только что залил на сайт новую версию своей статьи про настройку CEDET. Я также оставил доступной старую версию статьи, но в виде отдельной страницы.
Новая версия описывает новую схему расположения исходного кода, а также новый способ активации под-режимов, так что статья теперь применима и к версии из bzr, и к версии идущей в составе GNU Emacs (после того как выпустят новую его версию).
Кроме того, я добавил небольшое описание того, как настроить связку CEDET + Java, а также небольшое описание настройки дополнений через auto-complete.
Вместо моего конфига, который очень уж сильно замусорен, теперь лучше воспользоваться отдельным конфигом.
P.S. кстати, в последних снапшотах, CEDET умеет находить проекты Maven, и получать информацию о classpath прямо из них, так что теперь работает и дополнение имен для классов из сторонних библиотек. Например, вот так (Это дополнение при работе с кодом Apache Tika):
P.P.S. If you found error, or typo - please write comment on page, or fork source code on github (it's enough to fix only .muse file), and create pull request :-)
Новая версия описывает новую схему расположения исходного кода, а также новый способ активации под-режимов, так что статья теперь применима и к версии из bzr, и к версии идущей в составе GNU Emacs (после того как выпустят новую его версию).
Кроме того, я добавил небольшое описание того, как настроить связку CEDET + Java, а также небольшое описание настройки дополнений через auto-complete.
Вместо моего конфига, который очень уж сильно замусорен, теперь лучше воспользоваться отдельным конфигом.
P.S. кстати, в последних снапшотах, CEDET умеет находить проекты Maven, и получать информацию о classpath прямо из них, так что теперь работает и дополнение имен для классов из сторонних библиотек. Например, вот так (Это дополнение при работе с кодом Apache Tika):
P.P.S. If you found error, or typo - please write comment on page, or fork source code on github (it's enough to fix only .muse file), and create pull request :-)
September 25, 2012
Выступление про Clojure на ITSea 2012
На прошлой неделе я рассказывал про Clojure на небольшой конференции ITSea (совмещенной с купанием в море и т.п. :-), и затем еще давал небольшой мастер-класс на тему практического использования Clojure. Слайды доступны на slideshare (а вот записи выступления к сожалению не было):
Данный постинг является дополнением к этим слайдам, и содержит ссылки на разные ресурсы, упоминавшиеся в рассказе:
Сайт языка
Список доступных книг про Clojure (разделы про конкретные языки в обзоре литературы по ФП)
Введение в Clojure на русском языке
Список видео-лекций и презентаций про Clojure
Planet Clojure - аггрегатор блогов
Getting started with Clojure - описание первых шагов, включая установку и настройку средств разработки
Интерактивные ресурсы/учебники: 4Clojure, TryClojure, Himera, labrepl
Списки рассылки: clojure, clojure-russian
IDE/редактора (остальные редактора/IDE описаны в подразделах Getting Started): Eclipse, IntelliJ IDEA
Средства сборки: поддержка Clojure в Maven, Leiningen
Библиотеки/фреймворки:
Web: Ring, Compojure, Noir, Hiccup, lein-ring, ClojureScript, ClojureScript One, lein-cljsbuild
SQL: Korma, clojure.java.jdbc
NoSQL: Monger (MongoDB), Clutch (CouchDB), clojure-hbase-schemas (HBase)
GUI: Seesaw
core.logic
Contrib libraries
Внутреннее устройство persistent коллекций: вектора, отображения (maps)


Данный постинг является дополнением к этим слайдам, и содержит ссылки на разные ресурсы, упоминавшиеся в рассказе:
Сайт языка
Список доступных книг про Clojure (разделы про конкретные языки в обзоре литературы по ФП)
Введение в Clojure на русском языке
Список видео-лекций и презентаций про Clojure
Planet Clojure - аггрегатор блогов
Getting started with Clojure - описание первых шагов, включая установку и настройку средств разработки
Интерактивные ресурсы/учебники: 4Clojure, TryClojure, Himera, labrepl
Списки рассылки: clojure, clojure-russian
IDE/редактора (остальные редактора/IDE описаны в подразделах Getting Started): Eclipse, IntelliJ IDEA
Средства сборки: поддержка Clojure в Maven, Leiningen
Библиотеки/фреймворки:
Web: Ring, Compojure, Noir, Hiccup, lein-ring, ClojureScript, ClojureScript One, lein-cljsbuild
SQL: Korma, clojure.java.jdbc
NoSQL: Monger (MongoDB), Clutch (CouchDB), clojure-hbase-schemas (HBase)
GUI: Seesaw
core.logic
Contrib libraries
Внутреннее устройство persistent коллекций: вектора, отображения (maps)
June 10, 2012
Вышел GNU Emacs 24.1!
После длительной разработки, была выпущена новая версия GNU Emacs - 24.1. Среди основных изменений в данной версии можно отметить следующие:
система пакетов, которая позволяет скачивать и устанавливать пакеты из внешних источников - как официальных, так и стороннихподдержка отображения и редактирования текстов на языках, где текст пишется справа-налево поддержка lexical scoping в Emacs Lispулучшения в системе дополнений (completion) - большинство пакетов теперь используют одинаковый метод показа дополненийвстроенная поддержка тем оформления улучшения в интеграции с внешними библиотеками - GTK+3, ImageMagic, GNU TLS, etc.Более подробную информацию можно найти в поставке GNU Emacs (файл etc/NEWS) и в статьях, перечисленных на странице wikemacs.
система пакетов, которая позволяет скачивать и устанавливать пакеты из внешних источников - как официальных, так и стороннихподдержка отображения и редактирования текстов на языках, где текст пишется справа-налево поддержка lexical scoping в Emacs Lispулучшения в системе дополнений (completion) - большинство пакетов теперь используют одинаковый метод показа дополненийвстроенная поддержка тем оформления улучшения в интеграции с внешними библиотеками - GTK+3, ImageMagic, GNU TLS, etc.Более подробную информацию можно найти в поставке GNU Emacs (файл etc/NEWS) и в статьях, перечисленных на странице wikemacs.
June 3, 2012
Впечатления о курсе "Natural Language Processing"
Продолжая традицию постоянного обучения, я не смог не пройти мимо еще одного из курсов предлагаемых Coursera. После курсов прошедших прошлой осенью, у меня осталось очень хорошее впечатление о них. Среди большого набора новых курсов я выбрал курс Natural Language Processing (NLP) - та тема, которая меня давно интересовала. А на этой неделе я наконец-то получил сертификат об окончании этого курса, и решил написать по свежим следам...
Курс длится 8 недель и преподается двумя известными специлистами в этой области - Dan Jurafsky & Christopher Manning (оба из университета Stanford). В качестве основы для курса взяты две книги: Speech & Language Processing, 2ed и Introduction to Information Retrieval (можно найти и онлайн-версии обоих книг - в виде последних снапшотов перед отравкой в издательство). Так получилось, что обе книги у меня уже были достаточно давно, но все не доходили руки сесть за их чтение. Хочется отметить, что читать книги все-таки требовалось, чтобы лучше понять то, что объяснялось в лекциях.
Каждую неделю необходимо было прослушать примерно 2 часа лекций, ответить на набор вопросов, и выполнить домашнее задание (в виде программы). В качестве языка программирования можно было использовать Java или Python - каждую неделю публиковалось новое задание, которое содержало заготовку кода, куда надо было вписать свое решение. Одним из отличий от осенних курсов было то, что на выполнение заданий отводилось больше времени - две недели (эти сроки иногда увеличивались - в зависимости от сложности задания и технических проблем).
Первые три недели были достаточно простыми - разбирали использование регулярных выражений для NLP, моделирование языков, spell correction и классификацию текстов с помощью Naive Bayes - задания выполнялись достаточно быстро.
А вот недели 4-6 были достаточно сложными - рассматривались maximum entropy модели, вычленение именованных объектов и отношений между ними, part of speech tagging, а также вероятностный парсинг текста. 5-е и 6-е задания были самыми сложными в этом курсе (стоит отметить, что много народу просто пропустило 6-ю домашнюю работу) - необходимо было уметь программировать на достаточно хорошем уровне. Но зато было очень интересно смотреть как твоя программа выдает корректную структуру даже для очень сложных предложений с правильно присвоенными частями речи.
7-е задание было очень легким - надо было запрограммировать индексирование текста и вычисление tf-idf. А вот 8-е, хоть и казалось несложным, но требовало достаточно много времени для доводки регулярных выражений, которые должны были извлекать кусочки информации из входных данных. Времени к сожалению было не особо много, так что я сдал первый работающий вариант, за который получил около 70% от макс. оценки.
В итоге, после прохождения всего курса, я набрал 93% от макс. кол-ва баллов. Также вспомнил/научился как программировать на питоне - языке на котором я писал очень редко, а в основном читал код. И даже применил новые знание на практике, соорудив категоризатор текста на базе HBase/Clojure/Hadoop в виде эксперементального модуля для нашего продукта.
Так что если вам интересны вопросы information retrieval/natural language processing - я очень рекомендую этот курс - он дает очень хорошее представление об этих областях и формирует основу для дальнейшего изучения.

Курс длится 8 недель и преподается двумя известными специлистами в этой области - Dan Jurafsky & Christopher Manning (оба из университета Stanford). В качестве основы для курса взяты две книги: Speech & Language Processing, 2ed и Introduction to Information Retrieval (можно найти и онлайн-версии обоих книг - в виде последних снапшотов перед отравкой в издательство). Так получилось, что обе книги у меня уже были достаточно давно, но все не доходили руки сесть за их чтение. Хочется отметить, что читать книги все-таки требовалось, чтобы лучше понять то, что объяснялось в лекциях.
Каждую неделю необходимо было прослушать примерно 2 часа лекций, ответить на набор вопросов, и выполнить домашнее задание (в виде программы). В качестве языка программирования можно было использовать Java или Python - каждую неделю публиковалось новое задание, которое содержало заготовку кода, куда надо было вписать свое решение. Одним из отличий от осенних курсов было то, что на выполнение заданий отводилось больше времени - две недели (эти сроки иногда увеличивались - в зависимости от сложности задания и технических проблем).
Первые три недели были достаточно простыми - разбирали использование регулярных выражений для NLP, моделирование языков, spell correction и классификацию текстов с помощью Naive Bayes - задания выполнялись достаточно быстро.
А вот недели 4-6 были достаточно сложными - рассматривались maximum entropy модели, вычленение именованных объектов и отношений между ними, part of speech tagging, а также вероятностный парсинг текста. 5-е и 6-е задания были самыми сложными в этом курсе (стоит отметить, что много народу просто пропустило 6-ю домашнюю работу) - необходимо было уметь программировать на достаточно хорошем уровне. Но зато было очень интересно смотреть как твоя программа выдает корректную структуру даже для очень сложных предложений с правильно присвоенными частями речи.
7-е задание было очень легким - надо было запрограммировать индексирование текста и вычисление tf-idf. А вот 8-е, хоть и казалось несложным, но требовало достаточно много времени для доводки регулярных выражений, которые должны были извлекать кусочки информации из входных данных. Времени к сожалению было не особо много, так что я сдал первый работающий вариант, за который получил около 70% от макс. оценки.
В итоге, после прохождения всего курса, я набрал 93% от макс. кол-ва баллов. Также вспомнил/научился как программировать на питоне - языке на котором я писал очень редко, а в основном читал код. И даже применил новые знание на практике, соорудив категоризатор текста на базе HBase/Clojure/Hadoop в виде эксперементального модуля для нашего продукта.
Так что если вам интересны вопросы information retrieval/natural language processing - я очень рекомендую этот курс - он дает очень хорошее представление об этих областях и формирует основу для дальнейшего изучения.
April 15, 2012
Clojure 1.4!
А между тем, незаметно подкрался релиз новой версии языка Clojure - 1.4.
Rich Hickey называет этот релиз в основном maintenance, хотя есть и достаточно крупные изменения:
Расширяемая процедура чтения (reader) - разработчик может указать функцию чтения для своих типов данных. Разработчик должен указать метку для своего типа данных, и соответствующую функцию чтения, и данная функция будет вызвана после того, как следующая (после метки) форма будет считана стандартным reader. Например, можно будет писать вот так: #foo/bar [1 2 3] - в этом случае, после чтения метки, процедура чтения сначала считает форму [1 2 3], а затем вызовет процедуру связанную с данной меткой (если она определена) и передаст ей прочитанные данные. В состав новой версии вошла поддержка чтения двух новых типов - #inst - для времени и даты, и #uuid - для UUID.
Новый синтаксис для доступа к полям записей (унифицировано с ClojureScript) - теперь можно писать (.-field_name record-instance).
Возможность контролировать поведение компилятора Clojure с помощью опций, указанных через переменную *compiler-options*.
Остальные изменения включают в себя добавление новых функций в базовую библиотеку, достаточно много исправлений ошибки, оптимизации производительности.
Полный список изменений можно найти в репозитории. Кроме того, может быть интересным интервью Rich Hickey в котором он рассказывает про некоторые изменения в новой версии.

Rich Hickey называет этот релиз в основном maintenance, хотя есть и достаточно крупные изменения:
Расширяемая процедура чтения (reader) - разработчик может указать функцию чтения для своих типов данных. Разработчик должен указать метку для своего типа данных, и соответствующую функцию чтения, и данная функция будет вызвана после того, как следующая (после метки) форма будет считана стандартным reader. Например, можно будет писать вот так: #foo/bar [1 2 3] - в этом случае, после чтения метки, процедура чтения сначала считает форму [1 2 3], а затем вызовет процедуру связанную с данной меткой (если она определена) и передаст ей прочитанные данные. В состав новой версии вошла поддержка чтения двух новых типов - #inst - для времени и даты, и #uuid - для UUID.
Новый синтаксис для доступа к полям записей (унифицировано с ClojureScript) - теперь можно писать (.-field_name record-instance).
Возможность контролировать поведение компилятора Clojure с помощью опций, указанных через переменную *compiler-options*.
Остальные изменения включают в себя добавление новых функций в базовую библиотеку, достаточно много исправлений ошибки, оптимизации производительности.
Полный список изменений можно найти в репозитории. Кроме того, может быть интересным интервью Rich Hickey в котором он рассказывает про некоторые изменения в новой версии.
December 31, 2011
Итоги года...
Сейчас самое подвести итоги уходящего года, и посмотреть вперед - 2011-й год был достаточно насыщеным, свободного времени практически не было....
получил повышение до Principal разработчика, что добавило задач, но проекты были интересными, и будут новые
достаточно много ездил - в другие страны (англия, голландия, канарские острова) и в германии (по рейну, в Кельн на карнавал, и т.д.)
накатал 2000км на велосипеде, хотя это меньше чем я планировал
достаточно много "книжных" проектов - работал с Manning над "Mahout in Action" & "Tika in Action", наконец-то вышел перевод TaPL в его окончательном варианте
в части open source активность была не особо высокой - обычно в виде небольших патчей для разных проектов
для статей тоже не особо много времени находилось - написал только статью про TDD & Unit testing in C++, и вместе с Дмитрием Бушенко, написали небольшое пособие про Emacs, которое мы планируем в следующем году значительно расширить информацией про CEDET/Semantic для Java и т.п.
много читал, в основном техническую литературу
учился в двух стенфордских классах, что доставило очень большое удовольствие и позволило многому научиться
В следующем году продолжу разбираться с темами, которые мне интересны - machine learning, natural language processing (в том числе возьму и стенфордский класс на эту тему), постараюсь больше писать на разные темы, и более активно учавствовать в open source проектах. И проехать 3000км на велосипеде (надо только его проапгрейдить до шоссейника)...
И хочу поздравить всех моих читателей с Новым, 2012-м годом - пусть он будет успешным и интересным для вас!

получил повышение до Principal разработчика, что добавило задач, но проекты были интересными, и будут новые
достаточно много ездил - в другие страны (англия, голландия, канарские острова) и в германии (по рейну, в Кельн на карнавал, и т.д.)
накатал 2000км на велосипеде, хотя это меньше чем я планировал
достаточно много "книжных" проектов - работал с Manning над "Mahout in Action" & "Tika in Action", наконец-то вышел перевод TaPL в его окончательном варианте
в части open source активность была не особо высокой - обычно в виде небольших патчей для разных проектов
для статей тоже не особо много времени находилось - написал только статью про TDD & Unit testing in C++, и вместе с Дмитрием Бушенко, написали небольшое пособие про Emacs, которое мы планируем в следующем году значительно расширить информацией про CEDET/Semantic для Java и т.п.
много читал, в основном техническую литературу
учился в двух стенфордских классах, что доставило очень большое удовольствие и позволило многому научиться
В следующем году продолжу разбираться с темами, которые мне интересны - machine learning, natural language processing (в том числе возьму и стенфордский класс на эту тему), постараюсь больше писать на разные темы, и более активно учавствовать в open source проектах. И проехать 3000км на велосипеде (надо только его проапгрейдить до шоссейника)...
И хочу поздравить всех моих читателей с Новым, 2012-м годом - пусть он будет успешным и интересным для вас!
December 23, 2011
Про Стэнфордские курсы...
Я как и многие мои знакомые, учавствовал в экспериментальных учебных курсах предложенных Стэнфордским университетом. В виду патологической жадности любви к учебе, записался сразу на два курса Artificial Intelligence (AI) & Machine Leaning (ML), оба на advanced track, что предполагало делание домашних заданий в дополнение к вопросам в ходе лекций. Вчера я получил свой сертификат для AI - 89%, чему я с одной стороны рад, поскольку я смог это сделать, с другой стороны - корю себя за невнимательность и несобранность - было сделано достаточно много глупых ошибок. Сертификат по ML скорее всего придет на той неделе.
Я собирался написать про свои впечатления об обоих курсах, но Lev Walkin меня опередил отличных постом в своем журнале. Мои впечатления полностью совпадают с тем, что он написал - возможность получения немедленного feedback на ML-курсе, позволила гораздо лучше запомнить материал по сравнению с тем что давали на AI. Но стоит отметить, что AI тоже не прошел даром - обзорные лекции по разным темам дали возможность на них посмотреть чуть ближе, и понять что из них будет интересно и применимо.
Оба курса были также хорошей возможностью чуть лучше сконцентрироваться на определенных темах, поскольку домашние работы надо было выполнять в срок. Плюс это дало возможность наконец-то почитать давно купленные книги, например, Artificial Intelligence: A Modern Approach (у меня 2-е, русское издание), купленное много лет назад, и иногда доставаемое с полки для чтения какой-то главы :-)
А в конце января, начнется новая серия курсов, я скорее всего возьму только один - Natural Language Processing (так что я достану из загашников еще пару книжек :-), хотя хочется взять половину из новых курсов, даже 2 курса одновременно - это достаточно затратно по времени, так что буду надеяться что все курсы будут оставаться в открытом доступе и в дальнейшем (по крайней мере, курс по ML будет повторен и в новом семестре).
Я собирался написать про свои впечатления об обоих курсах, но Lev Walkin меня опередил отличных постом в своем журнале. Мои впечатления полностью совпадают с тем, что он написал - возможность получения немедленного feedback на ML-курсе, позволила гораздо лучше запомнить материал по сравнению с тем что давали на AI. Но стоит отметить, что AI тоже не прошел даром - обзорные лекции по разным темам дали возможность на них посмотреть чуть ближе, и понять что из них будет интересно и применимо.
Оба курса были также хорошей возможностью чуть лучше сконцентрироваться на определенных темах, поскольку домашние работы надо было выполнять в срок. Плюс это дало возможность наконец-то почитать давно купленные книги, например, Artificial Intelligence: A Modern Approach (у меня 2-е, русское издание), купленное много лет назад, и иногда доставаемое с полки для чтения какой-то главы :-)
А в конце января, начнется новая серия курсов, я скорее всего возьму только один - Natural Language Processing (так что я достану из загашников еще пару книжек :-), хотя хочется взять половину из новых курсов, даже 2 курса одновременно - это достаточно затратно по времени, так что буду надеяться что все курсы будут оставаться в открытом доступе и в дальнейшем (по крайней мере, курс по ML будет повторен и в новом семестре).

